Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses
When you need to load data to a workspace with a specific logical data model (LDM), you have to map all datasets in the workspace LDM to the objects in your data warehouse Output Stage.
The names of the Output Stage objects must follow the specific naming convention at the dataset level and the LDM field level.
To generate SQL commands for creating or updating the Output Stage, see Create the Output Stage based on Your Logical Data Model.
Dataset Level Mapping
If the identifier of a dataset is the following:
dataset.<dataset_name>
then Automated Data Distribution (ADD) v2 for data warehouses expects the following name of the source database object for this dataset in the Output Stage:
<output_stage_prefix>_<dataset_name>
For example, ADD v2 expects that the database object out_person in the Output Stage (out_ is the Output Stage prefix) will be used for populating data into the LDM dataset with the identifier of dataset.person.
LDM Field Level Mapping
The following table shows the mapping of element_type to prefix_type:
| prefix_type | element_type | Description |
|---|---|---|
| a | attr | attribute |
| cp | attr | connection point (anchor) |
| f | fact | fact |
| d | date | date dimension |
| r | reference | |
| l | label |
Attributes, Connection Points, and Facts
If the identifier of an LDM field is the following:
<element_type>.<dataset_name>.<element_name>
then ADD v2 expects the following column name in the mapped database object in the Output Stage:
<prefix_type>__<element_name>
Attribute Labels
If the identifier of an attribute label is the following:
label.<dataset_name>.<attribute_name>.<label_name>
then ADD v2 expects the following column name in the mapped database object in the Output Stage:
l__<attribute_name>__<label_name>
References
If dataset.<dataset1_name> is a dataset referenced from dataset.<dataset2_name>, ADD v2 expects the following:
- The source column for this reference exists in the database object
<dataset2_name>. - The name of the source column is
r__<dataset1_name>.
Example
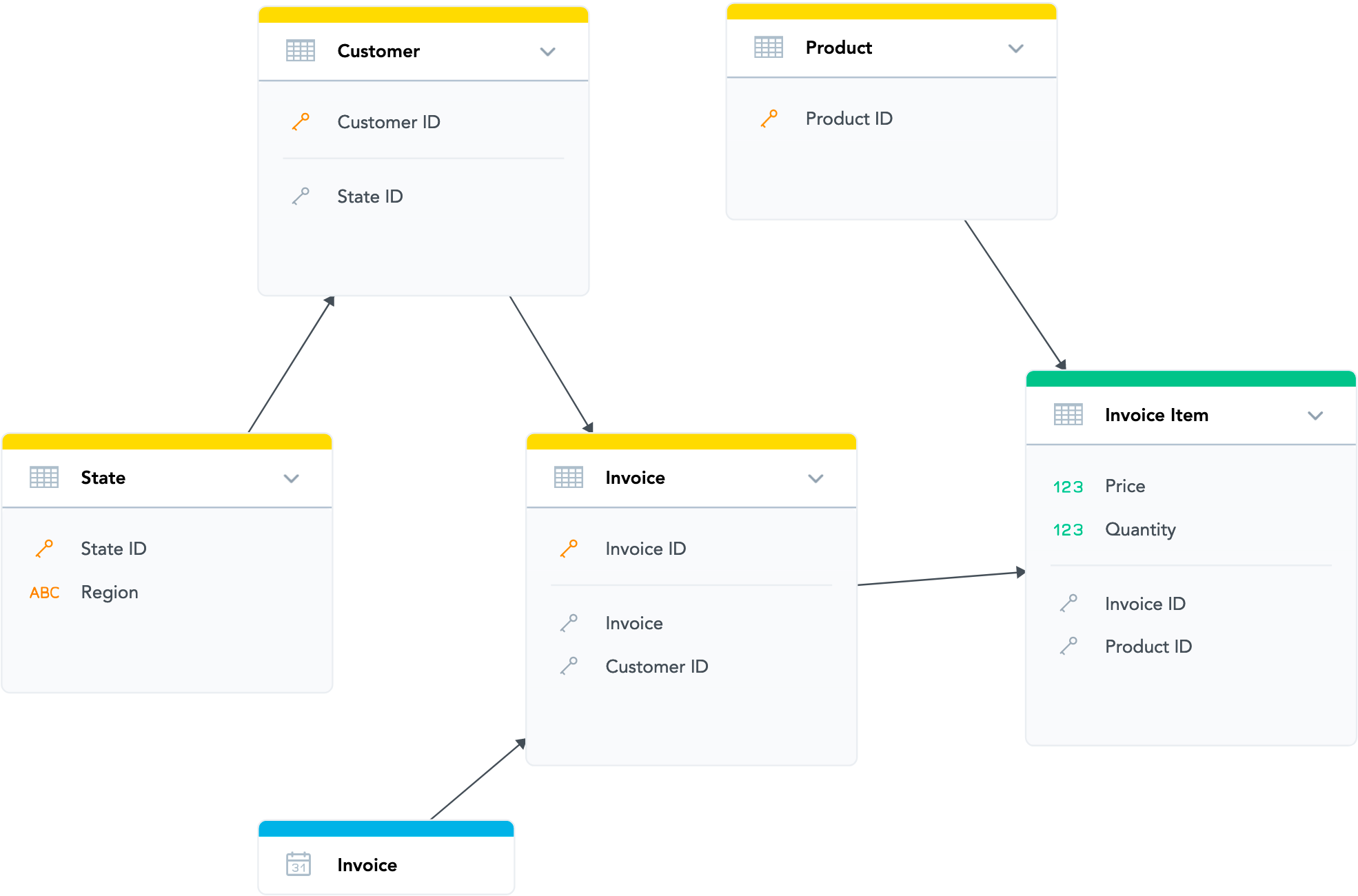
In the following table:
- The columns represent particular datasets and the corresponding database objects in the data warehouse.
- In a cell, the first line (if present) indicates the identifier of the object, and the second line indicates the corresponding database object/column.
dataset.state State | dataset.customer Customer | dataset.product Product | dataset.invoice Invoice | dataset.invoiceitem InvoiceItem |
|---|---|---|---|---|
attr.state.stateid cp__stateid | attr.customer.customerid cp__customerid | attr.product.productid cp__productid | attr.invoice.invoiceid cp__invoiceid | fact.invoiceitem.quantity f__quantity |
label.state.stateid.abbrev l__stateid__abbrev | r__state | r__customer | fact.invoiceitem.price f__price | |
label.state.stateid.name l__stateid__name | d__invoice | r__product | ||
attr.state.region a__region | r__invoice |
Conflict Resolution
Typically, only the last section of an LDM element identifier is used to map database objects in the Output Stage to the LDM datasets. This is true when the second section of the identifier matches the database object that it maps to. For example, the LDM fact fact.person.age in the dataset dataset.person becomes the column f__age in the corresponding database object.
However, if the database object and the LDM dataset do not match, the last two sections of the LDM element identifier become a part of the column name. For example, the LDM fact fact.spouse.age in the dataset dataset.person becomes the column f__spouse__age.
Special Columns in Output Stage Tables
In addition to the standard columns mapped to the LDM elements in the Output Stage database objects, there are the following optional columns that, when present, influence ADD v2 behavior:
- The
x__client_idcolumn enables data distribution from a single Output Stage object into multiple workspaces based on the values in this column.
When data is loaded to a particular workspace, only the records with the value in thex__client_idcolumn equal to the workspace client ID are loaded into the corresponding dataset in the workspace. For more information about the client ID, see Automated Data Distribution v2 for Data Warehouses and Set Up Automated Data Distribution v2 for Data Warehouses. - The
x__timestampcolumn is relevant only for incremental loads (see Load Modes in Automated Data Distribution v2 for Data Warehouses).
The records with the same value in thex__timestampcolumn make up a group of records that was created in the Output Stage during run of a particular ADD v2 process. Between two groups of records, the group that was created later has a greater value in thex__timestampcolumn than the group of records that was created earlier.
When data is loaded to a particular dataset and the load completes successfully, ADD v2 stores to the dataset’s metadata the greatest value in thex__timestampcolumn of the corresponding Output Stage table. Next time, ADD v2 retrieves the last greatest value from the dataset’s metadata, and only those records whose value of thex__timestampcolumn is greater than the timestamp stored in the corresponding dataset’s metadata are taken from the Output Stage table and are loaded into the corresponding dataset in the workspace. - The
x__deletedcolumn enables the data deletion functionality on a single Output Stage table (see Load Modes in Automated Data Distribution v2 for Data Warehouses).