Automated Data Distribution v2 for Data Warehouses
Automated Data Distribution (ADD) v2 for data warehouses is a feature of the GoodData platform that enables you to quickly upload data from a data warehouse (such as Snowflake, Redshift, or BigQuery) to one or multiple workspaces.
If you upload data from an object storage service, see Automated Data Distribution v2 for Object Storage Services.
ADD v2 supposes that you have already run all the needed transformations on top of the data in your data warehouse, and the data is ready to be distributed to your workspaces.
Distributing Data to Workspaces
Data distribution is a process of fetching data from your data warehouse and loading and distributing it to your customers' workspaces. This process ensures data separation at the workspace level.
You can distribute data to:
- Single workspace When you need to load data to a workspace with a specific logical data model (LDM), you can map all datasets from the LDM to the objects in the Output Stage using the naming convention (see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses).
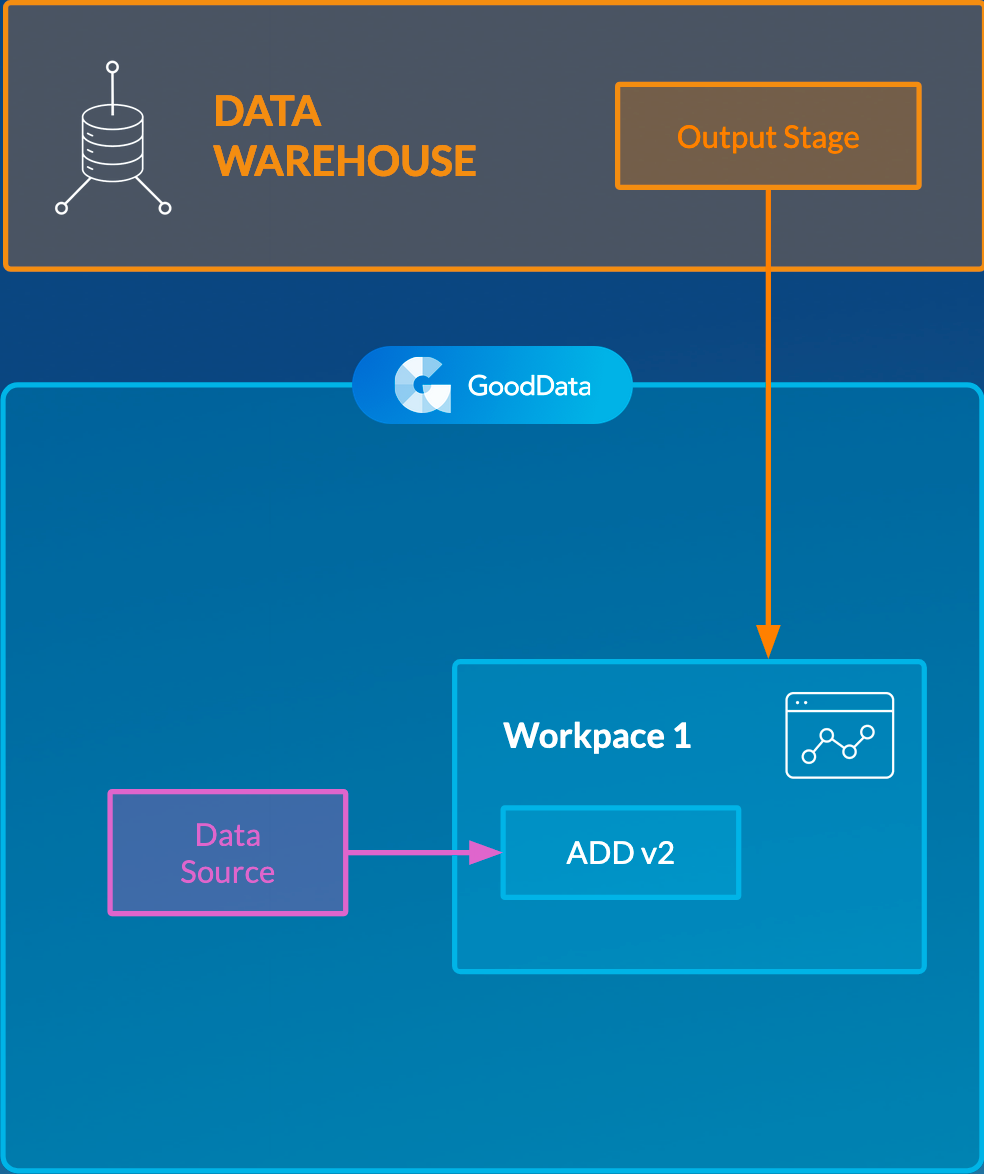
- Multiple workspaces ADD v2 uses the client ID to distinguish what data should be loaded to what workspace.
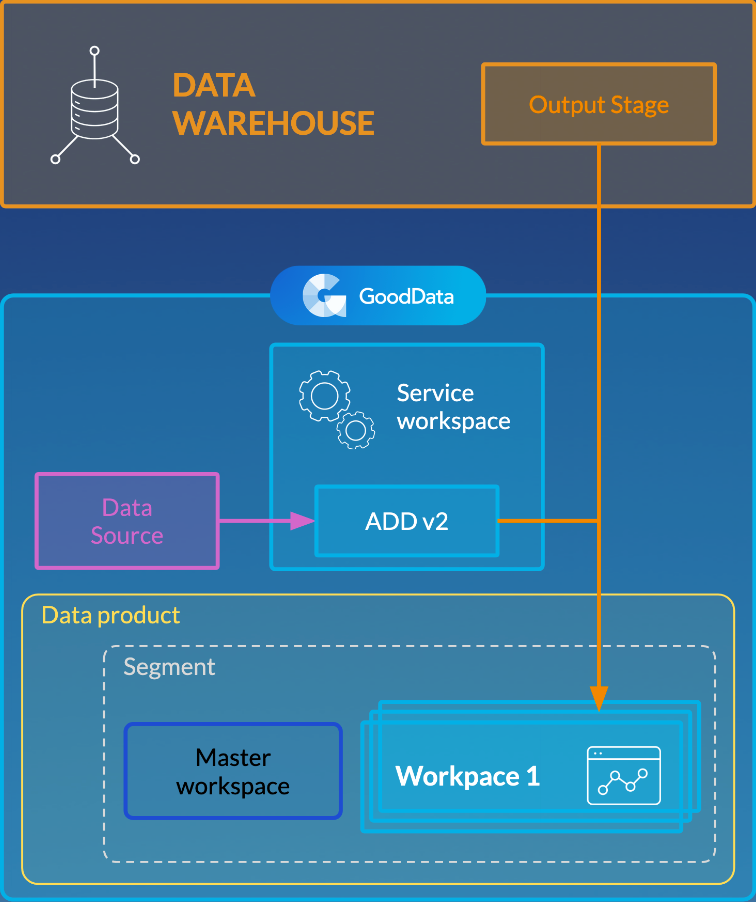
For more information about organizing your workspaces, see Set Up Automated Data Distribution v2 for Data Warehouses.
How Data Is Distributed Based on the Client ID
Use the client ID if you want to instruct ADD v2 what data should be loaded to what workspaces. ADD v2 then distributes data to your workspaces based on their client IDs.
Each client workspace is assigned a client ID. The data in your data warehouse contains the x__client_id column. For each data record, this column holds a value of the client ID that corresponds to one of the client IDs assigned to your client workspaces.
At data load, ADD v2 uses the client ID to distinguish what data should be loaded to what workspace. When the value in the x__client_id column for a data record matches the client ID of some client workspace, this record is loaded to this workspace.
The x__client_id column must contain a client ID value for each data record. If the x__client_id column is present but no client ID is specified, ADD v2 fails when the data is being loaded to the corresponding dataset.
In the following picture, the Opportunity table in the data warehouse holds records with information related to multiple workspaces. When the data is loaded to a workspace with a specific client ID, only the records whose value in the x__client_id column matches the workspace client ID are loaded to the workspace.
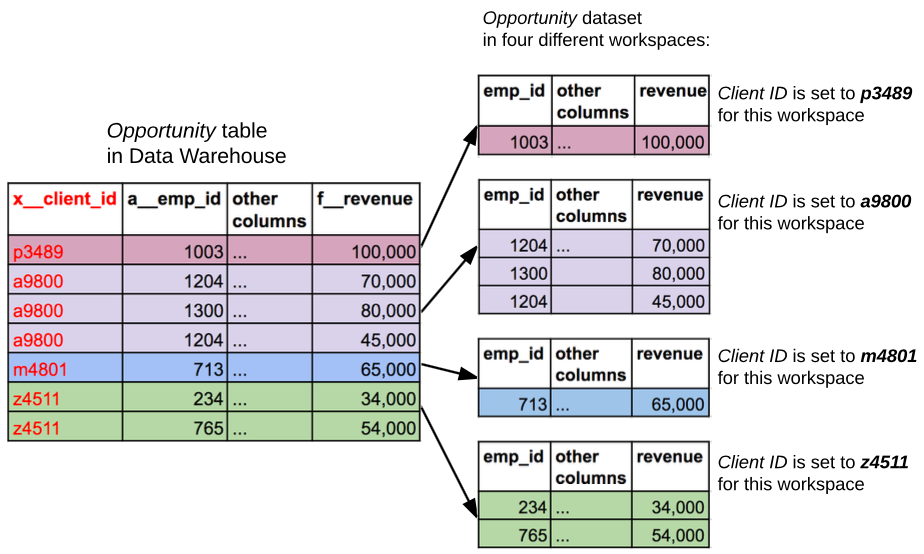
Client IDs in Workspaces
You assign the client ID to a workspace when assigning this workspace to a segment (see Set Up Automated Data Distribution v2 for Data Warehouses). Each workspace can have only one client ID assigned. The client ID must be unique within a segment. The client ID can be up to 255 characters long and can contain only numbers, lowercase and uppercase ASCII letters (a-z, A-Z), and underscores (_).
For Life Cycle Management setup (LCM; see Managing Workspaces via Life Cycle Management), LCM acts as an authority, and the client ID is defined within the LCM hierarchy. The client ID within the Output Stage is ignored. If this behavior is unwanted, contact GoodData Support.
Distributing Data to All Client Workspaces
If you want to load data from an Output Stage table/view to all client workspaces, do not add the x__client_id column to this table/view. When the x__client_id column is not present, ADD v2 does not do any filtering and loads the data to all workspaces.
Output Stage and Output Stage Prefix
The Output Stage is a set of tables and/or views that will serve as a source for loading data to your workspaces. For more information about the Output Stage, see Direct Data Distribution from Data Warehouses and Object Storage Services.
Objects (tables and/or views) in the Output Stage are identified by a special prefix, the Output Stage prefix. This prefix distinguishes the Output Stage objects from the objects belonging to other logical areas of your data warehouse. By default, the Output Stage prefix is out_.