Rollout Brick
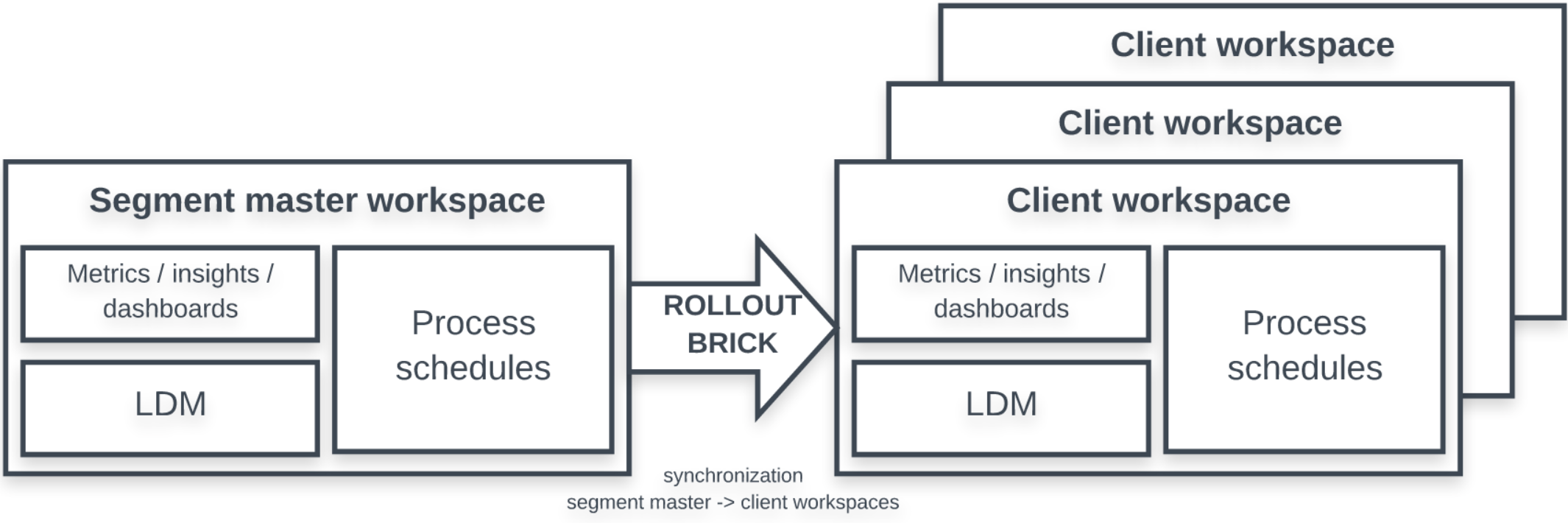
The rollout brick synchronizes all the client workspaces (logical data model (LDM), data loading processes, dashboards, reports, metrics, and so on) in the synchronized segments with the latest version of the segment’s master workspace.
For information about how to use the brick, see How to Use a Brick.
Prerequisites
Before using the rollout brick, make sure that the following is true:
- The release brick (see Release Brick) and the provisioning brick (see Provisioning Brick) have been executed.
- The segments have been created and associated with the clients.
How the Brick Works
The rollout brick synchronizes all the client workspaces (LDM, data loading processes, dashboards, reports, metrics, and so on) in the synchronized segments with the latest version of the segment’s master workspace. The latest version of the segment’s master workspace is the one that the release brick (see Release Brick) created at its last execution.
The segments to synchronize are specified in the segments_filter parameter.
Rollout Brick and Custom Fields in the LDM
If you have custom fields set up in the LDM, consider the following:
- If you use Object Renaming Utility to set up custom fields in the LDM of a segment’s master workspace (see Object Renaming Utility), you may need to run Object Renaming Utility after the rollout brick in case it changes the field names back to the default ones in the client workspaces.
- If you have custom fields in the LDMs of the client workspaces and want to preserve them during the rollout, add the synchronize_ldm parameter to the scheduled rollout brick process and set it to
diff_against_master. For more information, see Add Custom Fields to the LDMs in Client Workspaces within the Same Segment.
Rollout and Provisioning Metadata
Client synchronization creates metadata objects on the GoodData platform. These objects are then used during provisioning.
These objects are automatically cleaned up three years after the synchronization/rollout process was last executed.
To prevent issues with provisioning related to the missing metadata objects, always keep the production master workspace synchronized with the production client workspaces. Use a different workspace for development.
Input
The rollout brick does not require any input besides the parameters that you have to add when scheduling the brick process.
Parameters
When scheduling the deployed brick (see How to Use a Brick and Schedule a Data Load), add parameters to the schedule.
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| organization | string | yes | n/a | The name of the domain where the brick is executed |
| segments_filter | array | yes | n/a | The segments that you want to roll out You must encode this parameter using the Example: |
| ads_client | JSON | see "Description" column | n/a | (Only if your input source resides on GoodData Data Warehouse (ADS)) The ADS instance where the You must encode this parameter using the Example: |
| data_product | string | no | default | The data product that contains the segments that you want to roll out NOTE: If your input source resides on ADS and you have two or more data products, use the |
| release_table_name | string | see "Description" column | LCM_RELEASE | (Only if your input source resides on ADS and you have multiple data products stored in one ADS instance) The name of the table in the ADS instance where the latest segment's master workspace IDs and versions are stored |
| technical_users | array | no | n/a | The users that are going to be added as admins to each client workspace The user logins are case-sensitive and must be written in lowercase. You must encode this parameter using the Example: |
| disable_kd_dashboard_permission | Boolean | no | false | Shared dashboard permissions for user groups are enabled by default. Even when the parameter is not explicitly specified in the syntax, it is assumed. Set to true to disable synchronizing user group permissions for shared dashboards. For more information, see LCM and Shared Dashboards. |
| update_preference | JSON | no | n/a | See update_preference. |
LCM and Shared Dashboards
In a segment’s master workspace, dashboards can be private or shared with all or some users/user groups.
The sharing permissions are propagated from the master workspace to the client workspaces in the following way:
- Dashboards set as private in the master workspace remain private in the client workspaces.
- Dashboards shared with all users in the master workspace become dashboards shared with all users in the client workspaces.
- Dashboards shared with some users/user groups in the master workspace become dashboards shared with some user groups in the client workspaces.
Only user group permissions on the master workspace are preserved during rollout. Because the permission sharing a dashboard in the master workspace with some users is not preserved during rollout, we recommend that the master workspace contain only the dashboards that can be safely shared with all users in the client workspaces. If access is given to a user directly on the client workspace, the LCM will not remove that permission.
In some cases, you might want to keep private dashboards in the master workspace knowing that they will remain private in the client workspaces (for example, if they are used only as target dashboards in drilling).
In addition to the sharing permissions, the dashboards can be configured:
- To allow only administrators to update the dashboards (that is, editors cannot update such dashboards)
- To be displayed to users when they drill to these dashboards from facts, metrics, and attributes, even if the dashboards are not explicitly shared with those users
These settings are propagated to the client workspaces exactly as they are set in the master workspace. For more information about these settings, see Share Dashboards.
update_preference
The update_preference parameter specifies the properties of MAQL diffs when propagating data from the master workspace to the clients' workspaces.
The update_preference parameter is set up in JSON format. You must encode this parameter using the gd_encoded_params parameter (see Specifying Complex Parameters).
The parameter is defined by the following JSON structure:
"update_preference": {
"allow_cascade_drops": true|false,
"keep_data": true|false,
"fallback_to_hard_sync": true|false
}
allow_cascade_drops: If set totrue, the MAQL diff uses drops with thecascadeoption. These drops transitively delete all dashboard objects connected to the dropped LDM object. Set it totrueonly if you are certain that you do not need metrics, reports, or dashboards that use the dropped object.keep_data: If set totrue, the MAQL diff execution does not truncate the data currently loaded in datasets included in the diff.fallback_to_hard_sync: If set totrue, the MAQL diff execution does not truncate the data currently loaded in datasets included in the diff. If the MAQL diff execution fails, it executes again and truncates the data currently loaded in the datasets.The default value is
false. If the datasets do not need hard synchronization, we recommend to use the default value or ignore the parameter.
By default, the update_preference parameter is set to the following, which is the least invasive scenario:
"update_preference": {
"allow_cascade_drops": false,
"keep_data": true,
"fallback_to_hard_sync": false
}
We recommend that you use the default configuration and set it up explicitly in the brick schedule. This way, you will be able to easily locate this parameter in your schedule and update it as needed in case of a failure.
The following are possible scenarios of how you can set up the update_preference parameter depending on how you want the brick to behave:
You define neither
allow_cascade_dropsnokeep_data. The brick will be using the MAQL diffs starting from the least invasive scenario (the default configuration) towards the most invasive one until the MAQL diff succeeds."update_preference": { }You define only
keep_dataand do not setallow_cascade_dropsexplicitly. The brick will first try to use the MAQL diffs withallow_cascade_dropsset tofalseas a less invasive alternative. If it fails, the brick will tryallow_cascade_dropsset totrue."update_preference": { "keep_data": false|true }You set
allow_cascade_dropstotrueand do not setkeep_dataexplicitly. The brick will first try to use the MAQL diffs withkeep_dataset totrueas a less invasive alternative. If it fails, the brick will trykeep_dataset tofalse."update_preference": { "allow_cascade_drops": true }You set
allow_cascade_dropstotrueand setkeep_datatofalse. This is the most invasive scenario. Use it carefully."update_preference": { "allow_cascade_drops": true, "keep_data": false }You set
fallback_to_hard_synctotrue, and setallow_cascade_dropsandkeep_datatofalse. The brick will execute hard synchronize."update_preference": { "allow_cascade_drops": false, "keep_data": false, "fallback_to_hard_sync": true }
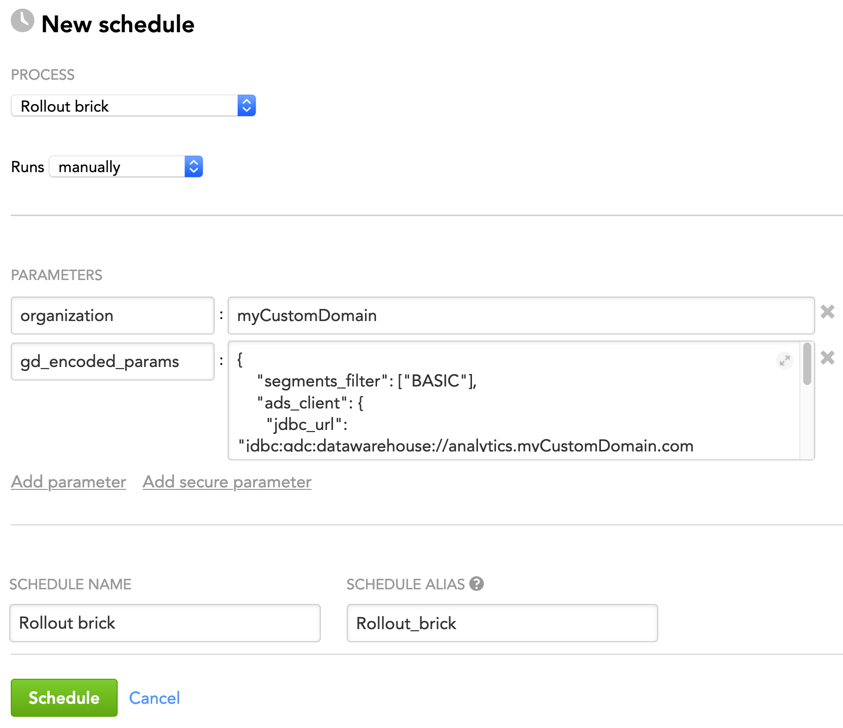
Example - Brick Configuration
The following is an example of configuring the brick parameters in the JSON format:
{
"organization": "myCustomDomain",
"gd_encoded_params": {
"segments_filter": ["BASIC"],
"ads_client": {
"jdbc_url": "jdbc:gdc:datawarehouse://analytics.myCustomDomain.com/gdc/datawarehouse/instances/kluuu4h3sogai9x2ztn4wc0g8lta7sn8"
},
"update_preference": {
"allow_cascade_drops": false,
"keep_data": true
}
}
}
Advanced Settings
This section describes advanced settings of the rollout brick.
Change these settings only if you are confident in executing the task or have no other options. Adjusting the advanced options in a wrong way may generate unexpected side effects.
Proceed with caution.
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| dynamic_params | JSON | no | n/a | See "Advanced Settings" in Provisioning Brick. |
| metric_format | JSON | no | n/a | See metric_format. |
| delete_extra_process_schedule | Boolean | no | true | Specifies how the brick should process the processes or schedules that are either not present in the master workspace or have been renamed in the master workspace
|
| keep_only_previous_masters_count | integer | no | n/a | The number of previous versions of the segment's master workspace to keep (the latest version not included) while all the remaining versions will be deleted. Example: Imagine that you have six versions of the master workspace, version 6 being the most recent version and version 1 being the oldest one. If you set this parameter to NOTE:
|
| exclude_fact_rule | Boolean | no | false | Specifies whether to skip number format validation (up to 15 digits, including maximum 6 digits after the decimal point).
|
| synchronize_ldm | string | no | diff_against_master_with_fallback | Specifies how the brick synchronizes the logical data model (LDM) of the master workspaces and their corresponding client workspaces. The brick checks the LDM of a client workspace and determines whether a MAQL diff should be applied and what the DDL statement should be. Possible values:
NOTE: Set this parameter to |
| include_deprecated | Boolean | no | false | Specifies how to handle deprecated objects in the logical data model (LDM) while the one in a client workspace is being synchronized with the latest version of the segment's master workspace
NOTE: If the LDM of the master workspace or any client workspace include deprecated objects, we recommend that you set the |
| include_computed_attributes | Boolean | no | true | Specifies whether to include computed attributes (see Use Computed Attributes) in the logical data model (LDM).
|
| skip_actions | array | no | n/a | The actions or steps that you want the brick to skip while executing (for example, synchronizing computed attributes or collecting dynamically changing parameters) The specified actions and steps will be excluded from the processing and will not be performed. NOTE: Using this parameter in a wrong way may generate unexpected side effects. If you want to use it, contact the GoodData specialist who was involved in implementing LCM at your site. |
| abort_on_error | Boolean | no | true | Specifies whether the
The brick results in one of the following:
|
metric_format
The metric_format parameter lets you specify a custom number format for metrics in each client workspace. For example, you can set up different currency codes for client workspaces with data from different countries (USD for the clients operating in the USA, EUR for the clients operating in Germany, and so on).
For more information about the number formatting, see Formatting Numbers in Insights.
A custom format is applied to the metrics in a specific client workspace based on tags that you add to the metrics in advance. The custom format is applied everywhere where a number format is used in the GoodData Portal (see GoodData Portal). The custom format does not rewrite the format that is defined for a metric in a specific report/insight (for more information about setting a number format in a report/insight, see Formatting Table Values Using the Configuration Pane and Format Numbers).
You can also use the metric_format parameter in Provisioning Brick.
Steps:
Add tags to the metrics that you want to apply a custom format to (see Add a Tag to a Metric). For example, you can use
format_#to tag metrics using the COUNT function,format_$to tag currency metrics,format_%to tag metrics with percentages.Create a table that maps the tags to number formats and the client IDs of the client workspaces where the number formats should be applied. Name the table columns
tag,format, andclient_id, respectively.tag format client_id format_# [>=1000000000]#,,,.0 B;
[>=1000000]#,,.0 M;
[>=1000]#,.0 K;
[>=0]#,##0;
[<0]-#,##0
client_id_best_foods format_% #,##0% client_id_zen_table format_% #,#0% client_id_best_foods The table can have more columns. Those extra columns will be ignored at processing.Save the table in a supported location (see Types of Input Data Sources):
- If you use a data warehouse (for example, ADS, Snowflake or Redshift), save the table as a database table named
metric_formats. - If you use a file storage (for example, S3, Azure Blob Storage or a web location), save the table as a CSV file named
metric_formats.csv.
- If you use a data warehouse (for example, ADS, Snowflake or Redshift), save the table as a database table named
Create the JSON structure for the
metric_formatparameter, and add it to the brick schedule. Because it is a complex parameter, include it in yourgd_encoded_paramsparameter (see Example - Brick Configuration). Themetric_formatparameter must contain a query for themetric_formatsdatabase table in the data warehouse or point to themetric_formats.csvfile in the file storage.The
metric_formatstable is located in a data warehouse.The
typeparameter specifies the data warehouse used (see Types of Input Data Sources).The
queryparameter nested directly under theinput_sourceparameter is intentionally blank and is ignored at processing."gd_encoded_params": { ... "input_source": { "type": "{data_warehouse}", "query": "", "metric_format": { "query": "SELECT client_id, tag, format FROM metric_formats;" } } }For example, in ADS:
"gd_encoded_params": { ... "input_source": { "type": "ads", "query": "", "metric_format": { "query": "SELECT client_id, tag, format FROM metric_formats;" } } }Or, in Redshift:
"gd_encoded_params": { ... "input_source": { "type": "redshift", "query": "", "metric_format": { "query": "SELECT client_id, tag, format FROM metric_formats;" } } }The
metric_formats.csvfile is located in a file storage.The
typeparameter specifies the file storage used (see Types of Input Data Sources).The parameter nested under the
metric_formatparameter must point to themetric_formats.csvfile in the file storage. The name of this parameter depends on the file storage used. For example, it isfilefor an S3 bucket andurlfor a web location (see Types of Input Data Sources). The parameter with the same name nested directly under theinput_sourceparameter is intentionally blank and is ignored at processing."gd_encoded_params": { ... "input_source": { "type": "{file_storage}", "{file_locator}": "", "metric_format": { "{file_locator}": "{location_of_metric_formats.csv}" } } }For example, in an S3 bucket:
"gd_encoded_params": { ... "input_source": { "type": "s3", "file": "", "metric_format": { "file": "/data/upload/metric_formats.csv" } } }Or, in a web location:
"gd_encoded_params": { ... "input_source": { "type": "web", "url": "", "metric_format": { "url": "https://files.acme.com/data/upload/metric_formats.csv" } } }