You are viewing our older product's guide. Click here for the documentation of GoodData Cloud, our latest and most advanced product.
Create a Relationship between Datasets
A relationship between two datasets allows you to use information from one dataset to slice the data in the other dataset.
This article will explain how create the relationship between your datasets.
Relationship Properties
Primary Key
Creating a relationship requires a primary key in one of the datasets. You cannot create a relationship between two datasets if none of them has the primary key set. For more information about primary keys, see Connection Points in Logical Data Models.
A good primary key should be a unique column of data that you can use to help analyze your data. For example, the Product ID column in the product.csv example file is a great primary key.
If you did not set a primary key for your datasets at the time of import, you will need to set it while creating a relationship between the datasets. To decide what dataset must have the primary key, decide what data you want to analyze (slice) and what data you want to use to help analyze. The dataset with the data that you want to use to help analyze the other data is the one that must have a primary key.
Only an attribute can be set as a primary key. A primary key must contain only one attribute.
Reference
When a relationship is created, a reference is set in the other (target) dataset. The reference is an attribute in the target dataset that is associated with the primary key of the originating dataset.
When deciding on how to set the reference, you can choose one of the following options:
- Create a new attribute in the target dataset based on the primary key from the originating dataset, and make it a reference. This new attribute in the target dataset is populated by references to the primary key values from the originating dataset. Each value in the reference attribute must have a corresponding value of the primary key in the originating dataset.
- Reuse an existing attribute from the target dataset, and make it a reference. Once the relationship is created, the primary key from the originating dataset is merged with the attribute in the target dataset that you made the reference.
Relationship Type
A relationship between two datasets can be one of the following types:
- A 1:N (one-to-many) relationship, which is a one-directional relationship between the datasets when the data from one dataset can be used to analyze the data from the other dataset, but not the other way round. This is the default type of the relationship.
- An M:N (many-to-many) relationship that allows you to use the data from either dataset to analyze the data from the other dataset. For more information about them, see Many-to-Many in Logical Data Models.
Types of Datasets in a Logical Data Model
There are three types of datasets in the logical data model (LDM).
- Attribute datasets. Attributes are data that is used to categorize the values that result from metrics. In almost all use cases, this data is a non-calculable value. An attribute dataset is a dataset that consists of attributes to describe the facts in your LDM. Generally, the attribute dataset will contain the data that you want to use to help analyze the data in a fact dataset. Only an attribute can be used as a primary key and a reference. The
product.csvfile is an example data that can be used to create an attribute dataset. - Fact datasets. A fact is a numerical piece of data, which in a business environment is used to measure a business process. A collection of facts that measure the same business process is stored in a single data unit called a fact dataset (also known as a fact table). A fact dataset contains individual fact values and pointers to associated attributes used as context for the fact data. The
order_line.csvfile is an example of data that be used to create a fact table. - Date dataset. The Date dataset is a predefined collection of attributes that you can use to slice to the data in a fact dataset by the lowest level of the date hierarchy (day) to the highest level (year). The
order_lines.csvfile contains the date column, which automatically imports into the LDM Modeler as a date dataset.
Create a Relationship between Datasets
Steps:
Select the originating dataset (the dataset that you want to create the relationship from).
Select the blue dot on the right border of the dataset, and drag the arrow that appears to connect the dataset to the other dataset.
The following dialog opens:
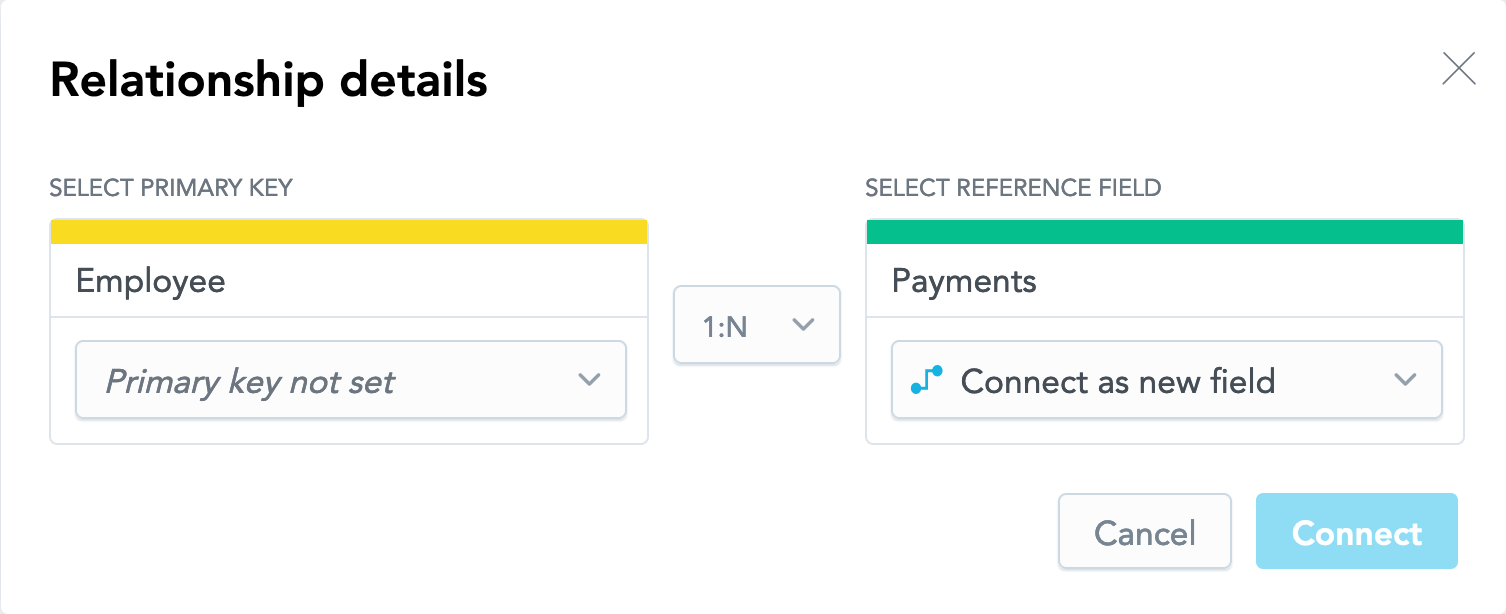 This dialog does not appear when you are creating a relationship between a regular dataset and a Date dataset. Such relationship is created right away as a 1:N relationship, and a reference to the Date dataset is added to the regular dataset as a new field.
This dialog does not appear when you are creating a relationship between a regular dataset and a Date dataset. Such relationship is created right away as a 1:N relationship, and a reference to the Date dataset is added to the regular dataset as a new field.On the left, select Primary key not set, and select the attribute that should become the primary key.
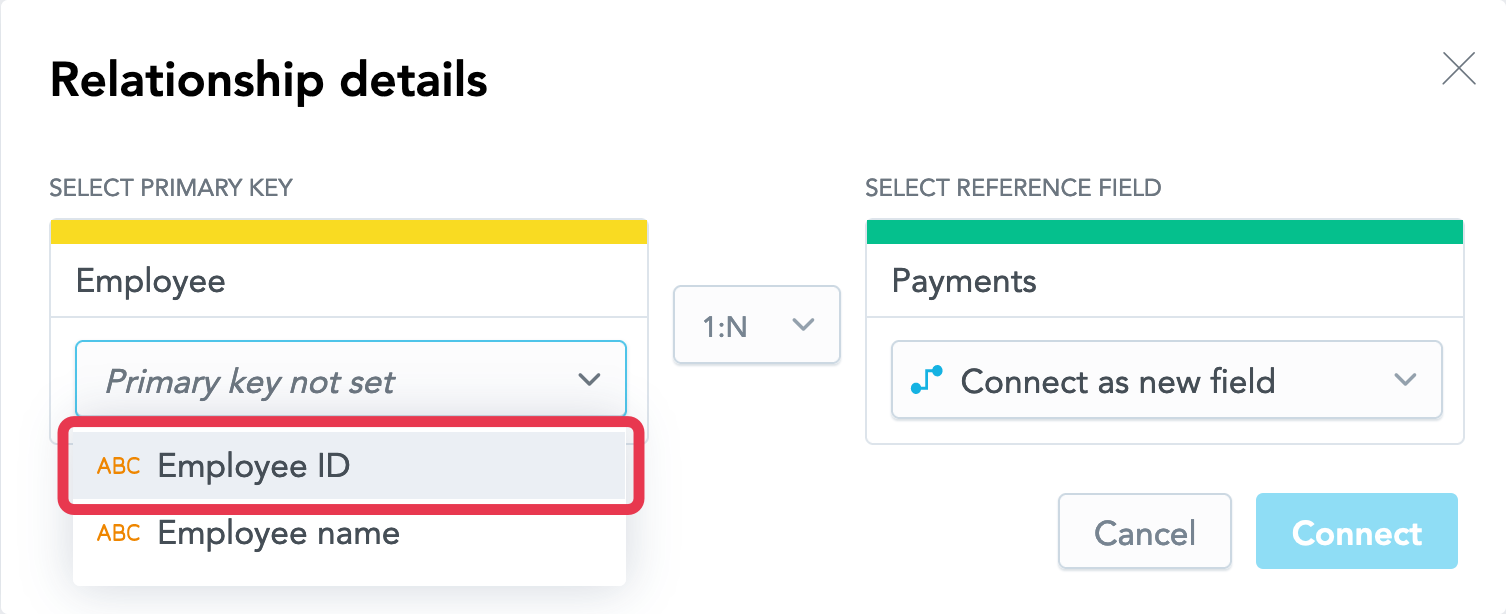 If the dataset already as the primary key set, it will be pre-selected in the dropdown. You cannot edit the primary key for the dataset in this dialog. To update the dataset, see Set or Update the Primary Key in a Dataset.
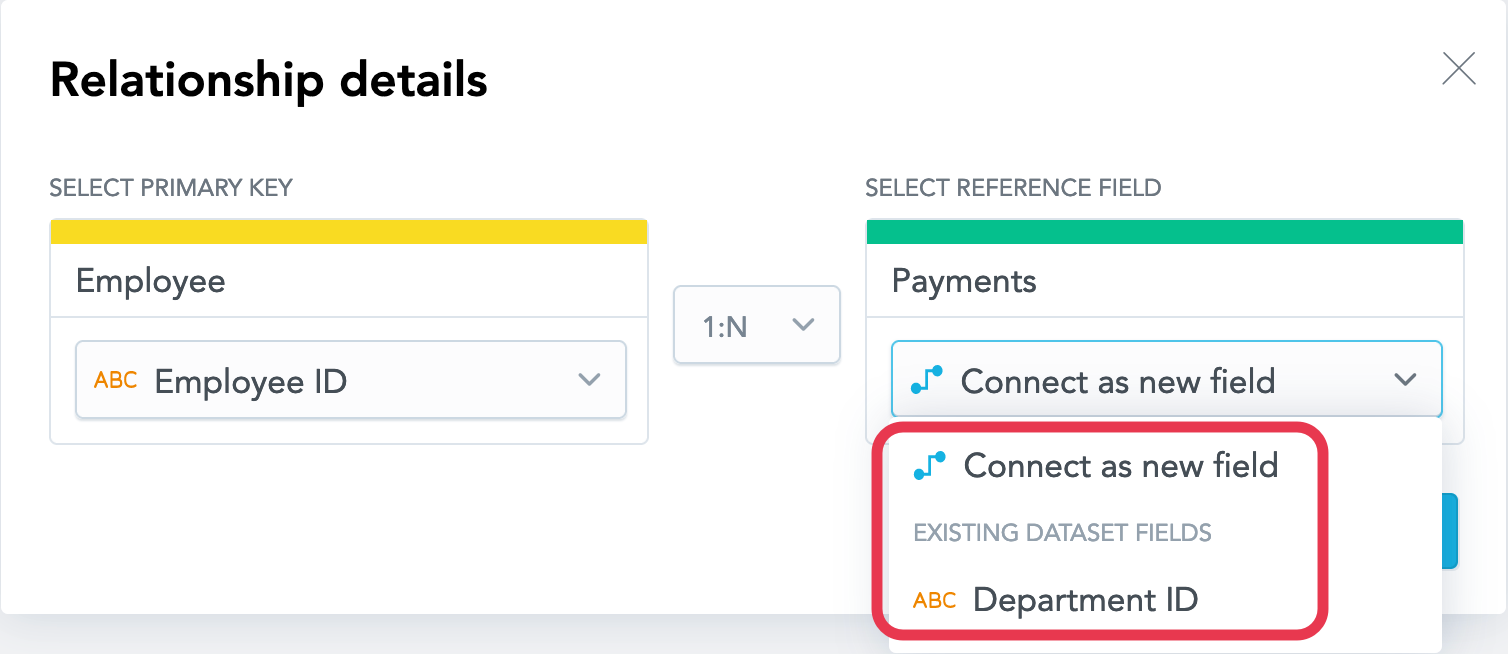
If the dataset already as the primary key set, it will be pre-selected in the dropdown. You cannot edit the primary key for the dataset in this dialog. To update the dataset, see Set or Update the Primary Key in a Dataset.On the right, choose how to set up a reference in the other dataset, as a new field or as an existing attribute. For the purpose of this tutorial, try using the default option, Connect as new field.
Select the type of the relationship. For the purpose of this tutorial, try using the default option, 1:N.
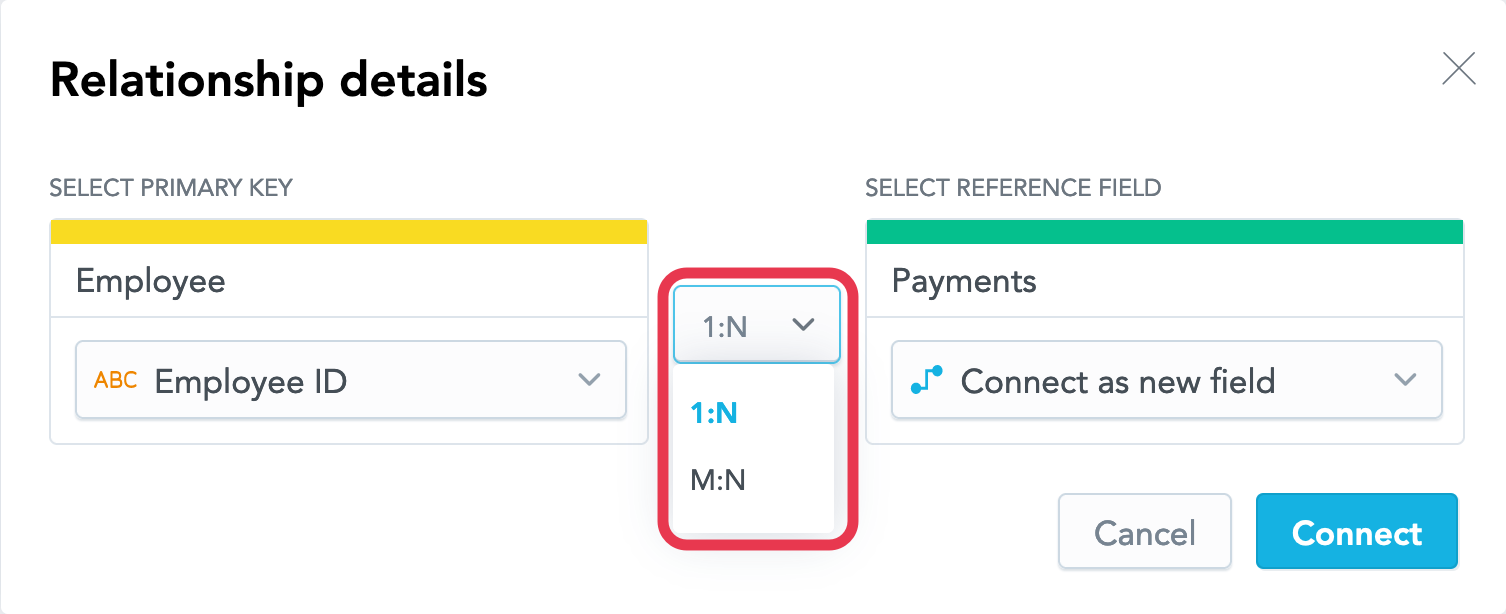
Select Connect. The relationship is created.
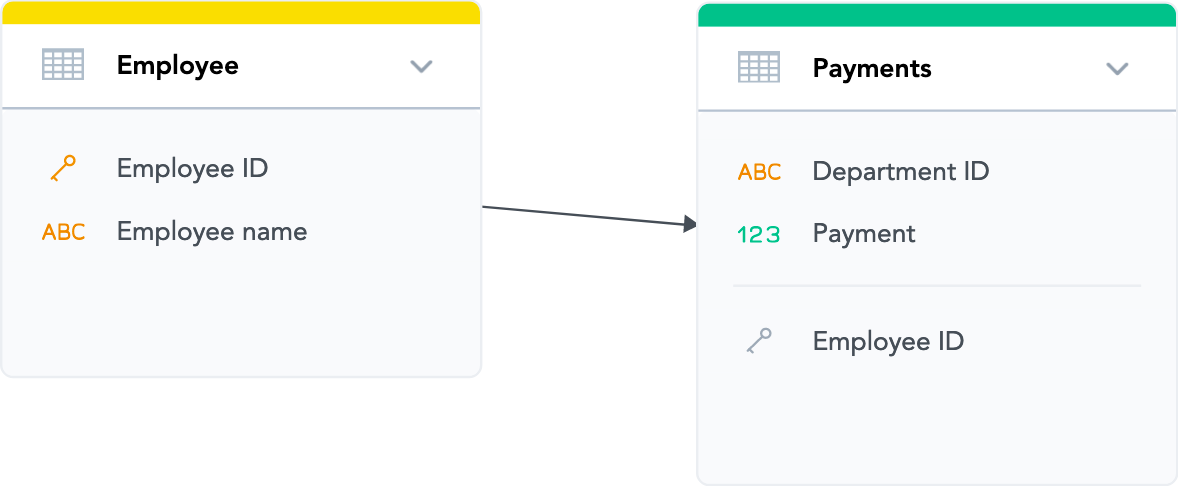
- The direction of the arrow determines which dataset’s data can be used to analyze (slice) the data from the other dataset.
- The primary key has been set in the originating dataset. In the following example, notice how the icon for the
Employee IDattribute is a key to signify it is the primary key: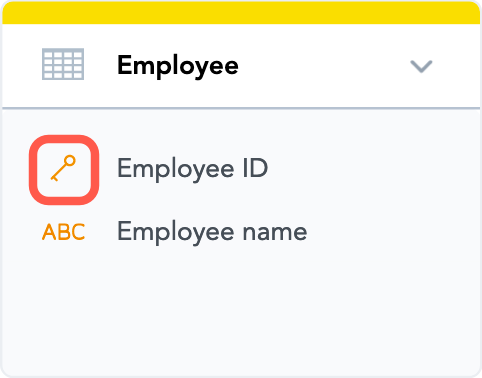
- A reference to the primary key has been added to the target dataset. In following example, a reference to the
Employee IDattribute has been added to thePaymentsdataset. This reference indicates that theEmployee IDfield is a foreign key in thePaymentsdataset, with theEmployee IDvalues from theEmployeedataset as the key values.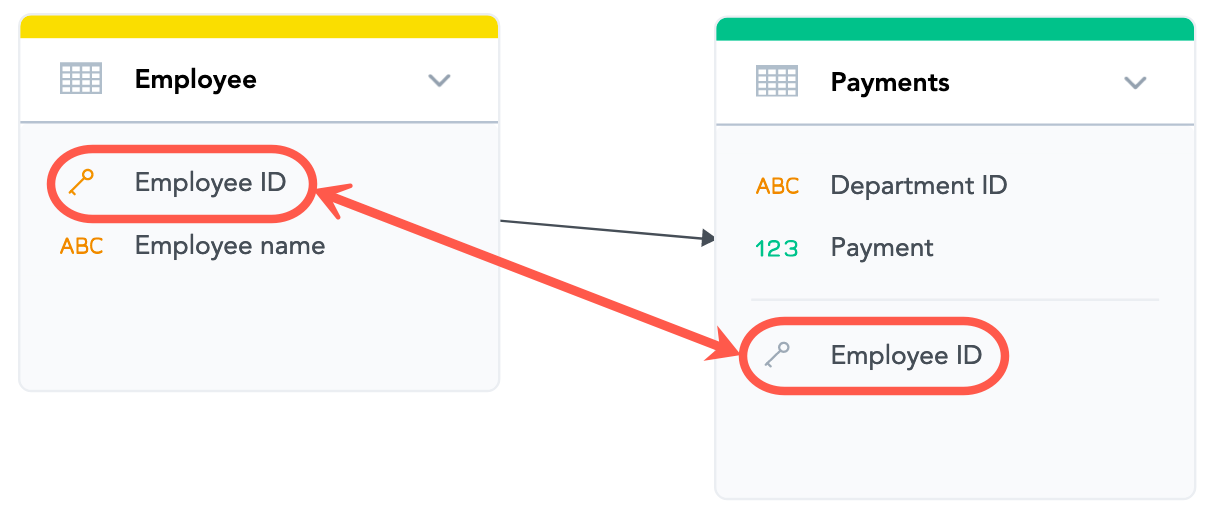
Now, update the mapping for the reference set in the target dataset.
Update Field Mapping in a Dataset
When you add a reference to a dataset, you must update the LDM mapping so that the reference uses the correct source column. If an attribute exists with the same name as the reference in the dataset that you have added the reference to, you must remove that attribute from the dataset. Every dataset in your LDM must have each field (a fact or an attribute) unambiguously mapped to a column in a source table (represented by a table in your data warehouse or a single CSV file). The dataset itself must be mapped to this source table.
During data load, the data from the columns in the source table will be loaded to the corresponding facts or attributes in the dataset.
Steps:
- Select the dataset, and select More… -> View details. The dataset details dialog opens that lists all the dataset facts, attributes, and attribute labels.
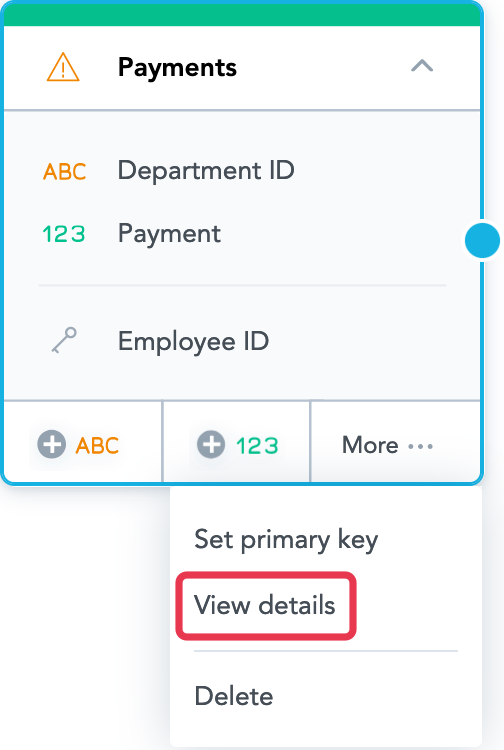
- Select the Load configuration tab, and set the source column for the reference.
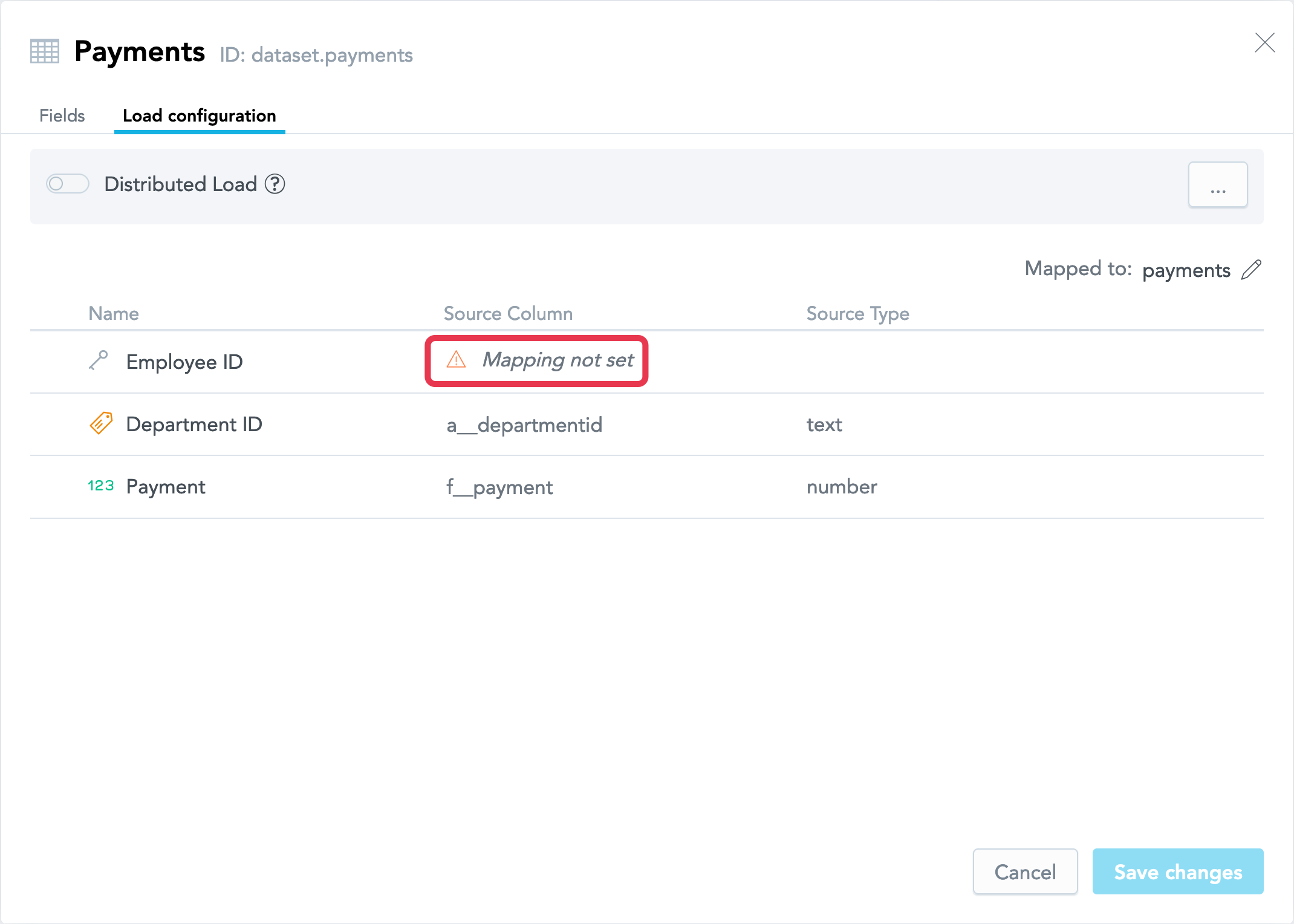
- Review the other mapping and update it, if needed.
- When you are done with updating, select Save changes.
- Publish the LDM (see Publish your Logical Data Model).
Set or Update the Primary Key in a Dataset
Steps:
- Select the dataset, and select More… -> Set primary key.
- Select the attribute that should become the primary key, and select Set key. The dialog closes, and the primary key is set.
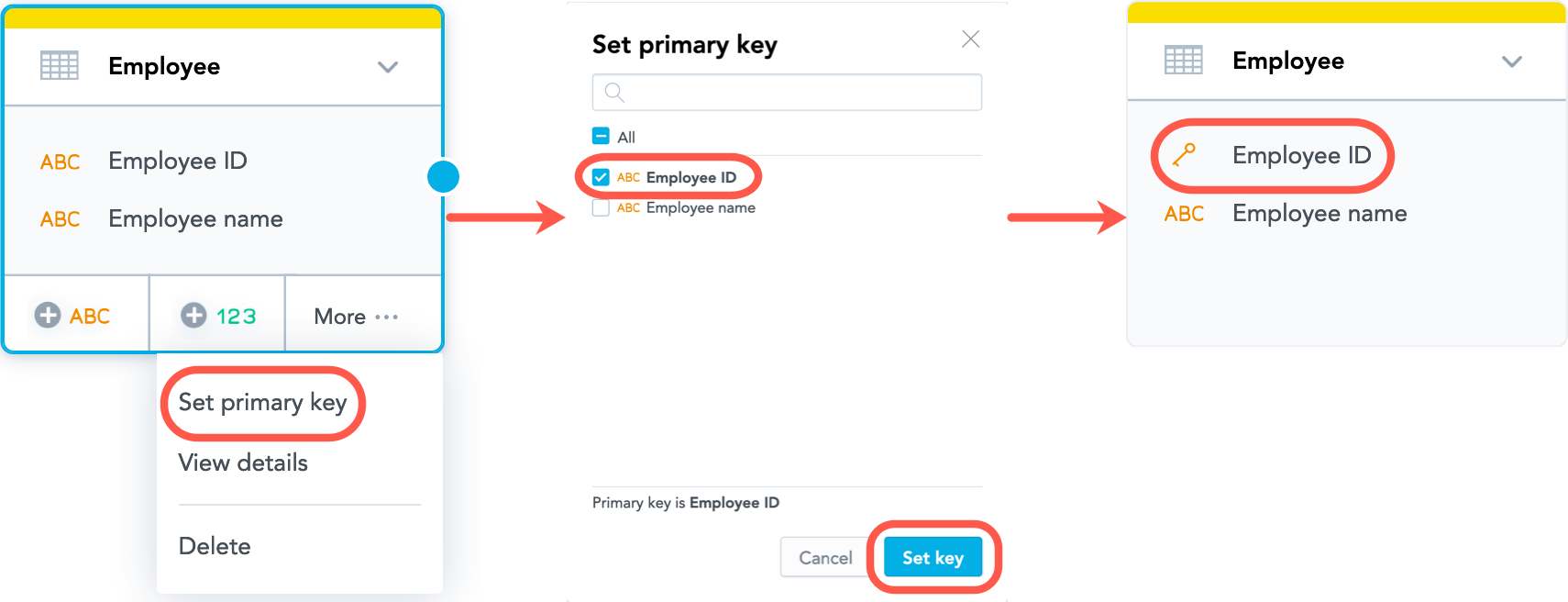
To remove the primary key from the dataset, de-select all the attributes, and select Set key.
You cannot remove the primary key from the dataset that has a relationship to another dataset. To remove the primary key, delete the relationship first.