ExtHashJoin
We assume that you have already learned what is described in:
If you want to find the right Joiner for your purposes, see Joiners Comparison.
Short Summary
General purpose joiner, merges potentionally unsorted data from two or more data sources on a common key.
| Component | Same input metadata | Sorted inputs | Slave inputs | Outputs | Output for drivers without slave | Output for slaves without driver | Joining based on equality |
|---|---|---|---|---|---|---|---|
| ExtHashJoin | no | no | 1-n | 1 | no | no | yes |
Abstract
This is a general purpose joiner used in most common situations. It does not require the input be sorted and is very fast as it is processed in memory.
The data attached to the first input port is called the master (as usual in other Joiners). All remaining connected input ports are called slaves. Each master record is matched to all slave records on one or more fields known as the join key. The output is produced by applying a transformation that maps joined inputs to the output. For details, see Joining Mechanics.
This joiner should be avoided in case of large inputs on the slave port. The reason is slave data is cached in the memory.
![[Tip]](figures/tip.png) | Tip |
|---|---|
If you have larger data, consider using the ExtMergeJoin component. If your data sources are unsorted, use a sorting component first (ExtSort, FastSort, or SortWithinGroups). |
Icon
Ports
ExtHashJoin receives data through two or more input ports, each of which may have a different metadata structure.
The joined data is then sent to the single output port.
| Port type | Number | Required | Description | Metadata |
|---|---|---|---|---|
| Input | 0 | yes | Master input port | Any |
| 1 | yes | Slave input port | Any | |
| 2-n | no | Optional slave input ports | Any | |
| Output | 0 | yes | Output port for the joined data | Any |
ExtHashJoin Attributes
| Attribute | Req | Description | Possible values |
|---|---|---|---|
| Basic | |||
| Join key | yes | Key according to which the incoming data flows are joined. See Join key. | |
| Join type | Type of the join. See Join Types. | Inner (default) | Left outer | Full outer | |
| Transform | 1) | Transformation in CTL or Java defined in the graph. | |
| Transform URL | 1) | External file defining the transformation in CTL or Java. | |
| Transform class | 1) | External transformation class. | |
| Allow slave duplicates | If set to true, records with
duplicate key values are allowed. If it is
false, only the first record is used for join. | false (default) | true | |
| Advanced | |||
| Transform source charset | Encoding of external file defining the transformation. | ISO-8859-1 (default) | |
| Hash table size | Initial size of hash table that should be used when joining data flows. If there are more records that should be joined, hash table can be rehashed, however, it slows down the parsing process. See Hash Tables for more information: | 512 (default) | |
| Deprecated | |||
| Error actions | Definition of the action that should be performed when the specified transformation returns some Error code. See Return Values of Transformations. | ||
| Error log | URL of the file to which error messages for specified Error actions should be written. If not set, they are written to Console. | ||
| Left outer | If set to true, left
outer join is performed. By default it is
false. However, this attribute has lower
priority than Join type. If you set both,
only Join type will be applied. | false (default) | true | |
| Full outer | If set to true, full
outer join is performed. By default it is
false. However, this attribute has lower
priority than Join type. If you set both,
only Join type will be applied. | false (default) | true | |
Legend:
1) One of these must be set. These transformation attributes
must be specified. Any of these transformation attributes must use a
common CTL template for Joiners or implement a
RecordTransform interface.
See CTL Scripting Specifics or Java Interfaces for more information.
See also Defining Transformations for detailed information about transformations.
Advanced Description
The Join key attribute is a sequence of mapping expressions for all slaves separated from each other by hash. Each of these mapping expressions is a sequence of field names from master and slave records (in this order) put together using equal sign and separated from each other by semicolon, colon, or pipe.
Order of these mappings must correspond to the order of the slave input ports. If some of these mappings is empty or missing for some of the slave input ports, the mapping of the first slave input port is used instead.
![[Note]](figures/note.png)
Note Different slaves can be joined with the master using different master fields!
Example 56.4. Slave Part of Join Key for ExtHashJoin
$master_field1=$slave_field1;$master_field2=$slave_field2;...;$master_fieldN=$slave_fieldN
If some
$slave_fieldJis missing (in other words, if the subexpression looks like this:$master_fieldJ=), it is supposed to be the same as the$master_fieldJ.If some
$master_fieldKis missing,$master_fieldKfrom the first port is used.
Example 56.5. Join Key for ExtHashJoin
$first_name=$fname;$last_name=$lname#=$lname;$salary=;$hire_date=$hdate
.
Following is the part of Join key for the first slave data source (input port 1):
$first_name=$fname;$last_name=$lname.Thus, the following two fields from the master data flow are used for join with the first slave data source:
$first_nameand$last_name.They are joined with the following two fields from this first slave data source:
$fnameand$lname, respectively.
Following is the part of Join key for the second slave data source (input port 2):
=$lname;$salary=;$hire_date=$hdate.Thus, the following three fields from the master data flow are used for join with the second slave data source:
$last_name(because it is the field which is joined with the$lnamefor the first slave data source),$salary, and$hire_date.They are joined with the following three fields from this second slave data source:
$lname,$salary, and$hdate, respectively. (This slave$salaryfield is expressed using the master field of the same name.)
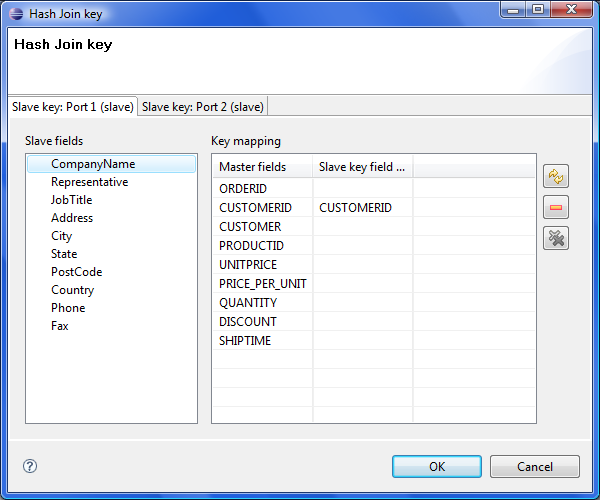
To create the Join key attribute, you must use the Hash Join key wizard. When you click the Join key attribute row, a button appears in this row. By clicking this button you can open the mentioned wizard.
In it, you can see the tabs for all of the slave input ports. In each of the slave tab(s) there are two panes. The Slave fields pane on the left and the Key mapping pane on the right. In the left pane, you can see the list of all the slave field names. In the right pane, you can see two columns: Master fields and Slave key field mapped. The left column contains all field names of the driver input port. If you want to map some slave fields to some driver (master) fields, you must select each of the desired slave fields that should be selected in the left pane by clicking its item, and drag and drop it to the Slave key field mapped column in the right pane at the row of some driver (master) field to which it should be mapped. It must be done for the selected slave fields. And the same process must be repeated for all slave tabs. Note that you can also use the Auto mapping button or other buttons in each tab. Thus, slave fields are mapped to driver (Master) fields according to their names. Note that different slaves can map different number of slave fields to different number of driver (Master) fields.
The component first receives the records incoming through the slave input ports, reads them and creates hash tables from these records. These hash tables must be sufficiently small. After that, for each driver record incoming through the driver input port the component looks up the corresponding records in these hash tables. For every slave input port one hash table is created. The records on the input ports do not need to be sorted. If such record(s) are found, the tuple of the driver record and the slave record(s) from the hash tables are sent to transformation class. The transform method is called for each tuple of the master and its corresponding slave records.
The incoming records do not need to be sorted, but the initialization of the hash tables is time consuming and it may be good to specify how many records can be stored in hash tables. If you decide to specify this attribute, it would be good to set it to the value slightly greater than needed. Nevertheless, for small sets of records it is not necessary to change the default value.
Joining Mechanics
All slave input data is stored in the memory. However, the master data is not. As for memory requirements, you therefore need to consider only the size of your slave data. In consequence, be sure to always set the larger data to the master and smaller inputs as slaves. ExtHashJoin uses in-memory hash tables for storing slave records.
![[Important]](figures/important.png) | Important |
|---|---|
Remember each slave port can be joined with the master using different numbers of various master fields. |
CTL Scripting Specifics
When you define your join attributes you must specify a transformation that maps fields from input data sources to the output. This can be done using the Transformations tab of the Transform Editor. However, you may find that you are unable to specify more advanced transformations using this easist approach. This is when you need to use CTL scripting.
For detailed information about CloudConnect Transformation Language see Part XI, CTL - CloudConnect Transformation Language. (CTL is a full-fledged, yet simple language that allows you to perform almost any imaginable transformation.)
CTL scripting allows you to specify custom field mapping using the simple CTL scripting language.
All Joiners share the same transformation template which can be found in CTL Templates for Joiners.
Java Interfaces
If you define your transformation in Java, it must implement the following interface that is common for all Joiners: