Direct Data Distribution from Data Warehouses and Object Storage Services
Direct data distribution from data warehouses and object storage services covers extracting consolidated and cleaned data directly from a data warehouse/object storage service and distributing it to your GoodData workspaces.
You can integrate data from your data warehouse/object storage service directly into the GoodData platform.
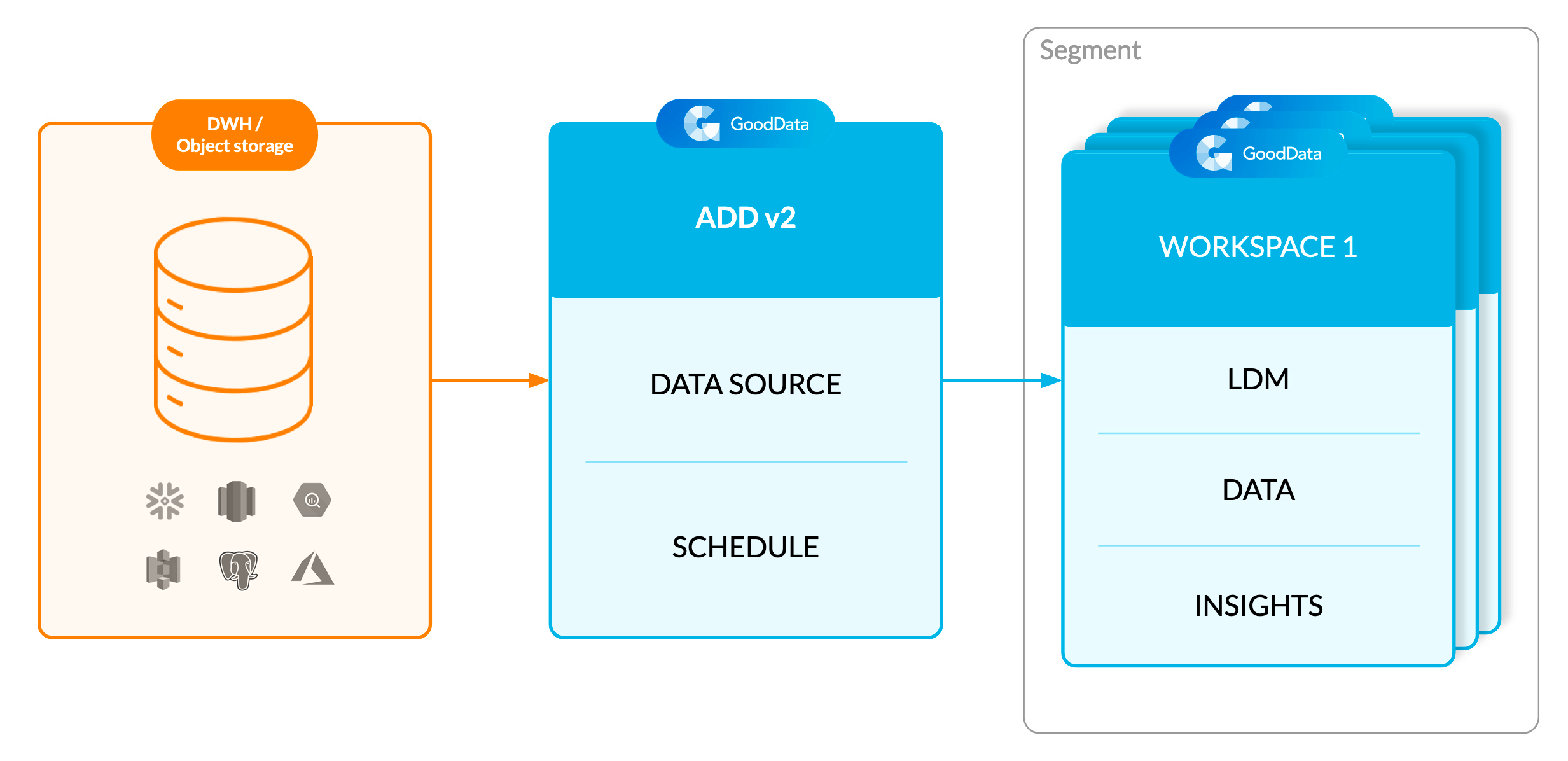
The Automated Data Distribution (ADD) v2 process synchronizes data from the data warehouse/object storage service with your customers’ workspaces based on a defined schedule. This is a key approach in building optimized multi-tenant analytics for all your customers and users without the runaway costs associated with executing direct queries to your data warehouse or object storage service. For more information about ADD v2 benefits and usage, see Automated Data Distribution v2 for Data Warehouses and Automated Data Distribution v2 for Object Storage Services.
Setting up direct data distribution from a data warehouse/object storage service requires actions that you perform both on your data warehouse/object storage service and in your GoodData workspace.
If you are new to GoodData, see our step-by-step tutorial Integrate a Data Source for a Data Warehouse.
Supported Data Warehouses and Object Storage Services
The GoodData platform supports direct integration with the following third-party data warehouses:
- Amazon Redshift (see https://aws.amazon.com/redshift/)
- Google BigQuery (see https://cloud.google.com/bigquery/)
- Microsoft SQL Server (see https://www.microsoft.com/en-us/sql-server/)
- Microsoft Azure SQL Database (see https://azure.microsoft.com/en-us/products/azure-sql/database/)
- Microsoft Azure Synapse Analytics (see https://azure.microsoft.com/en-us/services/synapse-analytics/)
- MongoDB Connector for BI (see https://www.mongodb.com/docs/bi-connector/current/)
- MySQL (see https://www.mysql.com/)
- PostgreSQL (see https://www.postgresql.org/)
- Snowflake (see https://www.snowflake.com/)
The GoodData platform also supports direct integration with following object storage services:
- Amazon S3 (https://aws.amazon.com/s3/)
- Microsoft Azure Blob (https://azure.microsoft.com/en-us/services/storage/blobs/)
Components of Direct Data Distribution
Data Source
A Data Source is an entity that holds the properties (location and access credentials) of the source of your data.
If you integrate data from the data warehouses, a Data Source stores the properties of a data warehouse. If you use the Output Stage, the Data Source also stores the Output Stage prefix.
For more information about Data Sources, see Create a Data Source.
The Data Source is the main reference point when you are performing the following tasks:
- Generating the Output Stage. The GoodData platform scans the data warehouse schema stored in your Data Source and generates recommended views for the Output Stage.
- Generating an LDM. The GoodData platform scans the data warehouse schema or the Output Stage that is specified in your Data Source and provides a definition of the LDM, which you then use for generating the LDM in your workspace.
- Validating the mapping between the Data Source and the LDM. The Output Stage connected to your Data Source is compared to the LDM, and a list of inconsistencies is returned. Validate the mapping after you have changed the Output Stage or the LDM to see what changes are required.
- Managing mapping between workspaces and your customers' data. You can provide a custom mapping scheme to match the workspace IDs (also known as project IDs) and the client IDs. For more information about client IDs, see Automated Data Distribution v2 for Data Warehouses.
You can perform all the above tasks using individual API calls.
If you integrate data from the object storage services, a Data Source stores the properties of an object storage service.
Output Stage
The Output Stage is used only when you set up direct data distribution from the data warehouses. The Output Stage is not used with object storage services.
The Output Stage is a set of tables and/or views created in your data warehouse specifically for integration with GoodData. The Output Stage serves as a source for loading data to your workspaces. Use the Output Stage if you cannot or do not want to download the data directly from the production tables in your data warehouse.
You can prepare the Output Stage manually or generate the Output Stage for the Data Source or the LDM. You can generate the Output Stage from a different schema than the schema that will contain the Output Stage.
If you decide to create the Output Stage manually, make sure that the following requirements are met:
- The Output Stage is located in the warehouse, database, and schema that you specified in your Data Source.
- All views and tables in your Output Stage have the prefix that you specified in the Data Source. All views and tables without the prefix are ignored during the data load.
- All columns are named according to the naming convention (see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses). Column names can contain underscores (
__) only as part of the prefix. - All columns in the Output Stage are compatible with the GoodData data types. For more information, see the following articles:
- GoodData-Azure Synapse Analytics Integration Details
- GoodData-Azure SQL Database Integration Details
- GoodData-BigQuery Integration Details
- GoodData-Microsoft SQL Server Integration Details
- GoodData-MongoDB BI Connector Integration Details
- GoodData-MySQL Integration Details
- GoodData-PostgreSQL Integration Details
- GoodData-Redshift Integration Details
- GoodData-Snowflake Integration Details
- The names of the views and tables in the Output Stage do not contain special characters.
- There are no name collisions between your columns/tables and the GoodData technical columns and tables (see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses).
If you decide to generate the Output Stage for the Data Source (see Create the Output Stage based on Your Data Warehouse Schema) or LDM (see Create the Output Stage based on Your Logical Data Model), review the resulting SQL code to check the following:
- All columns that should serve as connection points are prefixed with
cp__. - All columns that should serve as references are prefixed with
r__. - Attributes that are represented by numeric values (for example, a customer tier that can be 1, 2, or 3) are prefixed with
a__. Unless this is done, all columns with a numerical data type (INT,FLOAT, and other) are by default identified as facts (the prefixf__).
For more information, see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses.