Partition
We assume that you have already learned what is described in:
If you want to find the right Transformer for your purposes, see Transformers Comparison.
Short Summary
Partition distributes individual input data records among different output ports.
| Component | Same input metadata | Sorted inputs | Inputs | Outputs | Java | CTL |
|---|---|---|---|---|---|---|
| Partition | - | no | 1 | 1-n | yes/no1) | yes/no1) |
Legend
1) Partition can use either transformation or other two attributes (Ranges and/or Partition key). A transformation must be defined unless at least one of these is specified.
Abstract
Partition distributes individual input data records among different output ports.
To distribute data records, user-defined transformation, ranges
of Partition key or RoundRobin algorithm may be
used. Ranges of Partition key are either those
specified in the Ranges attribute or calculated
hash values. It uses a CTL template for Partition
or implements a PartitionFunction interface. Its
methods are listed below. In this component no mapping may be defined
since it does not change input data records. It only distributes
them unchanged among output ports.
![[Tip]](figures/tip.png) | Tip |
|---|---|
Note that you can use the Partition component as a filter similarly to ExtFilter. With the Partition component you can define much more sophisticated filter expressions and distribute input data records among more outputs than 2. Neither Partition nor ExtFilter allow to modify records. |
![[Important]](figures/important.png) | Important |
|---|---|
Partition is high-performance component, thus you cannot modify input and output records - it would result in an error. If you need to do so, consider using Reformat instead. |
Icon

Ports
| Port type | Number | Required | Description | Metadata |
|---|---|---|---|---|
| Input | 0 | yes | For input data records | Any |
| Output | 0 | yes | For output data records | Input 01) |
| 1-N | no | For output data records | Input 01) |
Legend:
1): Metadata can be propagated through this component.
Partition Attributes
| Attribute | Req | Description | Possible values |
|---|---|---|---|
| Basic | |||
| Partition | 1) | Definition of the way how records should be distributed among output ports written in the graph in CTL or Java. | |
| Partition URL | 1) | Name of external file, including path, containing the definition of the way how records should be distributed among output ports written in CTL or Java. | |
| Partition class | 1) | Name of external class defining the way how records should be distributed among output ports. | |
| Ranges | 1),2) | Ranges expressed as a sequence of individual ranges
separated from each other by semicolon. Each individual range
is a sequence of intervals for some set of fields that are
adjacent to each other without any delimiter. It is expressed
also whether the minimum and maximum margin is included to the
interval or not by bracket and parenthesis, respectively.
Example of Ranges:
<1,9)(,31.12.2008);<1,9)<31.12.2008,);<9,)(,31.12.2008);
<9,)<31.12.2008). | |
| Partition key | 1),2) | Key according to which input records are distributed
among different output ports. Expressed as the sequence of
individual input field names separated from each other by
semicolon. Example of Partition key:
first_name;last_name. | |
| Advanced | |||
| Partition source charset | Encoding of external file defining the transformation. | ISO-8859-1 (default) | other encoding | |
| Deprecated | |||
| Locale | Locale to be used when internationalization is set to
true. By default, system value is
used unless value of Locale specified
in the defaultProperties file is uncommented and set to the desired Locale.
For more information on how Locale may be changed in the defaultProperties
see Changing Default CloudConnect Settings. | system value or specified default value (default) | other locale | |
| Use internationalization | By default, no internationalization is used. If set to
true, sorting according national properties
is performed. | false (default) | true | |
Legend:
1): If one of these transformation attributes is specified, both
Ranges and Partition key
will be ignored since they have less priority. Any of these
transformation attributes must use a CTL template for
Partition or implement a
PartitionFunction interface.
See CTL Scripting Specifics or Java Interfaces for Partition (and ClusterPartitioner) for more information.
See also Defining Transformations for detailed information about transformations.
2): If no transformation attribute is defined, Ranges and Partition key are used in one of the following three ways:
Both Ranges and Partition key are set.
The records in which the values of the fields are inside the margins of specified range will be sent to the same output port. The number of the output port corresponds to the order of the range within all values of the fields.
Ranges are not defined. Only Partition key is set.
Records will be distributed among different output ports as described above. Hash values will be calculated and used as margins as if they were specified in Ranges.
Neither Ranges nor Partition key are defined.
RoundRobin algorithm will be used to distribute records among output ports.
CTL Scripting Specifics
When you define any of the three transformation attributes, which is optional, you must specify a transformation that assigns a number of output port to each input record.
For detailed information about CloudConnect Transformation Language see Part XI, CTL - CloudConnect Transformation Language. (CTL is a full-fledged, yet simple language that allows you to perform almost any imaginable transformation.)
CTL scripting allows you to specify custom transformation using the simple CTL scripting language.
Partition uses the following transformation teplate:
CTL Templates for Partition (or ClusterPartitioner)
This transformation template is used in Partition, and ClusterPartitioner.
Once you have written your transformation in CTL, you can also convert it to Java language code by clicking corresponding button at the upper right corner of the tab.
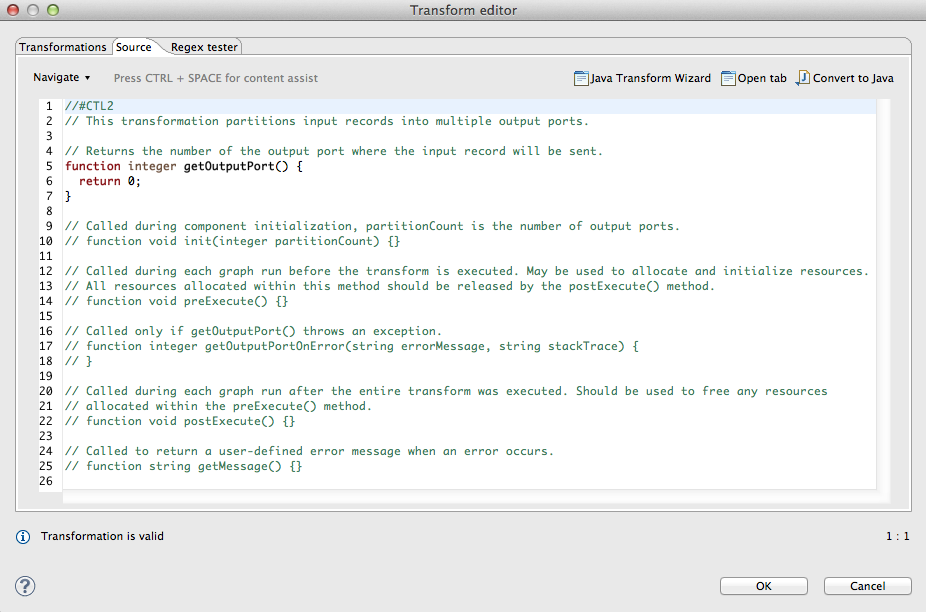
You can open the transformation definition as another tab of a graph (in addition to the Graph and Source tabs of Graph Editor) by clicking corresponding button at the upper right corner of the tab.
Table 55.4. Functions in Partition (or ClusterPartitioner)
| CTL Template Functions | |
|---|---|
| void init() | |
| Required | No |
| Description | Initialize the component, setup the environment, global variables |
| Invocation | Called before processing the first record |
| Returns | void |
| integer getOutputPort() | |
| Required | yes |
| Input Parameters | none |
| Returns | Integer numbers. See Return Values of Transformations for detailed information. |
| Invocation | Called repeatedly for each input record |
| Description | It does not transform the records, it does not change
them nor remove them, it only returns integer numbers.
Each of these returned
numbers is a number of the output port to which individual
record should be sent. In ClusterPartitioner,
these ports are virtual and mean Cluster nodes. If any part of the getOutputPort() function for some output record
causes fail of the getOutputPort() function,
and if user has defined another function (getOutputPortOnError()),
processing continues in this getOutputPortOnError()
at the place where getOutputPort() failed. If getOutputPort() fails
and user has not defined any getOutputPortOnError(),
the whole graph will fail. The getOutputPortOnError() function
gets the information gathered by getOutputPort()
that was get from previously successfully processed code.
Also error message and stack trace are passed to getOutputPortOnError(). |
| Example | function integer getOutputPort() {
switch (expression) {
case const0 : return 0; break;
case const1 : return 1; break;
...
case constN : return N; break;
[default : return N+1;]
}
} |
| integer getOutputPortOnError(string errorMessage, string stackTrace) | |
| Required | no |
| Input Parameters | string errorMessage |
string stackTrace | |
| Returns | Integer numbers. See Return Values of Transformations for detailed information. |
| Invocation | Called if getOutputPort() throws an exception. |
| Description | It does not transform the records, it does not change
them nor remove them, it only returns integer numbers.
Each of these returned
numbers is a number of the output port to which individual
record should be sent. In ClusterPartitioner,
these ports are virtual and mean Cluster nodes. If any part of the getOutputPort() function for some output record
causes fail of the getOutputPort() function,
and if user has defined another function (getOutputPortOnError()),
processing continues in this getOutputPortOnError()
at the place where getOutputPort() failed. If getOutputPort() fails
and user has not defined any getOutputPortOnError(),
the whole graph will fail. The getOutputPortOnError() function
gets the information gathered by getOutputPort()
that was get from previously successfully processed code.
Also error message and stack trace are passed to getOutputPortOnError(). |
| Example | function integer getOutputPortOnError(
string errorMessage,
string stackTrace) {
printErr(errorMessage);
printErr(stackTrace);
} |
| string getMessage() | |
| Required | No |
| Description | Prints error message specified and invocated by user |
| Invocation | Called in any time specified by user
(called only when either getOutputPort() or getOutputPotOnError() returns value less than or equal to -2). |
| Returns | string |
| void preExecute() | |
| Required | No |
| Input parameters | None |
| Returns | void |
| Description | May be used to allocate and initialize resources.
All resources allocated within this function should be released by the postExecute() function. |
| Invocation | Called during each graph run before the transform is executed. |
| void postExecute() | |
| Required | No |
| Input parameters | None |
| Returns | void |
| Description | Should be used to free any resources allocated within the preExecute() function. |
| Invocation | Called during each graph run after the entire transform was executed. |
| Important |
|---|---|
|
![[Warning]](figures/warning.png) | Warning |
|---|---|
Remember that if you do not hold these rules, NPE will be thrown! |
Java Interfaces for Partition (and ClusterPartitioner)
The transformation implements methods of the PartitionFunction interface
and inherits other common methods from the Transform interface.
See Common Java Interfaces.
Following are the methods of
PartitionFunction interface:
void init(int numPartitions,RecordKey partitionKey)Called before
getOutputPort()is used. ThenumPartitionsargument specifies how many partitions should be created. TheRecordKeyargument is the set of fields composing key based on which the partition should be determined.
boolean supportsDirectRecord()Indicates whether partition function supports operation on serialized records /aka direct. Returns
trueifgetOutputPort(ByteBuffer)method can be called.
int getOutputPort(DataRecord record)Returns port number which should be used for sending data out. See Return Values of Transformations for more information about return values and their meaning.
int getOutputPortOnError(Exception exception, DataRecord record)Returns port number which should be used for sending data out. Called only if
getOutputPort(DataRecord)throws an exception.
int getOutputPort(ByteBuffer directRecord)Returns port number which should be used for sending data out. See Return Values of Transformations for more information about return values and their meaning.
int getOutputPortOnError(Exception exception, ByteBuffer directRecord)Returns port number which should be used for sending data out. Called only if
getOutputPort(ByteBuffer)throws an exception.