Mapping between a Logical Data Model and the Data Source
Any dataset in your logical data model (LDM) must have each field (a fact or an attribute) unambiguously mapped to a column in a source table (represented by a table in your data warehouse or a CSV file). The dataset itself must be mapped to this source table.
During data load, the data from the columns in the source table will be loaded to the corresponding facts or attributes in the dataset.
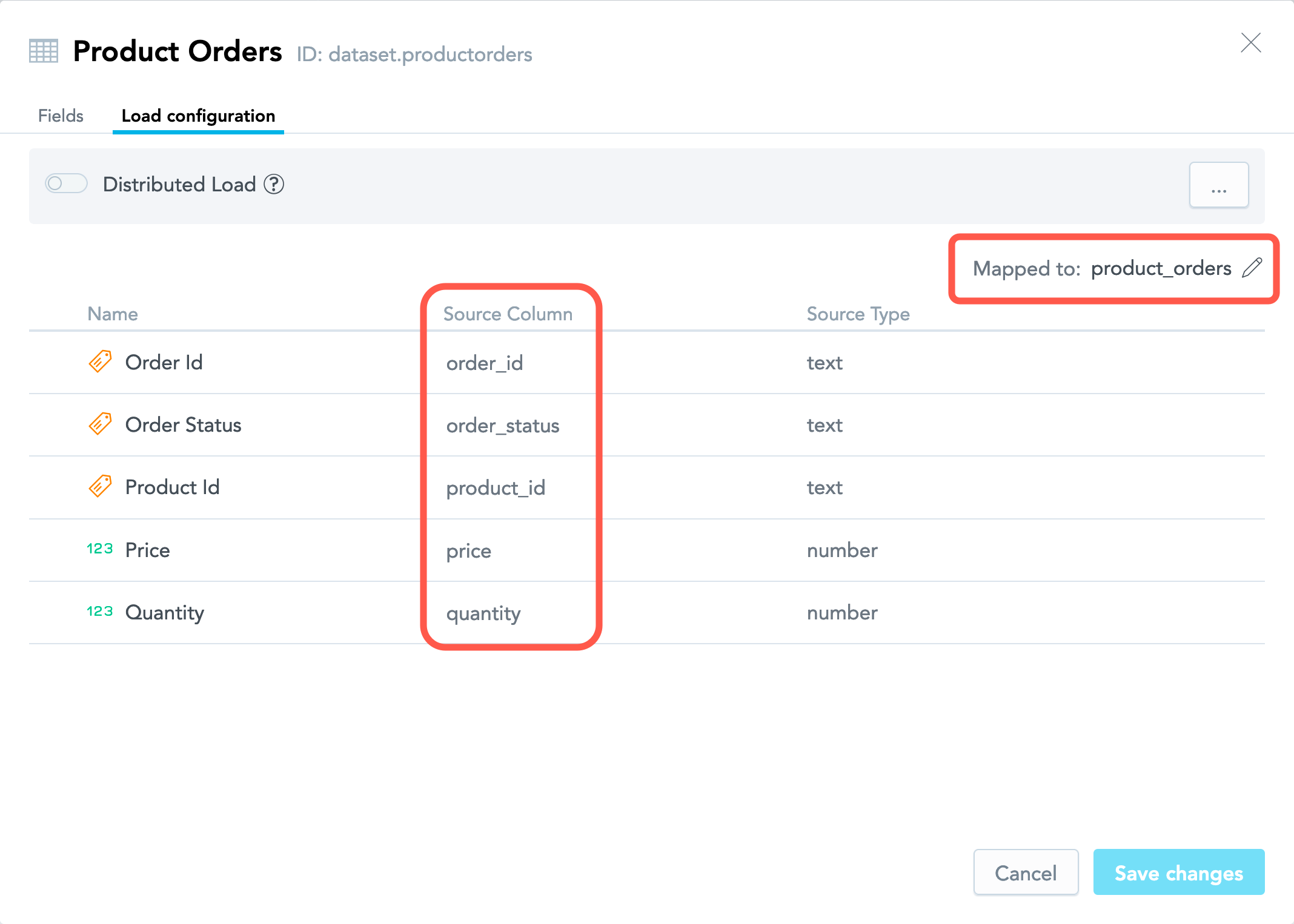
For example, the facts and attributes in the Product Orders dataset are mapped to the columns in the product_orders.csv file.
order_id,order_status,product_id,price,quantity
10668-9VYN74-2,Cancelled,210,100.33,1.00
10697-7GBN87-1,Delivered,310,39.35,1.00
10907-0TPH53-3,Delivered,220,50.40,1.00
10778-7INQ32-1,Delivered,230,78.40,1.00
10240-3SBQ40-3,Delivered,160,21.49,1.00
10356-7ZBU60-1,Cancelled,140,21.49,1.00
10700-0ACT49-1,Returned,150,21.82,1.00
10175-0YRN35-3,Delivered,150,19.15,3.00
10152-6HOB25-1,Cancelled,140,29.67,1.00
Review the Mapping in a Dataset
You can review the mapping for a dataset in its details.
Steps:
- Select the dataset, click More… -> View details. The dataset details dialog opens that lists all the dataset facts, attributes, and attribute labels.
- Click the Load configuration tab.
Mapping in Datasets Created Manually
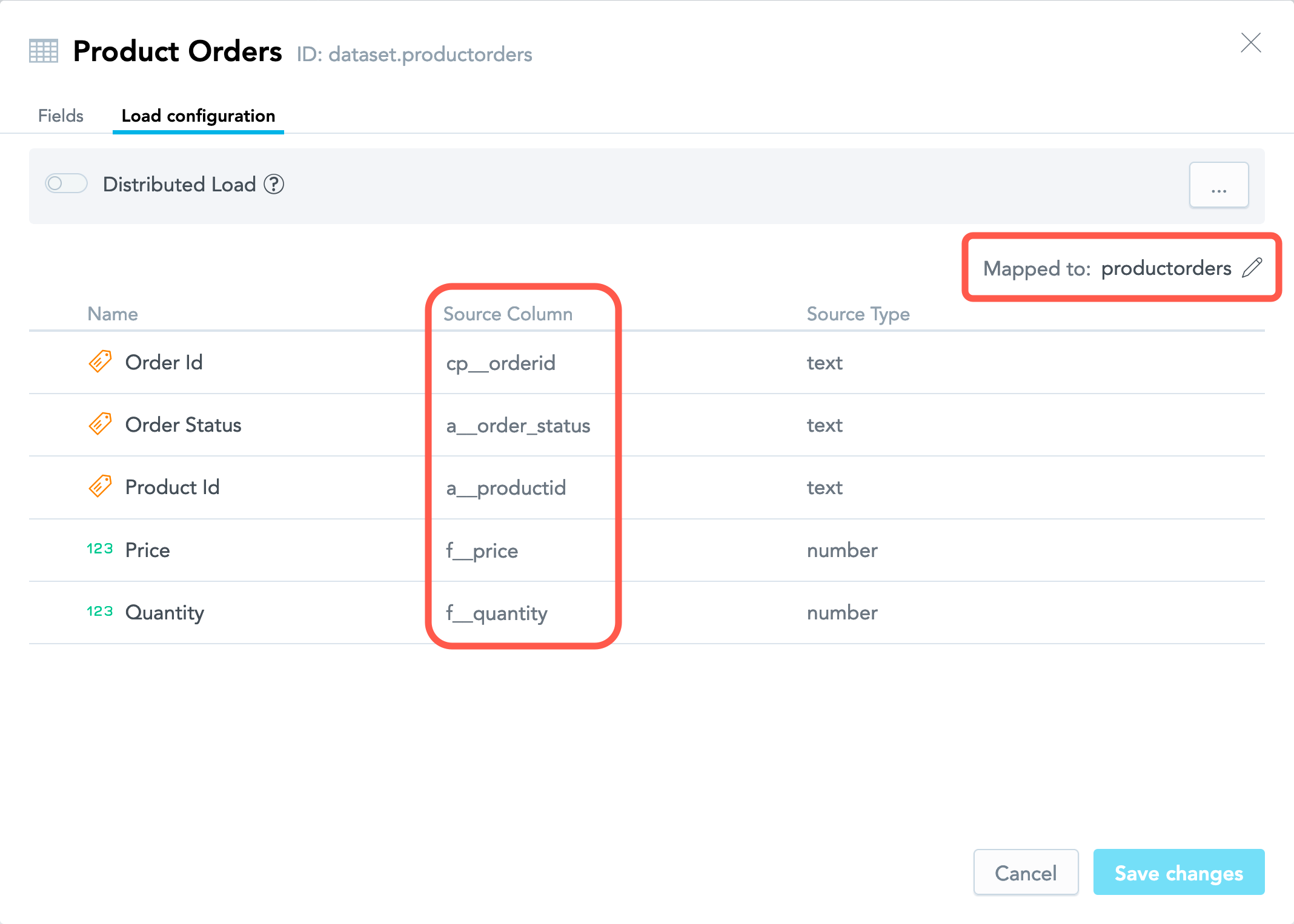
If a dataset was created manually (see Create a Logical Data Model Manually), its fields are not mapped to any columns, and the name of the source table is generated based on the dataset name.
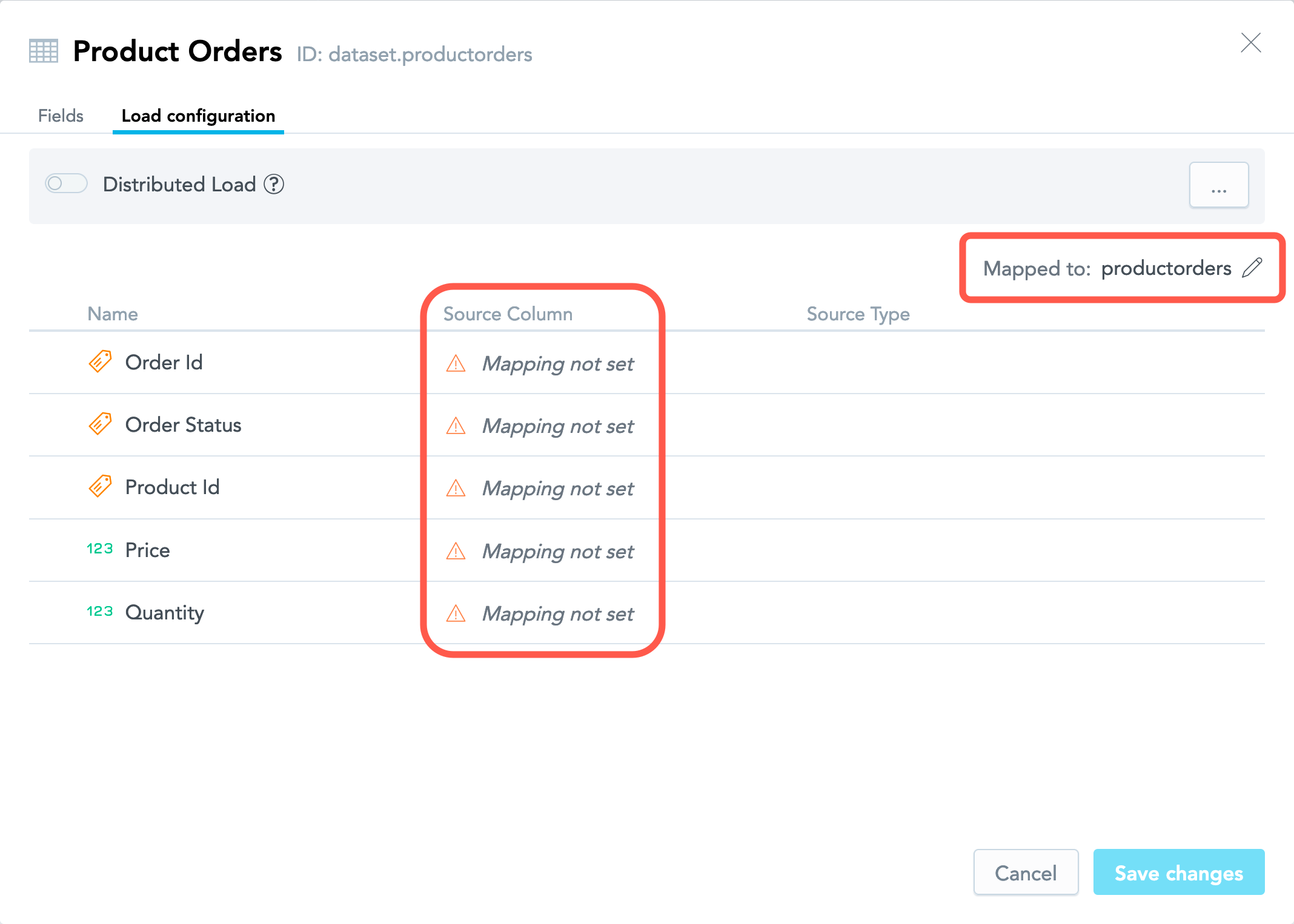
To set up mapping, do one of the following:
If you want to load data from a table in your data warehouse, manually map the dataset fields to the columns in this table and map the dataset itself to this table. For example, if you have a table named
product_orderswith the following columns:order_id,order_status,product_id,price,quantitymap the dataset fields to those columns and the dataset itself to the table as follows:
- If you want to load data from a CSV file, download the CSV template for the dataset. For more information, see Update Data in a Dataset from a CSV File.
Mapping in Datasets Created from CSV Files
If a dataset was created from a CSV file (see Create a Logical Data Model from CSV Files or Create a Logical Data Model from Your Cloud Object Storage Service), the dataset fields are mapped to the columns in that CSV file. You can use CSV files with the same column names to load data to the dataset. For more information, see Update Data in a Dataset from a CSV File.
If you want to switch to loading data from a table in the data warehouse and this table has the same name and the column names as the CSV file, you can keep the mapping as is. If the table has a different name and/or column names, manually update the dataset so that its fields are mapped to the table columns and the dataset has the table name mapped to it.
Mapping in Datasets Created from Data Warehouse Tables
If a dataset was created from a table in your data warehouse (see Create a Logical Data Model from Your Cloud Data Warehouse), the dataset fields are mapped to the columns in that table. You can use this table to load data to the dataset.
Columns that Enable Additional Load Options
You can enable the following options:
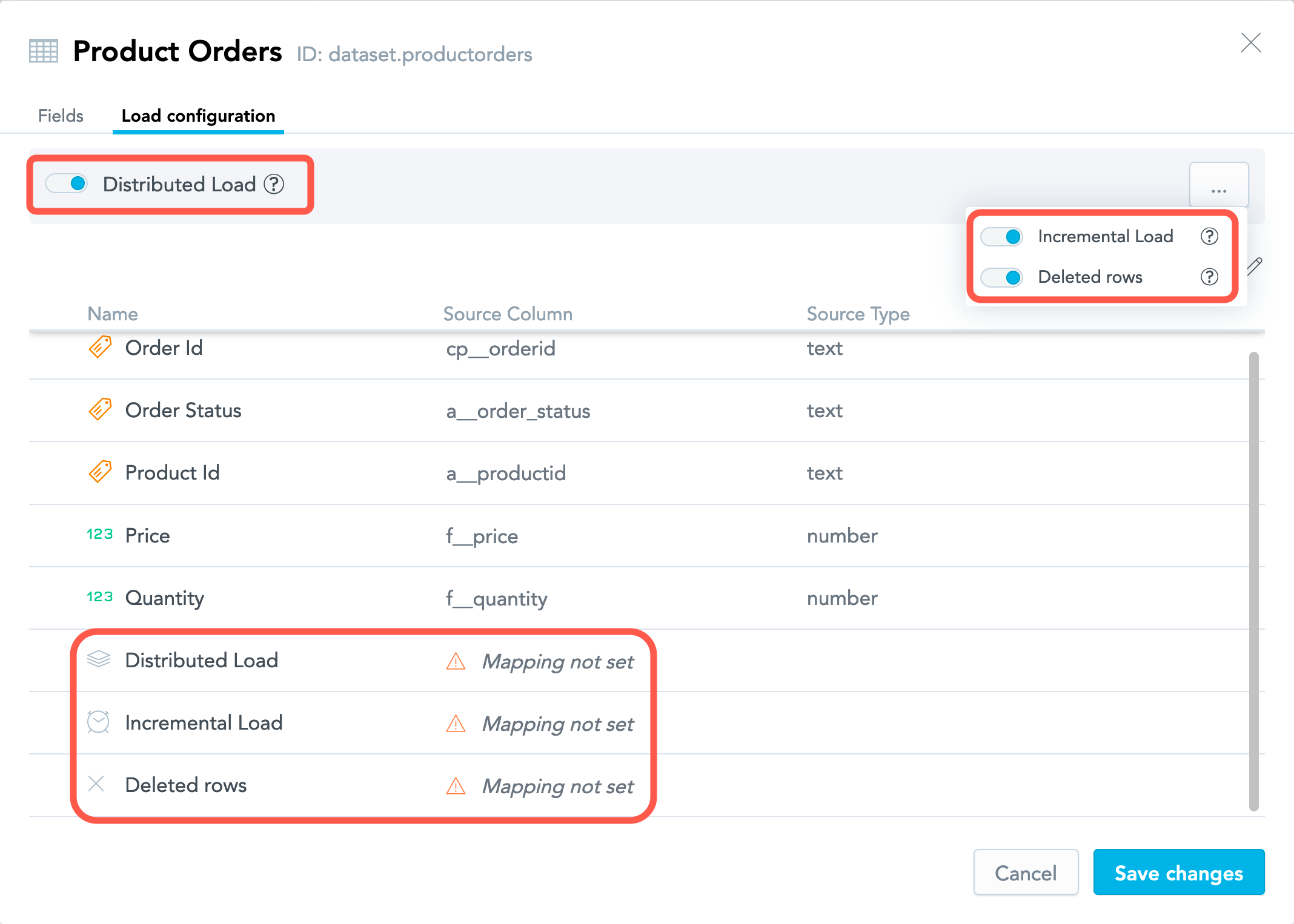
Distributed load is data distribution from a single source table into multiple workspaces based on client IDs. The client IDs are stored in the
x__client_idcolumn in the source table. When data is loaded to a particular workspace, only the records with the value in thex__client_idcolumn equal to the workspace client ID are loaded to the corresponding dataset in the workspace. For more information about the client ID, see Automated Data Distribution v2 for Data Warehouses and Automated Data Distribution v2 for Object Storage Services.x__client_idis the default name for the column holding the client IDs. If you store the client IDs in a column with a different name, map the data distribution field to that column.(For data warehouses only) Incremental load is loading data in increments based on timestamps. The timestamps are stored in the
x__timestampcolumn in the source table. The records with the same value in thex__timestampcolumn make up a group of records that was created in the dataset during run of a particular data load process. Between two groups of records, the group that was created later has a greater value in thex__timestampcolumn than the group of records that was created earlier. When data is loaded to a particular dataset and the load completes successfully, the greatest value in thex__timestampcolumn is stored in the dataset’s metadata. Next time, only the records whose value of thex__timestampcolumn is greater than the timestamp stored in the corresponding dataset’s metadata are taken from the source table and are loaded into the corresponding dataset. For more information about incremental load, see Load Modes in Automated Data Distribution v2 for Data Warehouses.x__timestampis the default name for the column holding the timestamps. If you store the timestamps in a column with a different name, map the incremental load field to that column.Incremental load relies on thex__timestampcolumn only when data is loaded from a data warehouse. When you load data from an object storage service, incremental load is enabled based on the source file name (see Load Modes in Automated Data Distribution v2 for Object Storage Services).Deleted rows is data deletion based on a flag marking particular records to be deleted from a dataset. The flag is stored in the
x__deletedcolumn in the source table. If the flag is set totruefor a particular record, this record will be deleted from the dataset. For more information about the data deletion, see Load Modes in Automated Data Distribution v2 for Data Warehouses and Load Modes in Automated Data Distribution v2 for Object Storage Services.x__deletedis the default name for the column holding the deletion flag. If you store the flag in a column with a different name, map the deleted rows field to that column.