Chapter 12. HR Example: Connecting multiple datasets together
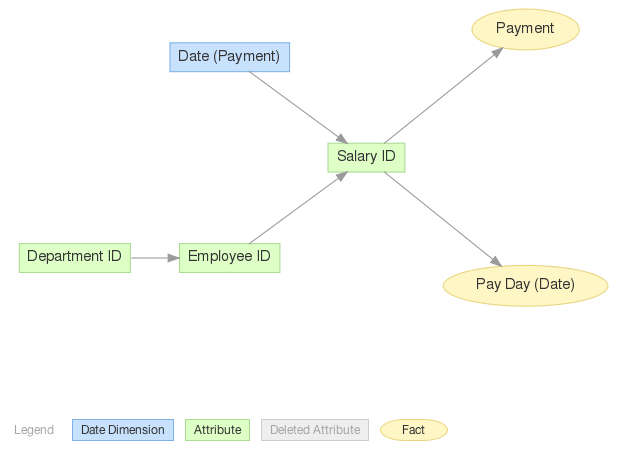
This example shows how to load three connected datasets together. There are three hierarchically connected datasets to load in the HR example: Department -> Employee -> Salary.
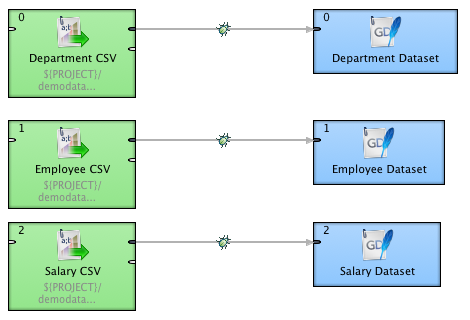
The CloudConnect graph loads all three datasets.
As the datasets are connected, we need to make sure that the datasets are not loaded in parallel but in sequence. We need to first load the Department, then Employee, and finally the Salary dataset. CloudConnect uses so called phases to execute different parts of the graph sequentially. The phase can be assigned to a connected branch of the graph by simple right-clicking at a specific component and selecting the popup menu item.
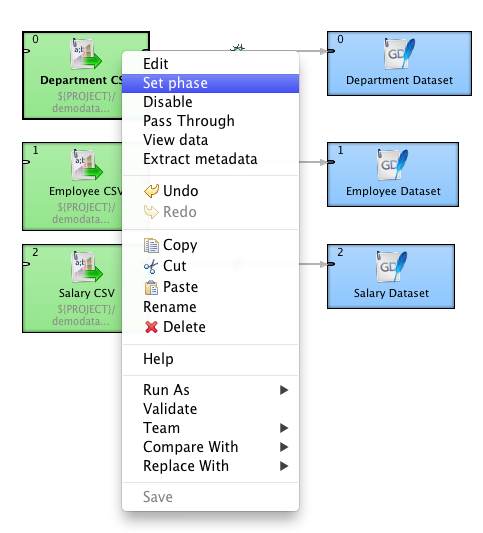
The phase is an integer number. Components with the lower phase execute sooner in the sequence than the components with the higher phase. Note, that the component's phase is indicated as a small number in the top left corner of the component's rectangle.
The Department dataset contains only one attribute called Department ID and one label called Name. In fact this attribute has two textual labels: Department ID and Name. GoodData platform needs to know which of these two labels uniquely identify any Department record to correctly load the data. Lets explain this on a simple example. Lets assume that we want to load the following employee records to the GoodData platform:
Table 12.1. Employee records
| Employee ID | Employee Name | Department ID | Department Name | Salary |
|---|---|---|---|---|
| 1 | John Simons | SW | Sales | $170k |
| 2 | Jeff Nicholson | SE | Sales | $180k |
| 3 | Sarah Robinson | MKTG | Marketing | $220k |
The platform needs to break down these records to two attributes and one fact:
Department attribute is created from the
Department IDandDepartment Namecolumns.Employee attribute is created from the
Employee IDandEmployee Namecolumns.Salary fact is created from the
Salarycolumn.
Now lets look more closely at the Department attribute. The GoodData platform needs to designate one of the Department's columns as primary. Each distinct value of the primary column identifies a record of the attribute. We can choose the Department ID as the primary column and end up with three Department records identified by the values: SW, SE, and MKTG or select the Department Name and end up with only two Department records identified by the values: Sales, and Marketing.
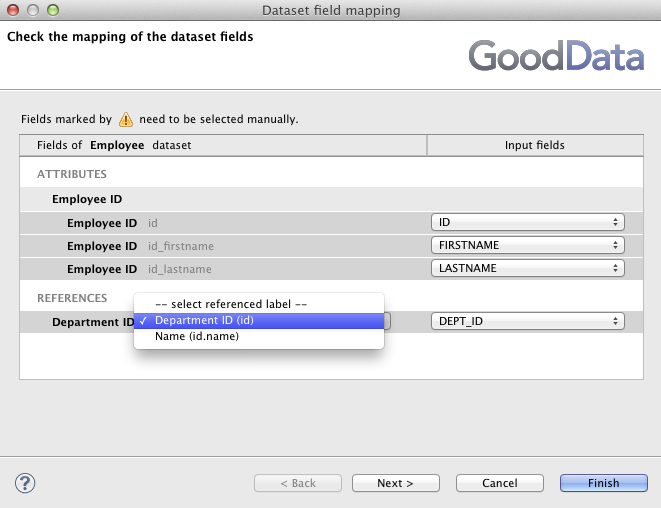
The Field mapping dialog of the GD Dataset Writer component asks for identification of the primary label for all attributes that have more than one label.
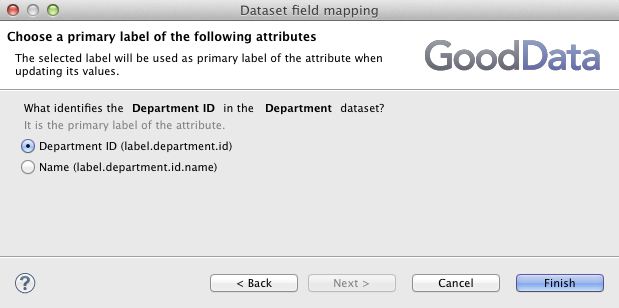
The Employee dataset references the Department dataset in the project's data model. As we saw earlier, the Department dataset has one attribute and two labels Department ID and the Name. So there are two options, how to reference any Department record from an Employee record. The CloudConnect needs to know what label you choose. It first asks you for this label during the Employee metadata creation to give the field that references the Department the right name ( → and select the Employee dataset).
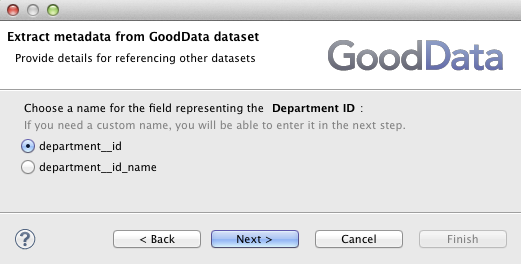
Selection of the correct Department label that is referenced from the Employee records is very important in the Employee's GD Dataset Wizard's Field mapping dialog.