User Filters Brick
The user filters brick lets you manage user access to the data in a workspace based on data filters.
Data filters limits data visible to a user based on some attribute. In MAQL, it is what comes after WHERE, but applied per user:
WHERE city IN ('San Francisco', 'Prague', 'Amsterdam')
For information about how to use the brick, see How to Use a Brick.
Prerequisites
Before using the user filters brick, make sure that the following is true:
- A domain is implemented at your site.
- A workspace admin exists in your domain.
User Filters and Admins
When setting user filters in GoodData, ensure that the admin user executing the brick does not have any user filters applied. User filters limit visible values in the workspace, and since filters can only be set for values currently visible to the user, applying filters to the admin can restrict their ability to set additional filters. To avoid issues, always execute the brick under a user with no filters applied.
How the Brick Works
The user filters brick sets the data permissions according to the input source data.
The output data permissions would look similar to the following:
john@example.com: WHERE city IN ('San Francisco', 'Prague', 'Amsterdam')
anna@example.com: WHERE city IN ('San Francisco', 'Dublin')
Input
The user filters brick expects to receive data about what user should have what filter or permission.
The input data must be in the column-based format. The column-based format is the most common format. You can get this kind of the input data as a result of JOIN.
To understand this format, let’s use an example. Imagine that you have two users in your system, and you want to set up the following filters for them:
| login | filter |
|---|---|
john@example.com | WHERE city ('San Francisco', 'Prague', 'Amsterdam') |
anna@example.com | WHERE city ('San Francisco', 'Dublin') |
In the column-based format, you input data would look similar to the following:
| login | city | other_unused_value |
|---|---|---|
| john@example.com | San Francisco | x |
john@example.com | Prague | x |
john@example.com | Amsterdam | y |
anna@example.com | San Francisco | y |
anna@example.com | Dublin | y |
Notice that multiple values for the filter are expressed by repeating the user. The brick will remove duplicates during processing.
Regardless of the format of source data, the input data must define how the data filters should look like after the brick completes. That is, the input data will be used as the blueprint for the end (desired) state of data filters. It is very similar to how updating a workspace/domain works for users (for details, see Users Brick).
In addition, you have to add the parameters when scheduling the brick process.
Parameters
When scheduling the deployed brick (see How to Use a Brick and Schedule a Data Load), add parameters to the schedule.
In GoodData, terms workspace and project denote the same entity. For example, project ID is exactly the same as workspace ID. See Find the Workspace ID.
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| organization | string | yes | n/a | The name of the domain where the brick is executed |
input_source | JSON | yes | n/a | The source to take input data from. For more information on input data JSON structures, see Types of Input Data Sources. You must encode this parameter using the Example: |
filters_config | JSON | yes | n/a | See filters_config. |
| users_brick_config | JSON | yes | n/a | See users_brick_config. |
csv_headers | Boolean | no | true | See csv_headers. |
sync_mode | string | no | sync_ project | See sync_mode. |
restrict_if_missing_ all_values | Boolean | no | false | See ignore_missing_values and restrict_if_missing_all_values. |
ignore_missing_values | Boolean | no | false | |
do_not_touch_filters_ that_are_not_mentioned | Boolean | no | false | |
| data_product | string | no | default | The data product that contains the segments that you want to release If the specified data product does not exist, it is created. |
| skip_actions | array | no | n/a | The actions or steps that you want the brick to skip while executing (for example, collecting data products) The specified actions and steps will be excluded from the processing and will not be performed. NOTE: Using this parameter in a wrong way may generate unexpected side effects. If you want to use it, contact the GoodData specialist who was involved in implementing LCM at your site. |
filters_config
The filters_config parameter defines what data to take from the input source and how to process it. How you set this parameter depends on the format of your input data.
You must encode this parameter using the gd_encoded_params parameter (see Specifying Complex Parameters).
Let’s again use the data we discussed in input and see how this parameter differs depending on the input data format.
Set the filters_config parameter in the following way:
{
"filters_config": {
"user_column": "login",
"labels": [{
"label": "label.cities.city_id.name",
"column": "city"
}]
}
}
In this example:
- The
user_columnkeyword specifies what column in the source input data to take users from. In our example, it is the “login” column. - The
labelskeyword specifies an array of other keywords:- The
labelkeyword specifies the attribute by whose values a user’s access to the data will be limited. This attribute must exist in your workspace data. In our example, it islabel.cities.city_id.name. - The
columnkeyword specifies what column in the input data to take filter values from. In our example, it is the “city” column.
- The
If your input data does not have headers, do the following:
Use numbers (1, 2) to specify the
user_columnorcolumnkeywords.Set the
csv_headersparameter tofalse(see csv_headers for more information).{ "filters_config": { "user_column": 1, "labels": [{ "label": "label.cities.city_id.name", "column": 2 }] }, "csv_headers": false }
You will still need to set the label keyword to specify the attribute by whose values a user’s access to the data will be limited.
If there are too many (hundreds) individual filter values that need to be set up for each user, having them in one filter may not be efficient. In such case, you can use the over keyword.
To do so, set up a dataset that contains all the values, and then configure the filter to look for the values in that dataset. When pointing to specific attribute values, you can use either object identifiers (recommended to maintain persistence) or URIs.
Object identifiers:
{
"filters_config": {
"user_column": "login",
"labels": [{
"label": "label.cities.city_id.name",
"column": "city",
"over": "attr.cities.city_id.obj", "to": "attr.cities.city_id.num"
}]
}
}
URIs:
{
"filters_config": {
"user_column": "login",
"labels": [{
"label": "label.cities.city_id.name",
"column": "city",
"over": "/gdc/md/e863ii0azrnng2zt4fuu81ifgqtyeoj21/obj/2022", "to": "/gdc/md/e863ii0azrnng2zt4fuu81ifgqtyeoj21/obj/2023"
}]
}
}
- The advantage of using
overis that it can handle more values and also simplifies the filters. - The disadvantage is that you have to add additional datasets to the logical data model, which may complicate it and is not always possible.
For more information, see Advanced Data Permissions Use Cases and Platform Limits: Data Permissions.
users_brick_config
The users_brick_config parameter keeps the filters for the users who will be deleted by the users brick (see Users Brick); that is, the users who are not present in the input.
You must encode this parameter using the gd_encoded_params parameter (see Specifying Complex Parameters).
This parameter contains the input_source and login_column parameters from the users brick (see “Parameters” in Users Brick).
{
"users_brick_config": {
"input_source": {
<content_from_input_source_from_users_brick>
},
"login_column": "{your_login_column_name}"
}
}
For example, if the users brick takes the input data from an Amazon S3 bucket and the name of the column in the input data containing users' logins is “login”, set the users_brick_config parameter in the following way:
{
"users_brick_config": {
"input_source": {
"type": "s3",
"key": "/folder/users.csv",
"bucket": "users_data"
},
"login_column": "login"
}
}
If you do not use the users brick, set the input_source and login_column parameters to the same values that you are already using for the user filters brick (see Input and Parameters).
csv_headers
The csv_headers parameter makes the brick ignore the headers in the input data.
This parameter is Boolean and takes values of true or false. By default, this parameter is set to true and looks for the headers.
Explicitly set this parameter to false when your input data does not have headers (see the example of such input data in filters_config).
sync_mode
The sync_mode parameter specifies the synchronization mode for the user filters. The values that this parameter can take on are similar to those in the users brick (see “sync_mode” in Users Brick).
You can choose from the following recommended synchronization modes:
sync_domain_client_workspacessync_multiple_projects_based_on_pid
The following advanced modes are available but should be used in very specific cases only:
sync_one_project_based_on_custom_idsync_multiple_projects_based_on_custom_idsync_projectsync_one_project_based_on_pid
There are more modes available for the users brick: add_to_organization, remove_from_organization, and sync_domain_and_project. They are not applicable to the user filters brick.
ignore_missing_values and restrict_if_missing_all_values
These two parameters work together.
- The
ignore_missing_valuesparameter prevents the brick from failing when none of filter values set for a user is found in the workspace data. - The
restrict_if_missing_all_valuesparameter restricts access to all workspace data to the users whose filter values were not found in the workspace data.
If the labels configured in filters_config do not exist in the client workspace and if the ignore_missing_values parameter is set to true, the brick ignores settings of the filter values, logs them as a warning, and continues with the next input from the user filter input. No error is logged.
If the ignore_missing_values parameter is set to false, the brick logs these missing labels, but exits the execution.
Both parameters are Boolean and take values of true or false. By default, both parameters are set to false.
Let’s look at an example to explain how these parameters work. Imagine you want to set up the following:
john@example.com: WHERE city IN ('San Francisco', 'Prague')
Let’s say that the attribute value Prague cannot be found in the workspace data for some reason. In this case, the brick will try setting up the filter to San Francisco only. The fact that the value of Prague is not in the filter does not matter because Prague is not in the workspace data anyway.
It’s different when neither Prague nor San Francisco is found in the workspace data. The result filter would be then:
john@example.com: WHERE city IN ()
which is invalid, so the brick will fail.
This is the default behavior. However, you can override this.
By setting ignore_missing_values to true, you instruct the brick to simply drop the filter altogether when none of filter values is found, and to proceed normally.
"ignore_missing_values": "true"
In this case, the users with dropped filters will have no filters assigned thus have full access to the workspace data.
In some cases, granting such users full access is not acceptable. To prevent this, additionally set restrict_if_missing_all_values to true. In this case, the brick will drop the filter altogether when none of filter values is found, but the users with dropped filters will have no access to the workspace data.
"ignore_missing_values": "true",
"restrict_if_missing_all_values": "true"
do_not_touch_filters_that_are_not_mentioned
The do_not_touch_filters_that_are_not_mentioned parameter excludes from processing the filters that are not explicitly specified in the input data.
This parameter is Boolean and takes values of true or false. By default, this parameter is set to false.
Use this parameter when you need to remove some users from the workspace. If you first remove the users' filters and then remove the users themselves, there will be a time gap in between when the users can potentially access some data that they should not see.
In this case, follow this process:
Run the user filters brick to add new filters and update the existing ones. In this brick, set
do_not_touch_filters_that_are_not_mentionedtotrue. It will prevent the brick from removing the filters that are not in the input data (because the input data must define how the data filters should look like after the brick completes (see Input))."do_not_touch_filters_that_are_not_mentioned": "true"Run the users brick (see Users Brick) to add or remove the users. The users are removed from the workspace, but their filters are still there.
Run the user filters brick again, this time with
do_not_touch_filters_that_are_not_mentionedset tofalse. This will remove the filters of the users that have been removed at the previous step."do_not_touch_filters_that_are_not_mentioned": "false"
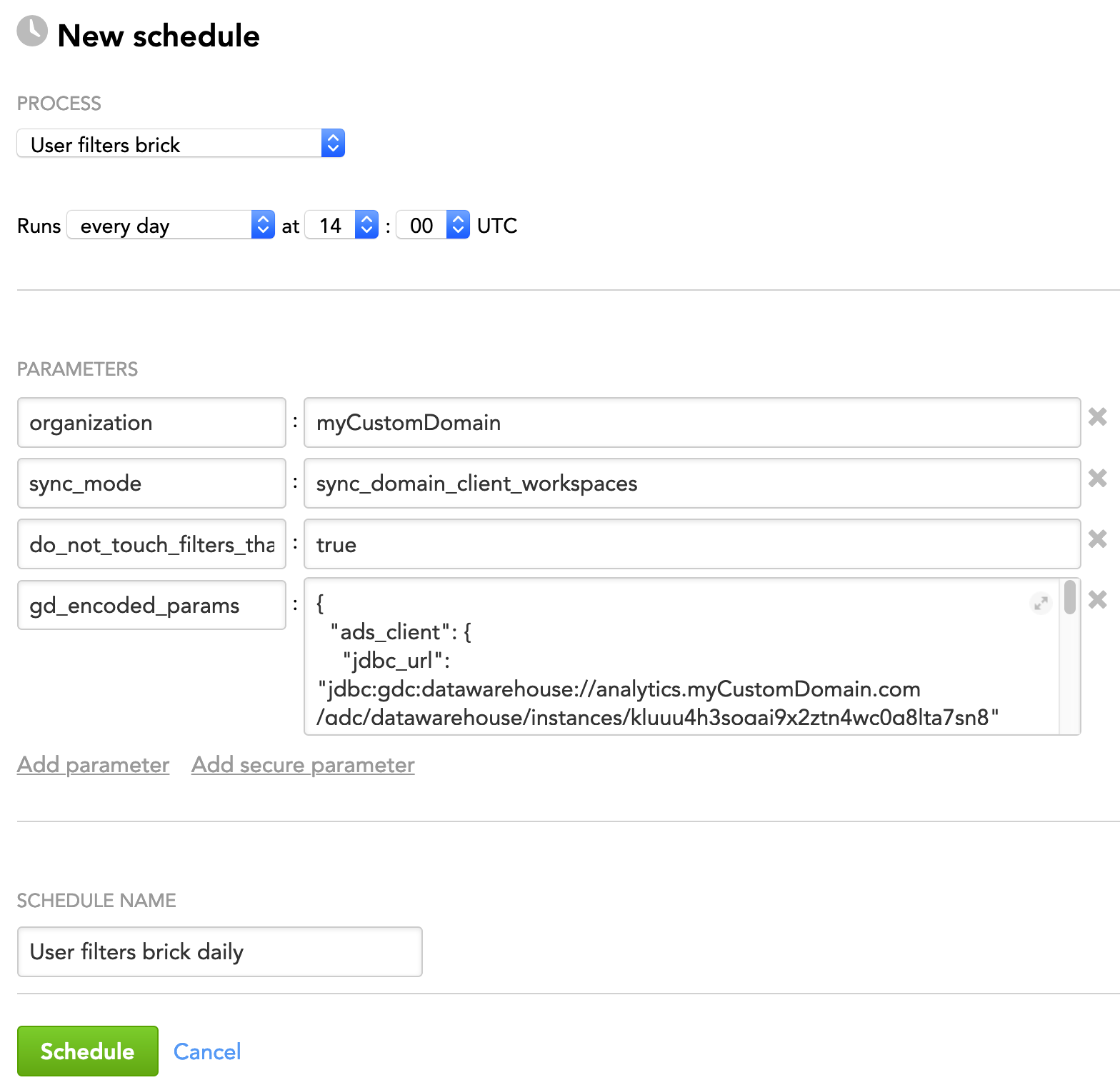
Example - Brick Configuration
The following is an example of configuring the brick parameters in the JSON format:
{
"organization": "myCustomDomain",
"sync_mode": "sync_domain_client_workspaces",
"do_not_touch_filters_that_are_not_mentioned": true,
"gd_encoded_params": {
"ads_client": {
"jdbc_url": "jdbc:gdc:datawarehouse://analytics.myCustomDomain.com/gdc/datawarehouse/instances/kluuu4h3sogai9x2ztn4wc0g8lta7sn8"
},
"input_source": {
"type": "ads",
"query": "SELECT * FROM domain_users"
},
"filters_config": {
"user_column": "login",
"labels": [{
"label": "label.cities.city_id.name",
"column": "city"
}]
},
"users_brick_config": {
"ads_client": {
"jdbc_url": "jdbc:gdc:datawarehouse://analytics.myCustomDomain.com/gdc/datawarehouse/instances/kluuu4h3sogai9x2ztn4wc0g8lta7sn8"
},
"input_source": {
"type": "ads",
"query": "SELECT * FROM domain_users"
},
"login_column": "login"
}
}
}