Set Up Automated Data Distribution v2 for Object Storage Services
Automated Data Distribution (ADD) v2 for object storage services is designed to load data to segments (groups) of workspaces. ADD v2 fetches data from an object storage service for hundreds of workspaces in one query, which is more efficient than loading data for each workspace separately.
The process of setting up ADD v2 can have a different number of steps to complete.
- If you have a single workspace to distribute data to, go to Integrate the Data to Your Workspaces.
- If you have multiple workspaces and have them organized in segments (as in LCM; see Managing Workspaces via Life Cycle Management), go to Integrate the Data to Your Workspaces.
- If you have multiple workspaces and do not have them organized in segments, go to Organize the Workspaces.
Organize the Workspaces
Read this section if you have multiple workspaces and do not have them organized in segments. Otherwise, go to Integrate the Data to Your Workspaces.
When you have multiple workspaces to distribute the data to, you need to organize those workspaces into a specific structure to instruct ADD v2 what data should be loaded to what workspaces. This structure is based on segments, where a segment combines workspaces with the same logical data model (LDM). This structure is similar to the one that you have when using LCM and uses the same terminology. To learn the LCM terminology, review Managing Workspaces via Life Cycle Management.
If LCM is not implemented on your site, you do not have to set it up and use it as a feature. You only need to create a segment-based structure of your workspaces similar to LCM.
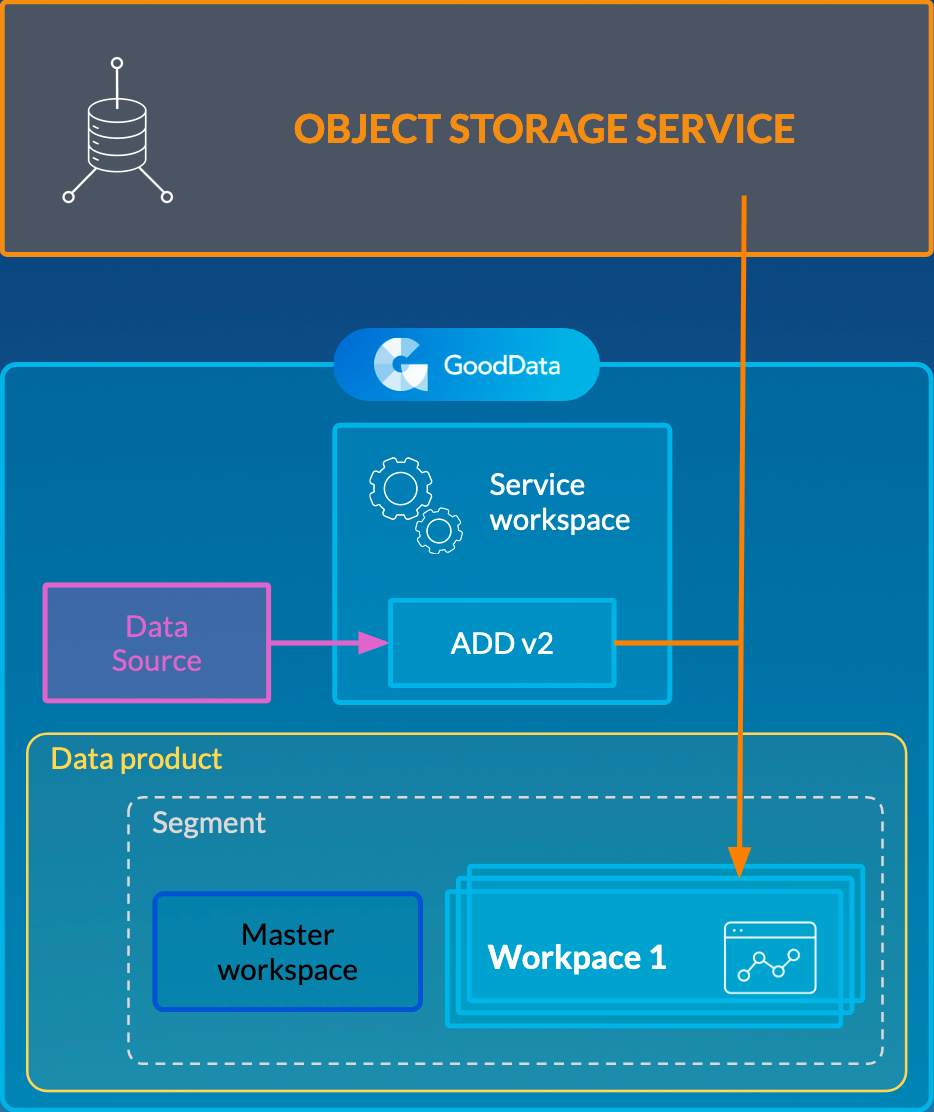
- Workspaces with the same LDM are organized in segments. Each segment has a master workspace, and the other workspaces in this segment are called clients, or client workspaces.
- Segments belong to data products. A data product can contain multiple segments.
- A service workspace is a workspace where ADD v2 data load processes are deployed and run. The service workspace does not belong to any segment and does not have to contain any data or LDM. It is usually a dummy workspace that is used only for deploying ADD v2 processes in it.
To organize the workspaces, you are going to use the APIs. Execute those APIs as a domain administrator.
Steps:
Assign the client workspaces to the appropriate segment. For each client workspace, set the client ID. For more information about the client ID, see Automated Data Distribution v2 for Object Storage Services.
If you have a large number of client workspaces, you can use the API for assigning client workspaces to segments in bulk.
Add the Client ID Column to the Source Files
Make sure that the source files that you want to distribute separately per workspace has the x__client_id column. This column should contain the values corresponding to the client ID values of your client workspaces. For more information about the client ID, see Automated Data Distribution v2 for Object Storage Services.
Integrate the Data to Your Workspaces
Follow the instructions in Integrate Data from Your Amazon S3 Bucket Directly to GoodData.