Reuse Parameters in Multiple Data Loading Processes
When you have multiple data loading processes (for example, multiple bricks in your data preparation and distribution pipeline, or multiple Life Cycle Management (LCM) bricks, or multiple processes for direct data distribution), you can define parameters for the processes only once, in a dedicated Data Source (for example, path to your Amazon S3 bucket and access credentials), and then simply reuse them in as many processes as you need.
Reusing parameters helps you set up data loading processes faster: just select the appropriate Data Source when deploying a process, and the process will automatically retrieve the parameters from the Data Source. Also, if you rotate the credentials, you do not have to then update them for each process separately. Just update them in the appropriate Data Source, and the processes will automatically pick them up at the next run.
You can set up the following Data Sources:
- Google BigQuery Data Source, where you can specify the properties of your Google BigQuery data warehouse. Use this Data Source primarily when setting up direct data distribution from a BigQuery data warehouse instance (see Direct Data Distribution from Data Warehouses and Object Storage Services). You can also use it for referencing parameters in the bricks in your data preparation and distribution pipeline or in your LCM bricks (see Bricks).
- Amazon Redshift Data Source, where you can specify the properties of your Amazon Redshift data warehouse. Use this Data Source primarily when setting up direct data distribution from a Redshift data warehouse instance (see Direct Data Distribution from Data Warehouses and Object Storage Services). You can also use it for referencing parameters in the bricks in your data preparation and distribution pipeline or in your LCM bricks (see Bricks).
- Snowflake Data Source, where you can specify the properties of your Snowflake data warehouse. Use this Data Source primarily when setting up direct data distribution from a Snowflake data warehouse instance (see Direct Data Distribution from Data Warehouses and Object Storage Services). You can also use it for referencing parameters in the bricks in your data preparation and distribution pipeline or in your LCM bricks (see Bricks).
- Amazon S3 Data Source, where you can specify the properties of your S3 bucket. Use this Data Source:
- When setting up direct data distribution from an Amazon S3 bucket - to define parameters for the S3 bucket where your source files are stored (see Direct Data Distribution from Data Warehouses and Object Storage Services).
- When setting up a data preparation and distribution pipeline - to define parameters for the S3 bucket where your configuration file is stored and/or for the S3 buckets where you store the source data for the bricks (see Data Preparation and Distribution Pipeline).
- To reference parameters in your LCM bricks (see Bricks).
- Generic Data Source, where you can specify any parameter as a key/value pair. Use this Data Source to define, for example, access credentials for an ADS instance or a WebDAV location. You can then reference the parameters in the bricks in your data preparation and distribution pipeline or your LCM bricks.
Consider the following limitations:
- Your parameters cannot have a value that contains the
${string. Such values will be treated as a reference to a Data Source parameter, which is built as${data_source_alias.parameter_name}. The GoodData platform will try to resolve this value as a parameter reference, and the execution will fail. - If you have Life Cycle Management (LCM; see Managing Workspaces via Life Cycle Management) at your site, you will not be able to use the Release brick to copy Data Sources between domains.
How to Reuse Parameters in Multiple Processes
This is how this works:
For direct data distribution, create Data Sources for BigQuery, Redshift, or Snowflake data warehouse instances or S3 buckets depending on where you want to load data from.
For the data preparation and distribution pipeline:
- Create a Data Source for the S3 location where your configuration file is stored (you may or may not also use this S3 location to store the source data). This Data Source will hold the parameters of that S3 location (bucket path, access credentials, and so on). Because each brick in your data distribution pipeline needs to use the configuration file, you will later set up all your bricks to reference the parameters from this Data Source.
- If you have a different S3 location where you store the source data, create another Data Source for this S3 location. The bricks that obtain the source data from that S3 location will reference parameters from this Data Source.
- If you have a different location than S3 where you store the source data (for example, a WebDAV location for CSV Downloader or a Google Analytics account for Google Analytics Downloader), create a generic Data Source for this location. The bricks that obtain the source data from that location will reference parameters from this Data Source.
- If you want your bricks to reference parameters related to an ADS instance (ID, username, and so on), create a generic Data Source for the ADS instance. The bricks that need to access and use the ADS instance will reference parameters from this Data Source.
For LCM, create any Data Source that you want to reuse parameters from.
- For direct data distribution, select the Data Source for the appropriate data warehouse or S3 bucket.
- For the data preparation and distribution pipeline:
- For each process, select the S3 Data Source for the configuration file in the deployment dialog. This will allow the process to use the parameters from this Data Source to access the configuration file.
- If the process needs to use parameters from another Data Source (for example, it downloads the source data from a different S3 location), add the corresponding Data Source to the process. You can always add more Data Sources to the process by re-deploying it.
- For LCM, add the Data Sources that you want to reuse parameters from.
Schedule the deployed processes. When adding the parameters to a schedule, provide a reference to the corresponding parameter in the Data Source instead of entering an explicit value.
In the data preparation and distribution pipeline, if you want all the bricks to reuse the same parameters, update the configuration file to reference the parameters from the Data Sources instead of adding the parameters to the bricks' schedules.
Create Data Sources
For the information about how to create a Data Source, see Create a Data Source.
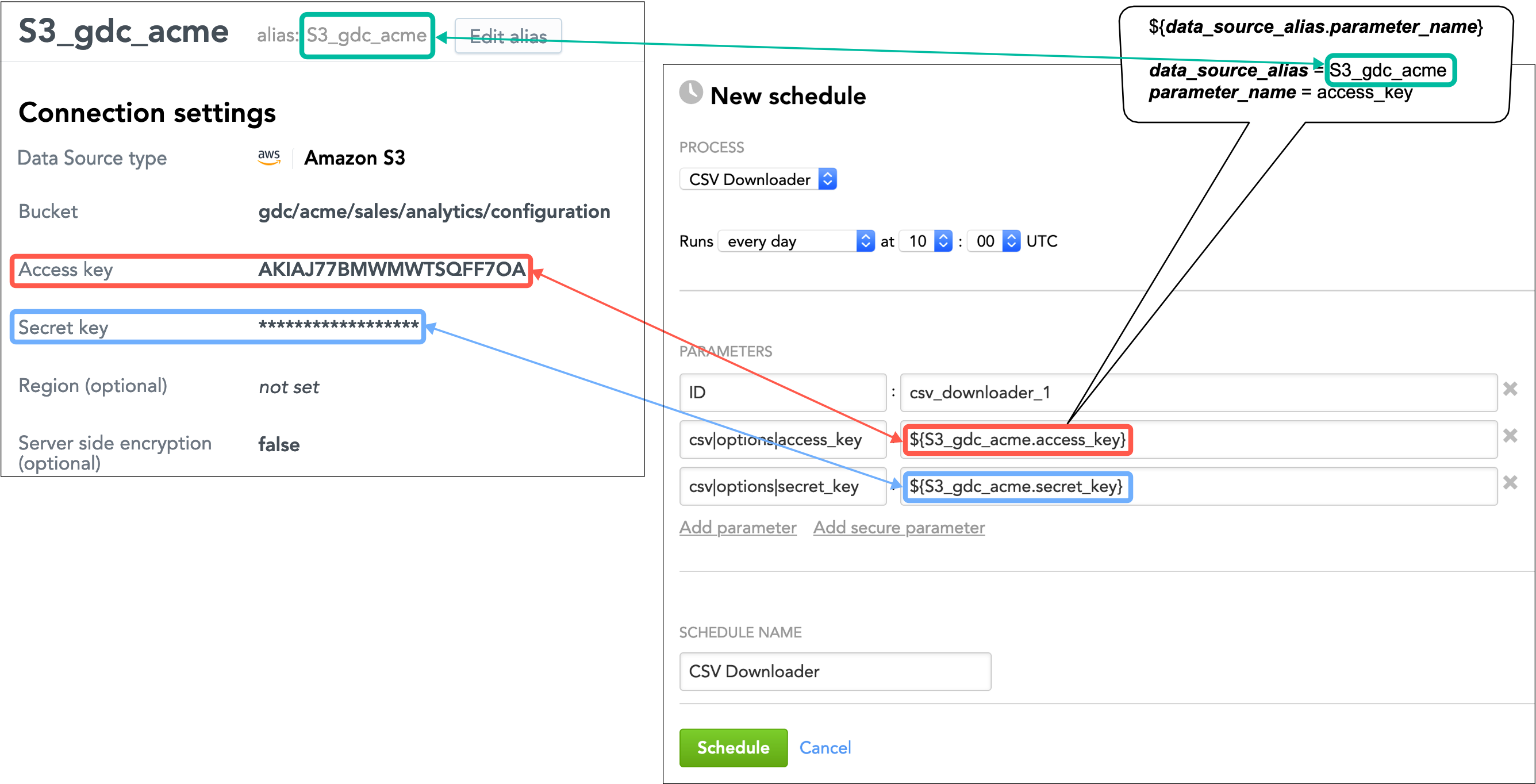
When creating a Data Source, the alias for this Data Source is generated based on the Data Source name that you entered. The alias is used in references to the parameters in this Data Source.
Get References to Data Source Parameters
Get the references to the Data Source parameters that you want to reuse in the processes.
The reference to a parameter is built as ${data_source_alias.parameter_name}. For example, the reference to the bucket parameter in the Data Source with the alias S3_gdc_acme will be generated as ${S3_gdc_acme.bucket}.
Steps:
- Open the Data Source whose parameter references you want to get.
- Hover over a Data Source parameter. The interactive tooltip appears on the right.
- Click Copy reference to copy the reference to this parameter to the clipboard.

Deploy a Process
Deploy a data loading process to the GoodData platform and configure it to use the parameters from the appropriate Data Sources.
During deploying a process, you can use the Data Sources that you created and also the Data Sources that someone shared with you (see Share a Data Source with Other Users).
Steps:
- Click your name in the top right corner, and select Data Integration Console. Alternatively, go to
https://{your.domain.com}/admin/disc/. - On the top navigation bar, select Workspace and click the name of the workspace where you want to deploy a process.
- Click Deploy Process. The deployment dialog opens.
- From the Component dropdown, select what you want to deploy the process for.
For direct data distribution:
- Select Automated Data Distribution.
- From the Data Source dropdown, select the Data Source that you want to use within the ADD v2 process.
For the data preparation and distribution pipeline:
Select the pipeline brick.
Click Switch to using Data Sources.
The dialog is switched to the Data Source layout.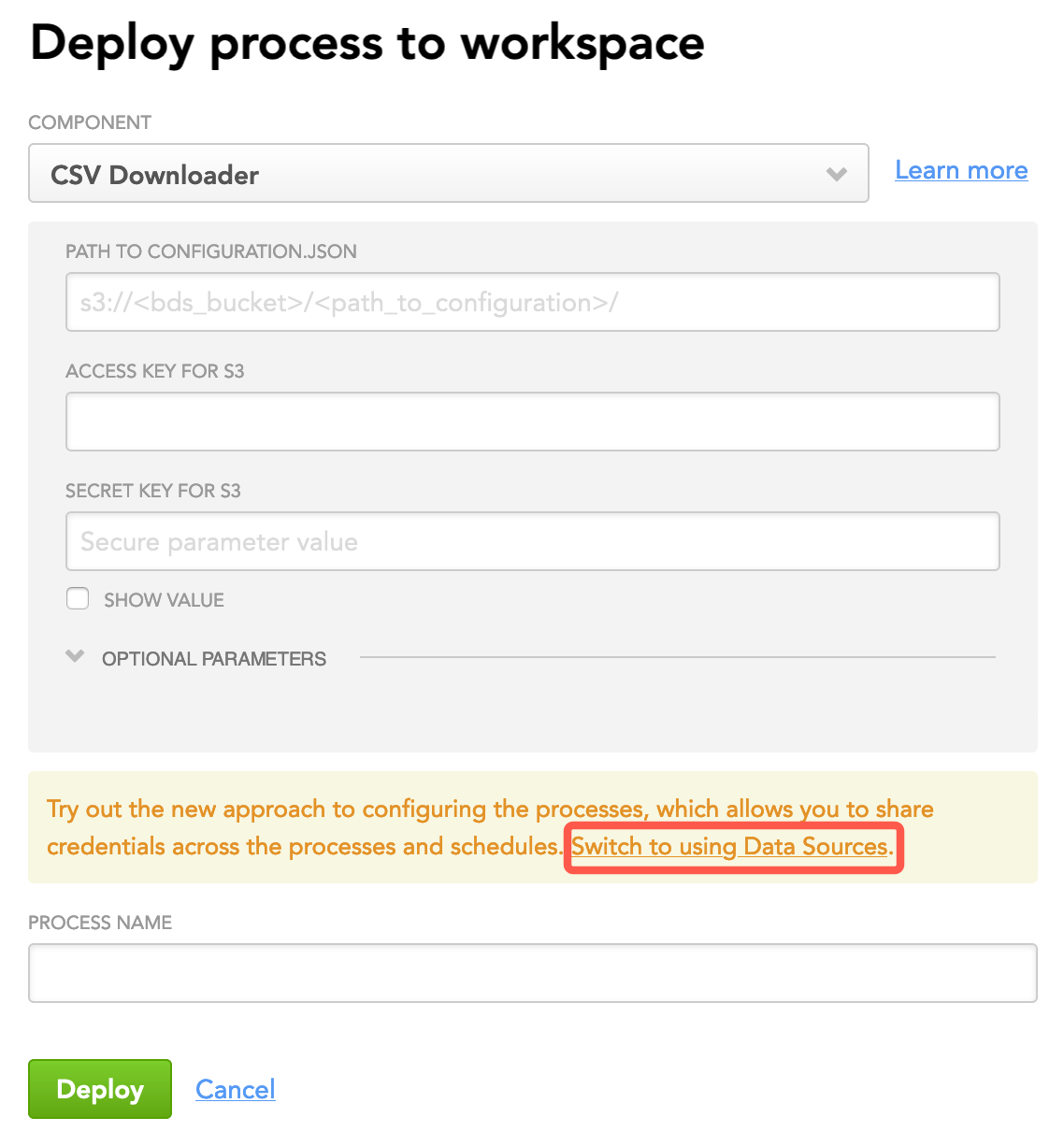
Select the Data Source for the S3 location to specify the path to the configuration file.
The path to the configuration file is generated automatically based on how you defined it in the Data Source. Add a sub-path, if needed.
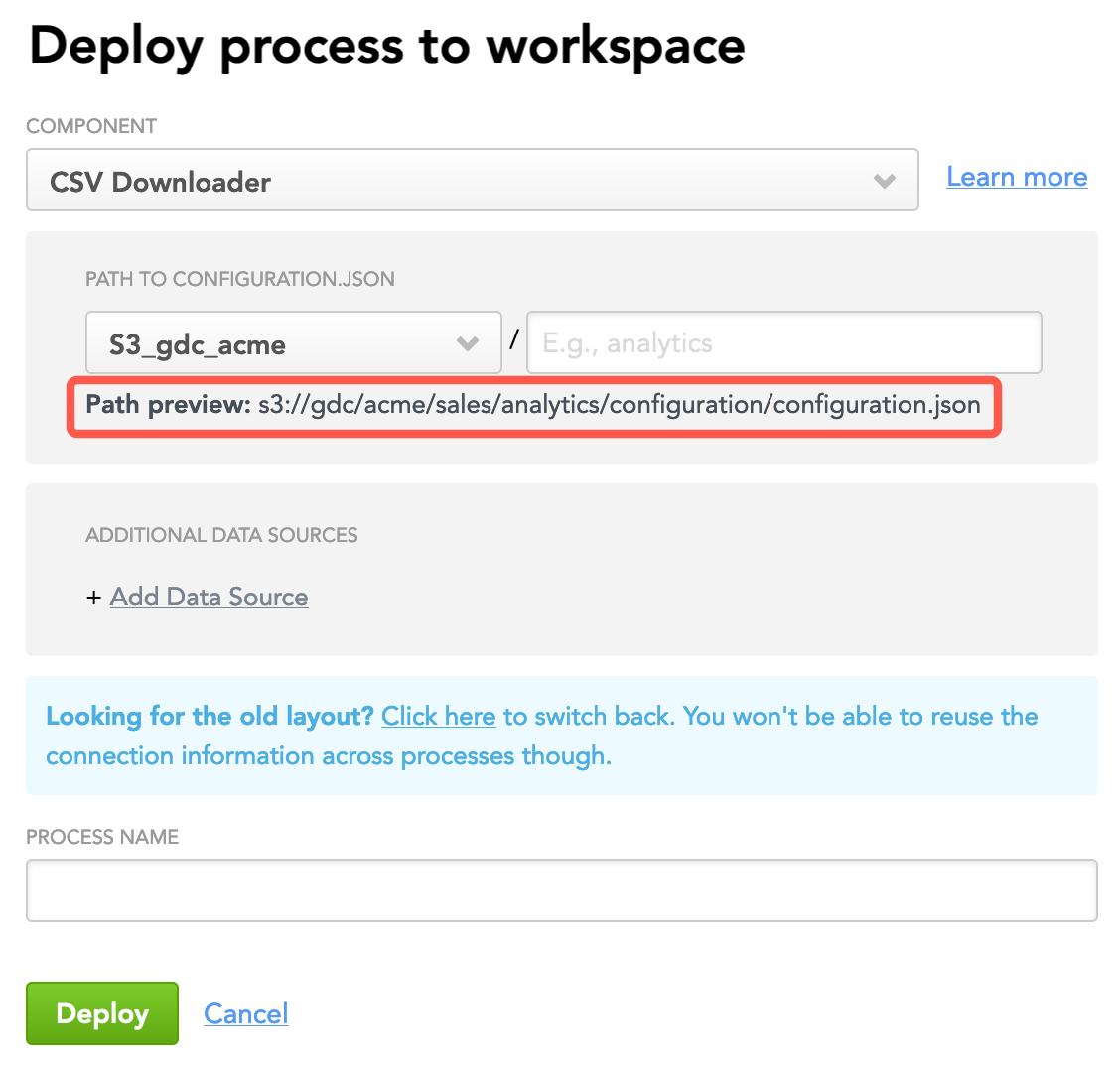
If you want the deployed process to be able to reuse the parameters from other Data Sources, click Add Data Source and select that Data Source. Add as many Data Sources as you need. For example, if you are deploying a process for CSV Downloader and want it to be able to reuse the ADS parameters, add the corresponding Data Source.
If you do not add Data Source now, you will be able to add them any time later by re-deploying this process.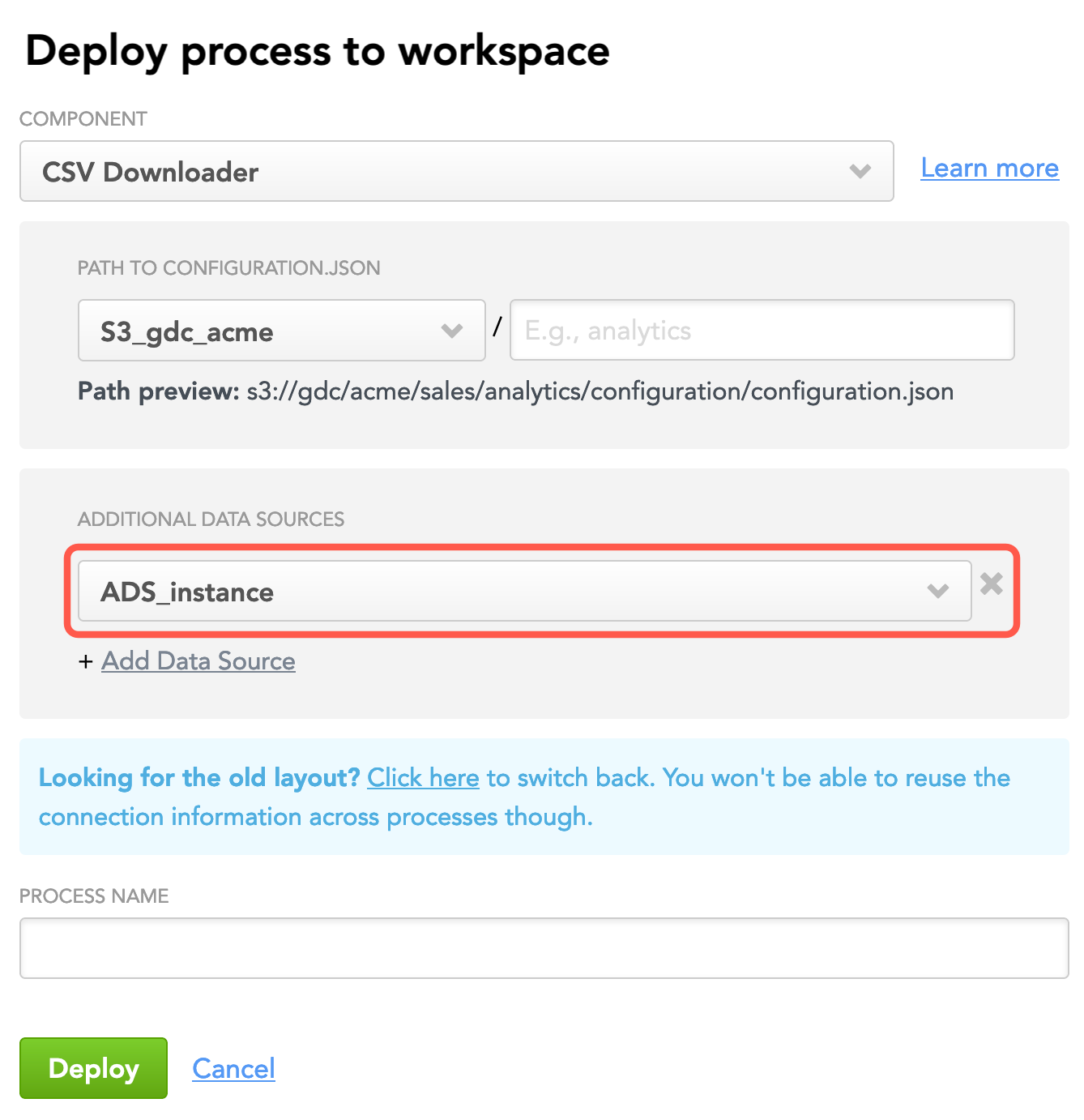
For LCM:
Select the LCM brick.
Click Switch to using Data Sources.
The dialog is switched to the Data Source layout.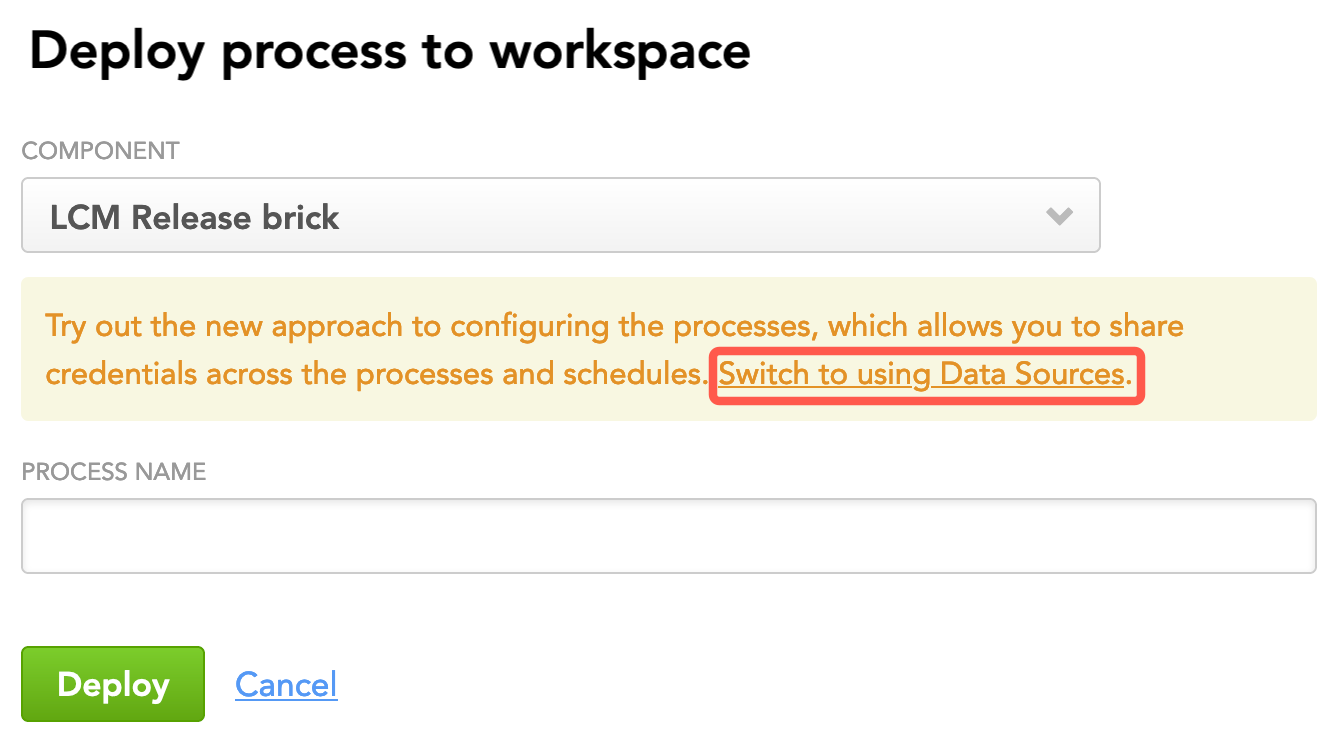
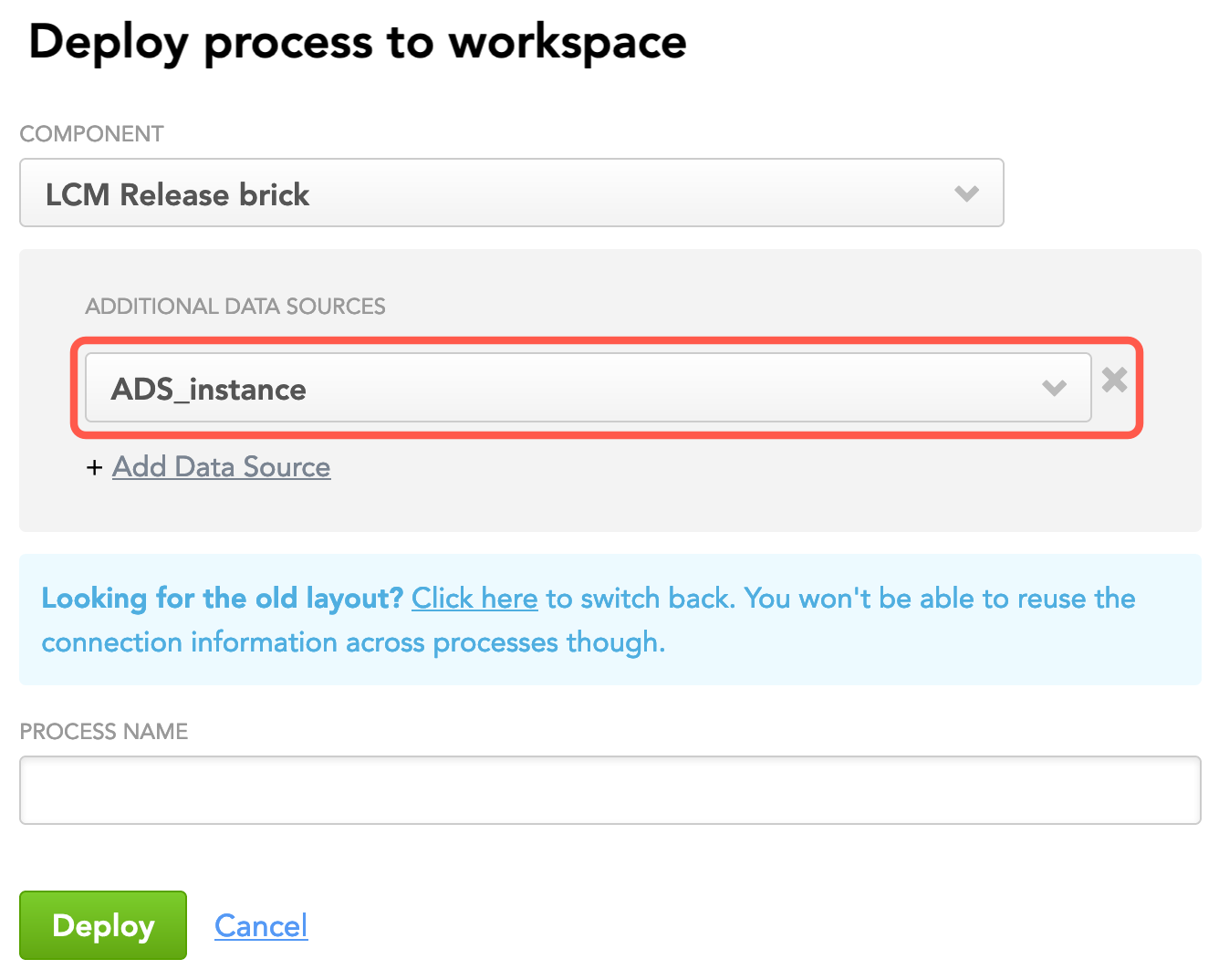
Click Add Data Source and select that Data Source whose parameters you want the deployed process to be able to reuse. Add as many Data Sources as you need.
If you do not add Data Source now, you will be able to add them any time later by re-deploying this process.
Schedule the Deployed Process
Create a schedule to automatically execute the data loading process at a specified time.
Steps:
For the process that you have just deployed, click Create new schedule. The schedule dialog opens.
Select the frequency of process execution.
Add additional parameters to your schedule: click Add parameter and fill in the parameter name and value. Instead of entering an explicit value, use the reference to the parameter from the Data Sources.
You can add the references as regular (not secure) parameters. All the parameters that have been added to a Data Source as secure parameters will be treated as secure parameters regardless of whether they are added to the schedule as regular parameters.
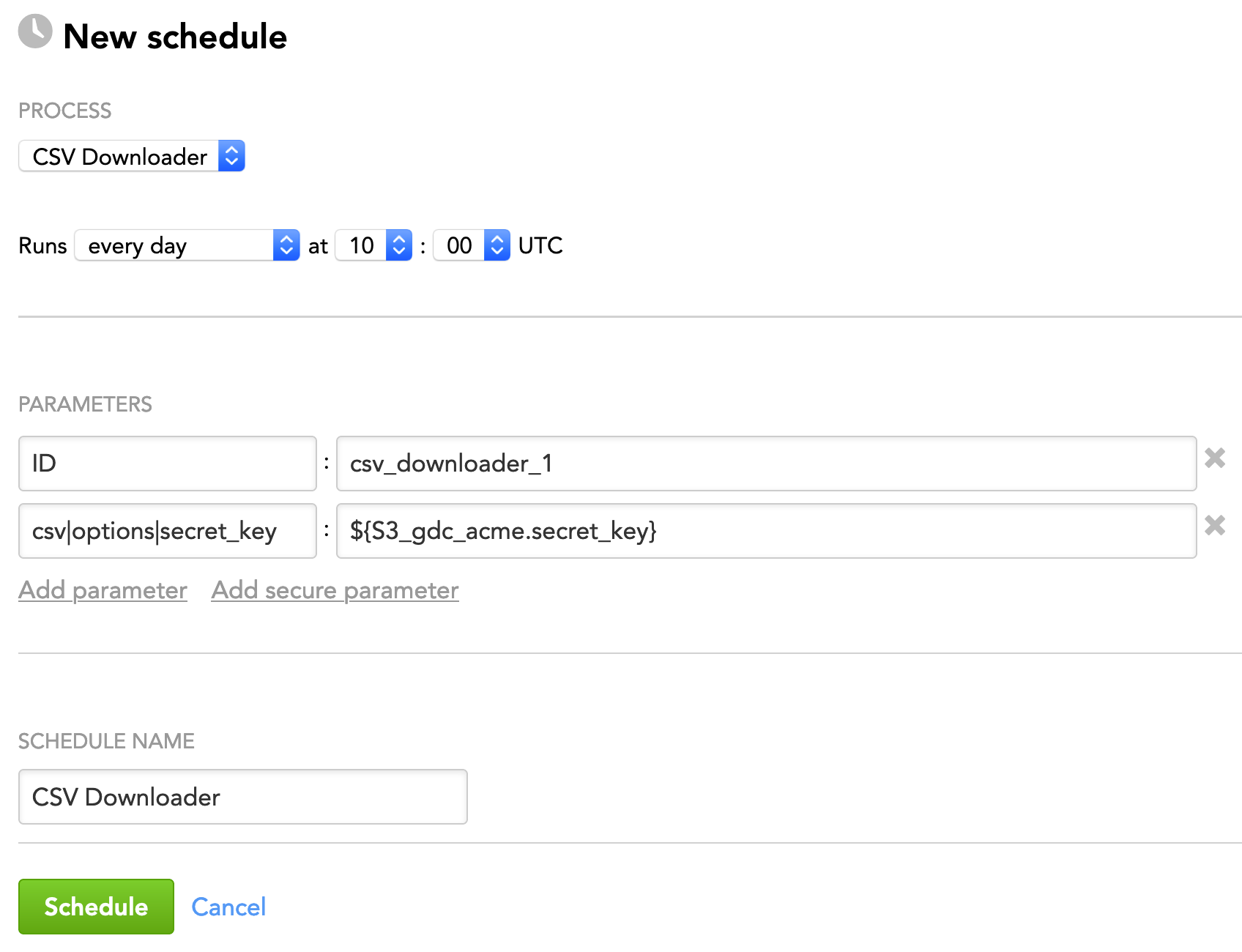
(Optional) Specify a new schedule name.
Click Schedule. The schedule is saved and opens for your preview. The GoodData platform will execute the process as scheduled.
In the data preparation and distribution pipeline, if the same parameter is found in the configuration file and in the schedule, the brick will use the schedule one.
Update the Configuration File with the Parameter References
If you want all the bricks in your data preparation and distribution pipeline to reuse the same parameters, update the configuration file to reference the parameters from the Data Sources instead of adding the parameters to the bricks' schedules. This way, the bricks will pick up the parameters directly from the configuration file.
If the same parameter is found in the configuration file and in the schedule, the brick will use the schedule one.
The reference to a parameter is built as ${data_source_alias.parameter_name}.
For example, if your configuration file looks like this:
configuration.json
{
"entities": {
"Orders": {
"global": {
"custom": {
"hub": [
"id"
],
"export_type": "inc"
}
}
}
},
"downloaders": {
"csv_downloader01": {
"type": "csv",
"entities": [
"Orders"
]
}
},
"csv": {
"type": "s3",
"options": {
"bucket": "gdc",
"access_key": "AKIAJ77BMWMWTSQFF7OA",
"data_structure_info": "acme/sales/analytics/configuration/feedfile.txt",
"data_location": "acme/sales/analytics/input_data",
"delete_data_after_processing": true,
"generate_manifests": true,
"files_structure": {
"skip_rows": "1",
"column_separator": ","
}
}
},
"integrators": {
"ads_integrator": {
"type": "ads_storage",
"batches": [
"csv_downloader01"
]
}
},
"ads_storage": {
"instance_id": "wfc047e12030c3fe48d983d2081a9200",
"username": "john.doe@acme.com",
"options": {}
}
}
…and the S3 Data Source has the alias S3_gdc_acme, replace the explicit values of the bucket and access_key parameters in the csv section with the references to those parameters as follows:
...
"csv": {
"type": "s3",
"options": {
"bucket": "${S3_gdc_acme.bucket}",
"access_key": "${S3_gdc_acme.access_key}",
...
}
}
...
For the generic Data Source that you created for the ADS instance with the alias ADS_instance, replace the explicit values of the instance_id and user_name parameters in the ads_storage section with the references to those parameters as follows:
...
"ads_storage": {
"instance_id": "${ADS_instance.ads_instance_id}",
"username": "${ADS_instance.ads_instance_user}",
...
}
...