Many-to-Many Modeling Performance
There are two methods when data modeling for M:N in a GoodData logical data modeler:
- standard ‘out-of-the-box’ method
- alternative method
Standard M:N support is simple, and it works as described in the Many-to-Many in Logical Data Models. By using the alternative modeling method, you can improve performance of many-to-many data relationships by reducing calculation permutations.
Standard Modeling Method
The standard approach to modeling M:N relationships is to use Ticket / Tag bridge table that combines all the tickets with their respective tags:
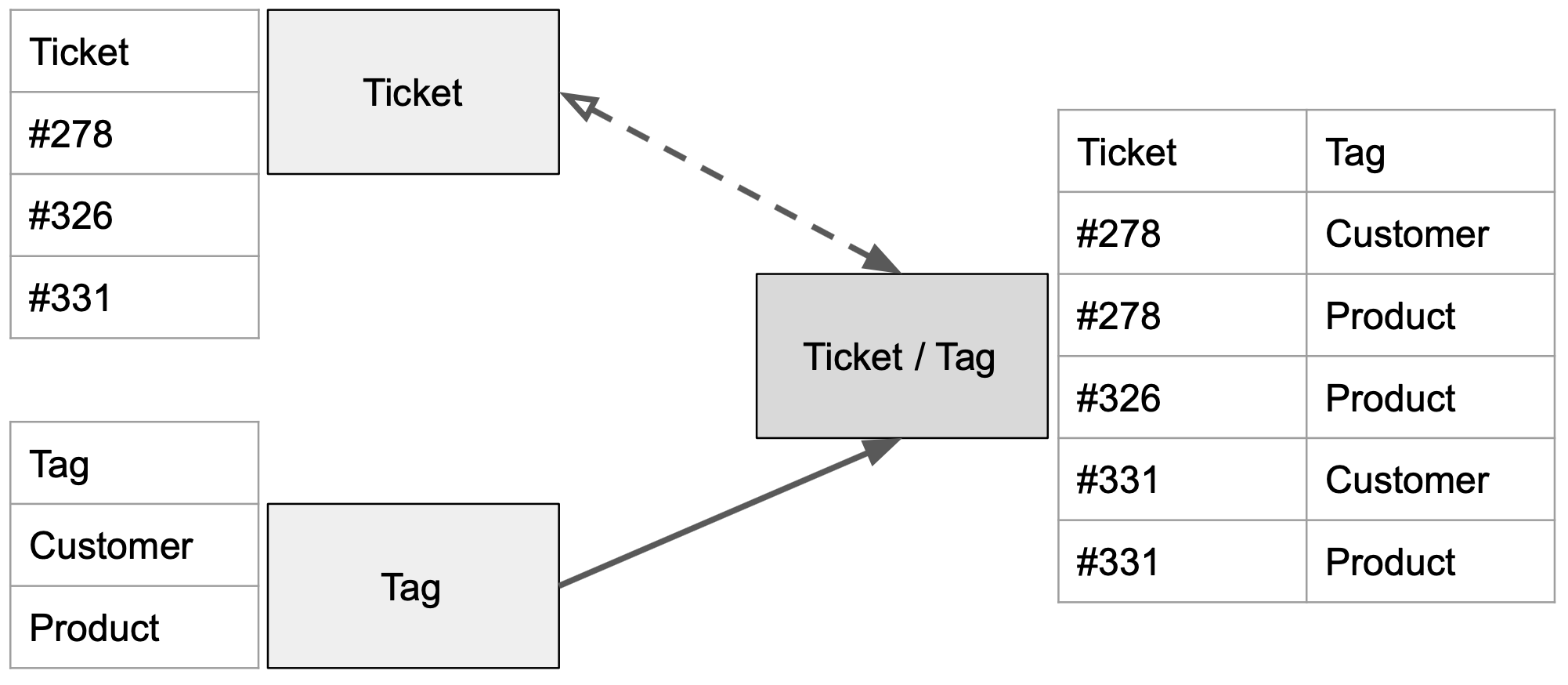
This method works natively in GoodData but, in case, the bridge dataset (and other datasets connected to it) can be huge (millions of rows) and the platform performance can suffer. In such cases, the alternative method of modeling M:N relationships is more appropriate.
Alternative Modeling Method
Instead of a single bridge table, use two tables in as seen in the following structure:
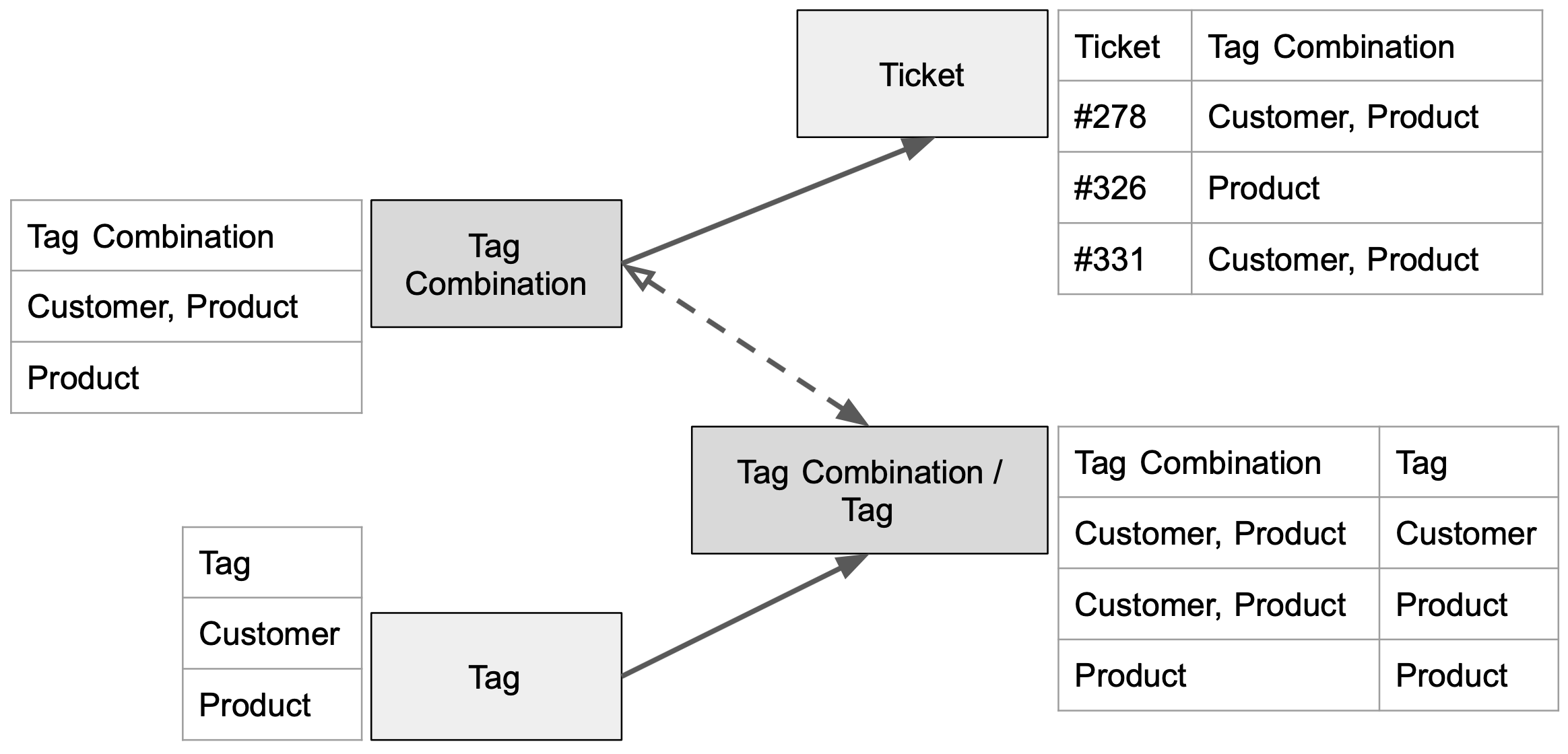
Note that bridge table Tag Combination has a completely different structure to the structure in the original bridge table. It contains all the tag combinations used in the tickets (so essentially a concatenated string of all tags - or if too long, a hash of this). The worst thing that can happen in this scenario is that the Tag Combination dataset can be as big as the Ticket dataset (if every single ticket has a different tag combination) but generally this will be much smaller when used in a real life scenario.
You can then map an M:N relationship between Tag Combination and Tag in another dataset (Tag Combination / Tag). Here, we are assigning to each of these tag the combinations all their individual tags.
This model will work more efficiently in most cases, but the trade off for the better performance is the higher complexity of the data transformation you need to build.