Load Modes in Automated Data Distribution v2 for Data Warehouses
Automated Data Distribution (ADD) v2 for data warehouses supports the following load modes:
- Full load: All data is loaded to the datasets. The datasets are completely rewritten.
- Incremental load: Only data after a certain point in time is loaded using the
UPSERTmethod. - Delete mode load: Some old data is deleted while new data is uploaded.
Full Mode
When ADD v2 runs for the first time, data is uploaded in full mode.
After that, ADD v2 loads data in full mode to those datasets for which the mapped tables in the Output Stage do not contain the x__timestamp column (see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses).
If the x__timestamp column is present in a mapped table, data is loaded in incremental mode.
Incremental Mode
ADD v2 loads data in incremental mode to those datasets for which the mapped tables in the Output Stage contain the x__timestamp column.
How Incremental Load Works
Imagine that you want to use ADD v2 to load data about invoices including invoice ID, customer ID, and total price.

Last Successfully Loaded Time Stamp
- The INVOICE output stage table (on the left) contains your source data. Note the
x__timestampcolumn that indicates when the records were created in the Output Stage table. - The corresponding INVOICE_DATA dataset (on the right) is the target dataset where the source data will be loaded to. It also shows load mode and Last Successfully Loaded Time Stamp (LSLTS).
- The ADD table (in the middle) shows when ADD v2 is triggered.
Let’s see how ADD v2 uploads the source data and applies load modes:
First run: ADD v2 runs on December 2, 2016, at 7:00 AM (2016-12-02 7:00:00). This is the first time ADD v2 runs in your workspace.
- ADD v2 checks the target dataset. As ADD v2 has not run before, LSLTS is not set (no initial state). Therefore, ADD v2 selects full mode for data load.
- ADD v2 checks the Output Stage table and finds three records that exist by the moment the ADD v2 process started:
cp__invoice_id100, 101, and 102 withx__timestampof 2016-12-01 0:00:00.000000, 2016-12-01 0:00:00.000000, and 2016-12-02 0:00:00.000000, correspondingly. - ADD v2 uploads the three records to the target dataset in full mode.
- In the target dataset, ADD v2 records the final state of LSLTS as the greatest value among
x__timestampof all the uploaded records. It is 2016-12-02 0:00:00.000000.

For the second time, ADD v2 runs on December 3, 2016, at 7:00 AM (2016-12-03 7:00:00).
- ADD v2 checks the target dataset and finds LSLTS for the last data load, which is 2016-12-02 0:00:00.000000. ADD v2 selects incremental mode for data load.
- ADD v2 checks the Output Stage table and finds three records that were created between the last LSLTS and now:
cp__invoice_id103, 101, and 104 withx__timestampof 2016-12-03 0:00:00.000000 for each of the records. Note that the record withcp__invoice_id101 was already uploaded in the first run and will be uploaded again in the second run, because the value off__totalpricehas changed from 109 to 119. Most likely, the invoice with ID 101 was first created with a wrong price (109) and was fixed the next day to the correct price (119). - ADD v2 uploads the three records to the target dataset in incremental mode.
- In the target dataset, ADD v2 records the final state of LSLTS as the greatest value among
x__timestampof all the uploaded records. Asx__timestampis the same for all the records, LSLTS is set to 2016-12-03 0:00:00.000000.

For the third time, ADD v2 runs on December 4, 2016, at 7:00 AM (2016-12-04 7:00:00).
- ADD v2 checks the target dataset and finds LSLTS for the last data load, which is 2016-12-03 0:00:00.000000. ADD v2 selects incremental mode for data load.
- ADD v2 checks the Output Stage table and finds one record that was created between the last LSLTS and now:
cp__invoice_id105 withx__timestampof 2016-12-04 0:00:00.000000. - ADD v2 uploads this record to the target dataset in incremental mode.
- In the target dataset, ADD v2 records the final state of LSLTS as the greatest value among
x__timestampof all the uploaded records. As only one record was uploaded, and itsx__timestampis 2016-12-04 0:00:00.000000, LSLTS is set to 2016-12-04 0:00:00.000000.

Overriding Incremental Load Mode
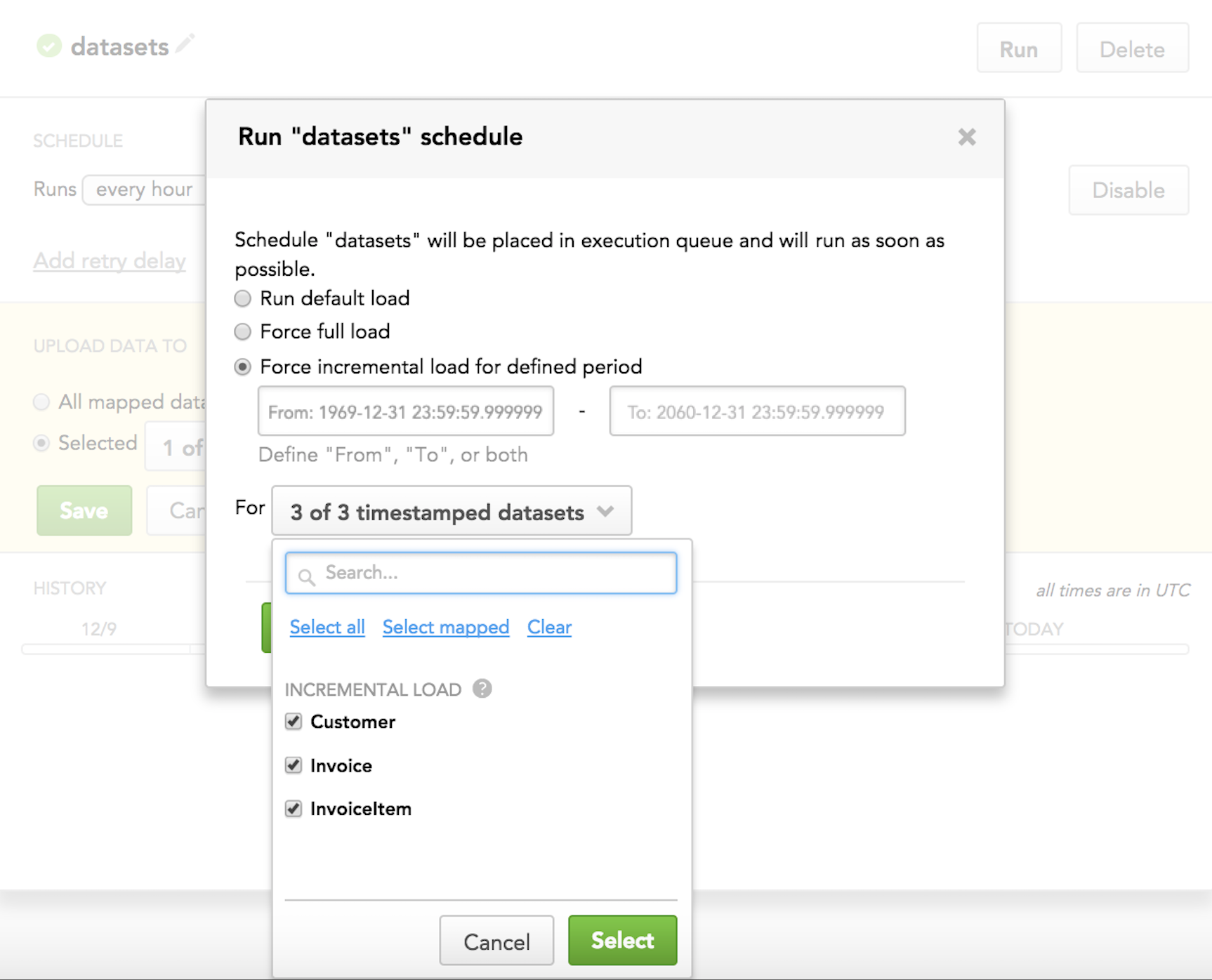
When you run a scheduled ADD v2 process (see Run a Scheduled Data Loading Process on Demand), you can override the pre-selected incremental load mode for particular datasets with full load mode (when you need to completely overwrite data in the datasets) or with loading data for a specific time interval.
Forcing full load:
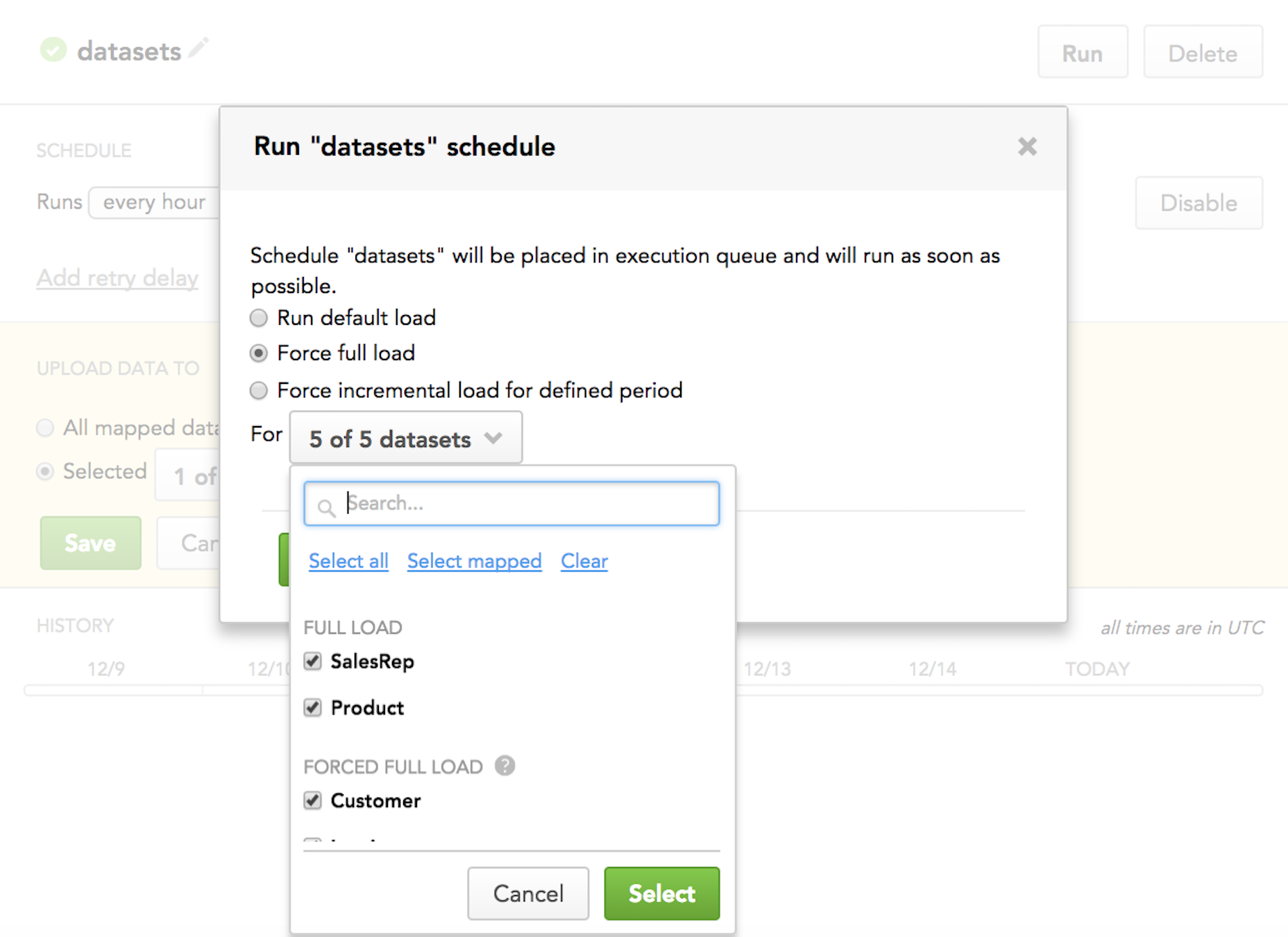
Forcing incremental load for a specific time interval:
Delete Mode
You can adjust your Output Stage to delete old or obsolete data from a dataset while loading new data to the dataset. When you delete old data and upload new data to datasets, deleting and uploading the data is done in a single transaction. This helps keep data in your workspace consistent and avoid situations when new data is already in the dataset but the old data are not yet removed.
The primary use case for deleting data using ADD v2 is to delete data during incremental load. ADD v2 deletes data using the data loading API (see Delete Old Data while Loading New Data to a Dataset via API).
To set up ADD v2 to be able to delete data:
- Update the structures in the Output Stage according to Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses.
- Add the
x__deletedcolumn to the data load table. Thex__deletedcolumn indicates whether a specific row should be deleted from the dataset when running data load.
Deleting data works in the following load modes:
- Incremental load: The data is processed in the following way:
- Data after a certain point in time (based on LSLTS, Last Successfully Loaded Time Stamp) where
x__deleted=FALSEis loaded to the datasets using theUPSERTmethod. - Data after a certain point in time (based on LSLTS) where
x__deleted=TRUEis deleted from the datasets.
- Data after a certain point in time (based on LSLTS, Last Successfully Loaded Time Stamp) where
- Full load: All data where
x__deleted=FALSEis loaded to the datasets. The datasets are completely rewritten.
Deleting by Connection Point
Imagine you have the following data in ADD v2:
Previously loaded data
| cp__invoice_id | r__customer | f__totalprice | x__timestamp | x__deleted |
|---|---|---|---|---|
| 100 | 3 | 324 | 2017-12-01 0:00:00.000000 | FALSE |
| 101 | 78 | 109 | 2017-12-01 0:00:00.000000 | FALSE |
New incremental data update
| cp__invoice_id | r__customer | f__totalprice | x__timestamp | x__deleted |
|---|---|---|---|---|
| 101 | 3 | NULL | 2017-12-02 0:00:00.000000 | TRUE |
cp__invoice_id is the connection point (CP) for the dataset.
Previously, you loaded data to the dataset by CP with invoice_id=101.
Now, you want to delete particular records from the dataset as a part of your data load. The data where invoice_id=101 will be deleted from the dataset.
Deleting by Fact Table Grain
Imagine you have the following data in ADD v2:
Previously loaded data
| a__ticket_id | a__organization | f__timespentsec | x__timestamp | x__deleted |
|---|---|---|---|---|
| 12345 | ABC company | 458 | 2017-12-01 0:00:00.000000 | FALSE |
| 12346 | CDE company | 11342 | 2017-12-01 0:00:00.000000 | FALSE |
New incremental data update
| a__ticket_id | a__organization | f__timespentsec | x__timestamp | x__deleted |
|---|---|---|---|---|
| 12345 | ABC company | NULL | 2017-12-02 0:00:00.000000 | TRUE |
Fact Table Grain (FTG) consists of the a__ticket_id and a__organization attributes.
Previously, you loaded data to the dataset by FTG with ticket_id=12345 and organization=ABC company.
Now, you want to delete particular records from the dataset as a part of your data load. The data where ticket_id=12345 AND organization=ABC company will be deleted from the dataset.
You do not have to explicitly specify FTG in the Output Stage table. When data load is running, the Output Stage table is compared to the logical data model, and FTG is automatically recognized.
Deleting by Attributes (no CP or FTG)
Imagine you have the following data in ADD v2:
Previously loaded data
| a__branch | a__organization | a__address | f__mrr | x__timestamp | x__deleted |
|---|---|---|---|---|---|
| NYC | ABC company | 5th avenue | 20000 | 2017-12-01 0:00:00.000000 | FALSE |
| LA | CDE company | 3rd street | 100000 | 2017-12-01 0:00:00.000000 | FALSE |
New incremental data update
| a__branch | a__organization | a__address | f__mrr | x__timestamp | x__deleted |
|---|---|---|---|---|---|
| NYC | ABC company | 5th avenue | 20000 | 2017-12-02 0:00:00.000000 | TRUE |
If no CP or FTG exists, data is deleted by all attributes (facts are ignored). For data to be deleted, all attribute values must match.
Previously, you loaded data to the dataset, and now you want to delete particular records from the dataset as a part of your data load. The data where branch=NYC AND organization=ABC company AND address=5th avenue will be deleted from the dataset.