Update Data in a Dataset from a CSV File
For workspace administrators only
In a typical workflow, when your logical data model (LDM) is stable, you would automate data loading. To do so, set up data load processes (see Deploy a Process for Automated Data Distribution v2 or Deploy a Data Loading Process for a Data Pipeline Brick) and schedule them to load data regularly (see Scheduling a Process).
In some cases, however, you can benefit from updating data in a specific dataset from a CSV file. For example, you are building the LDM and you need to verify the LDM structure by creating insights.
Check the Field Mapping in the Dataset
Each field (fact or attribute) in the dataset must be unambiguously mapped to a column in the CSV file. During data load, the data from a column in the CSV file will be loaded to the corresponding fact or attribute in the dataset. For more information about the mapping, see Mapping between a Logical Data Model and the Data Source.
For example, here is how the Product Orders dataset is mapped to the product_orders.csv file.
order_id,order_status,product_id,price,quantity
10668-9VYN74-2,Cancelled,210,100.33,1.00
10697-7GBN87-1,Delivered,310,39.35,1.00
10907-0TPH53-3,Delivered,220,50.40,1.00
10778-7INQ32-1,Delivered,230,78.40,1.00
10240-3SBQ40-3,Delivered,160,21.49,1.00
10356-7ZBU60-1,Cancelled,140,21.49,1.00
10700-0ACT49-1,Returned,150,21.82,1.00
10175-0YRN35-3,Delivered,150,19.15,3.00
10152-6HOB25-1,Cancelled,140,29.67,1.00
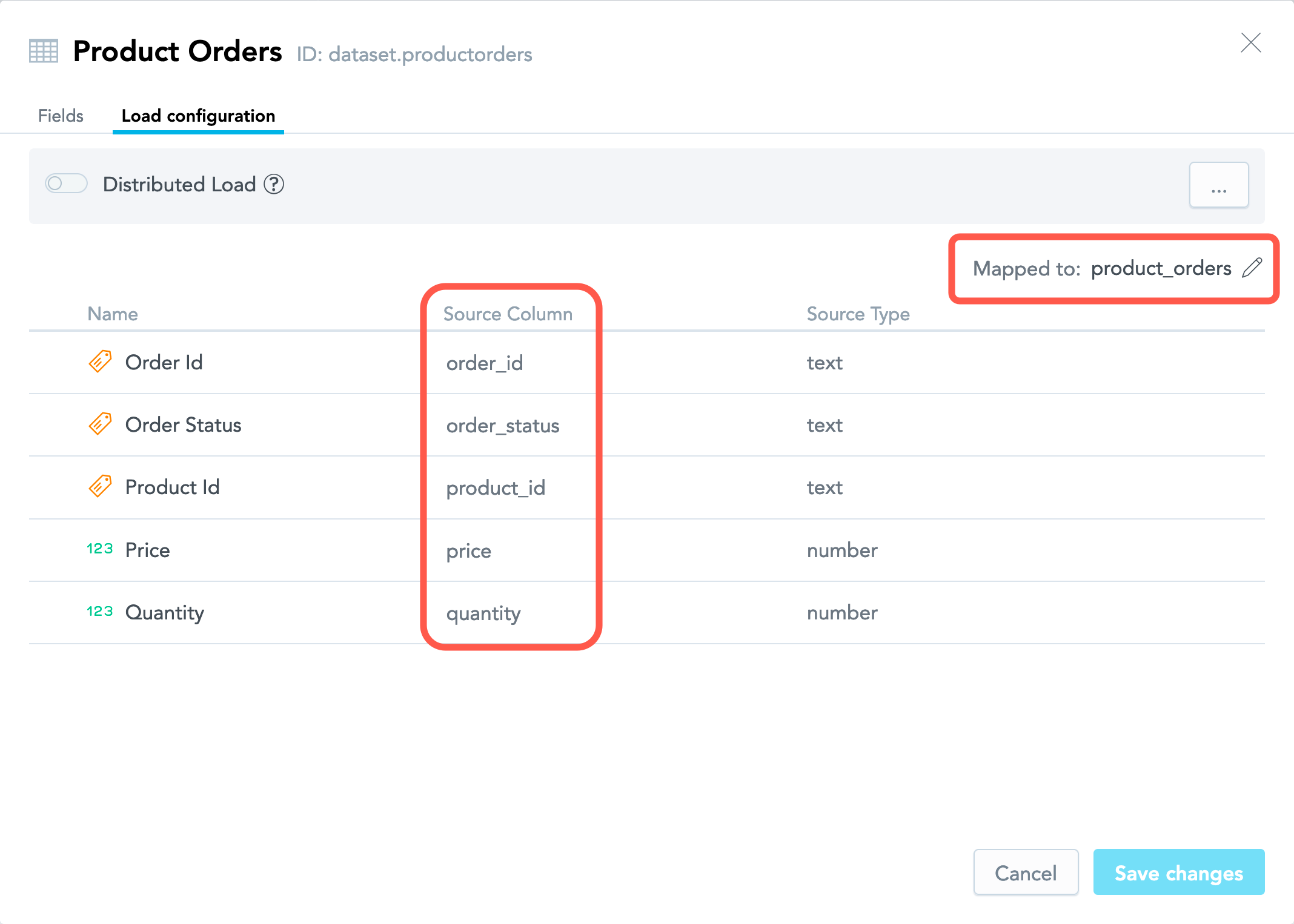
- If the dataset was created from a CSV file, the dataset fields are mapped to the columns in that CSV file.
- If the dataset was created manually, the mapping is automatically generated and set internally according to the naming conventions (see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses and Naming Convention for Source Files in Automated Data Distribution v2 for Object Storage Services).
Steps:
On the top navigation bar, select Data. The LDM Modeler opens in view mode.
Click Edit. The LDM Modeler is switched to edit mode.
Locate the dataset where you want to update data, click More… , then click View details. The dataset details dialog opens.
Switch to the Load configuration tab and check Source Column.
If the dataset was created from a CSV file, all the dataset fields are mapped to the columns in the CSV file.
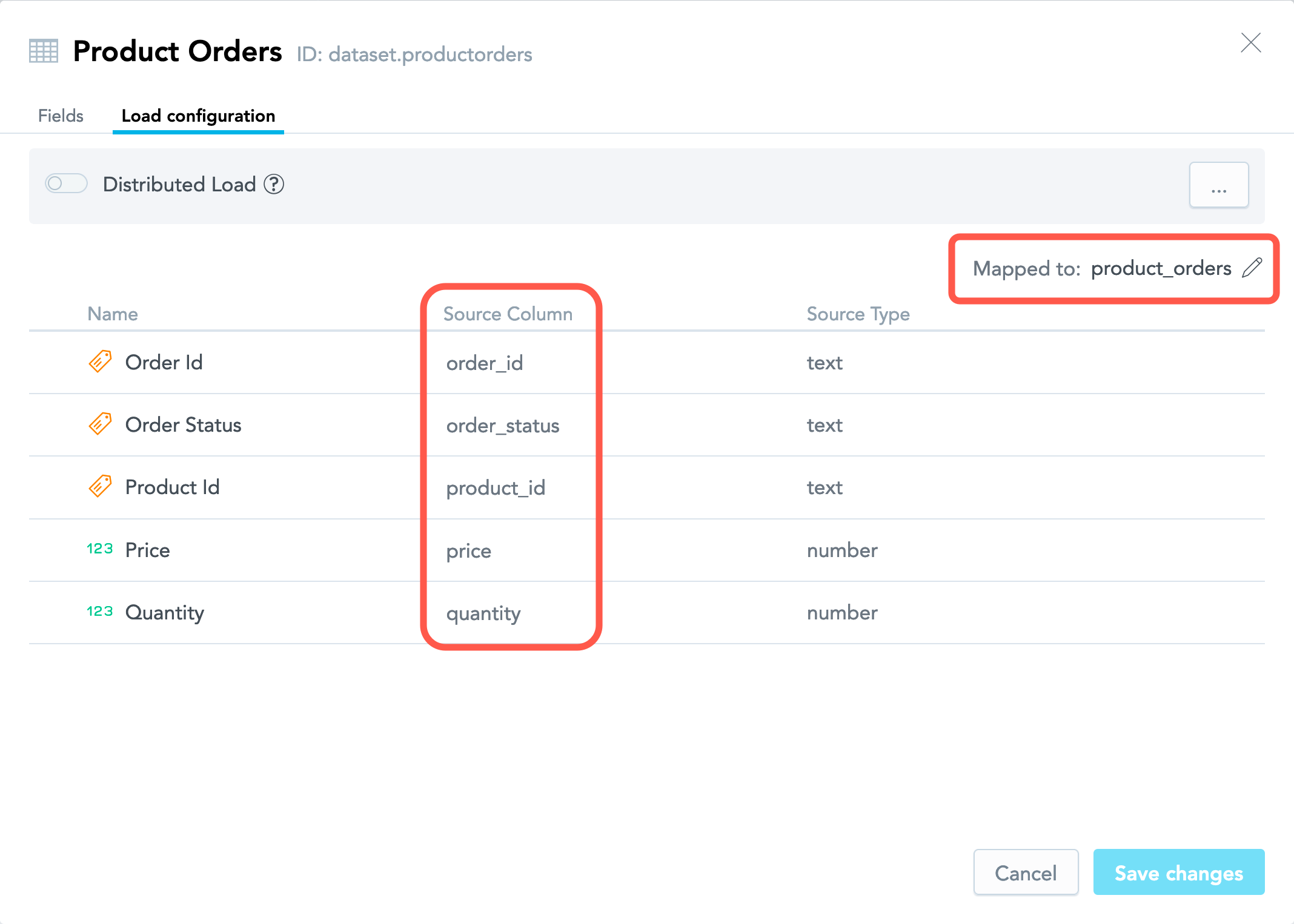
If the dataset was created manually, the mapping is automatically generated and set internally according to the naming conventions (see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses and Naming Convention for Source Files in Automated Data Distribution v2 for Object Storage Services). The mapping will be propagated to the dataset details once you download a CSV template for this dataset, which will be addressed in the following section of this article.
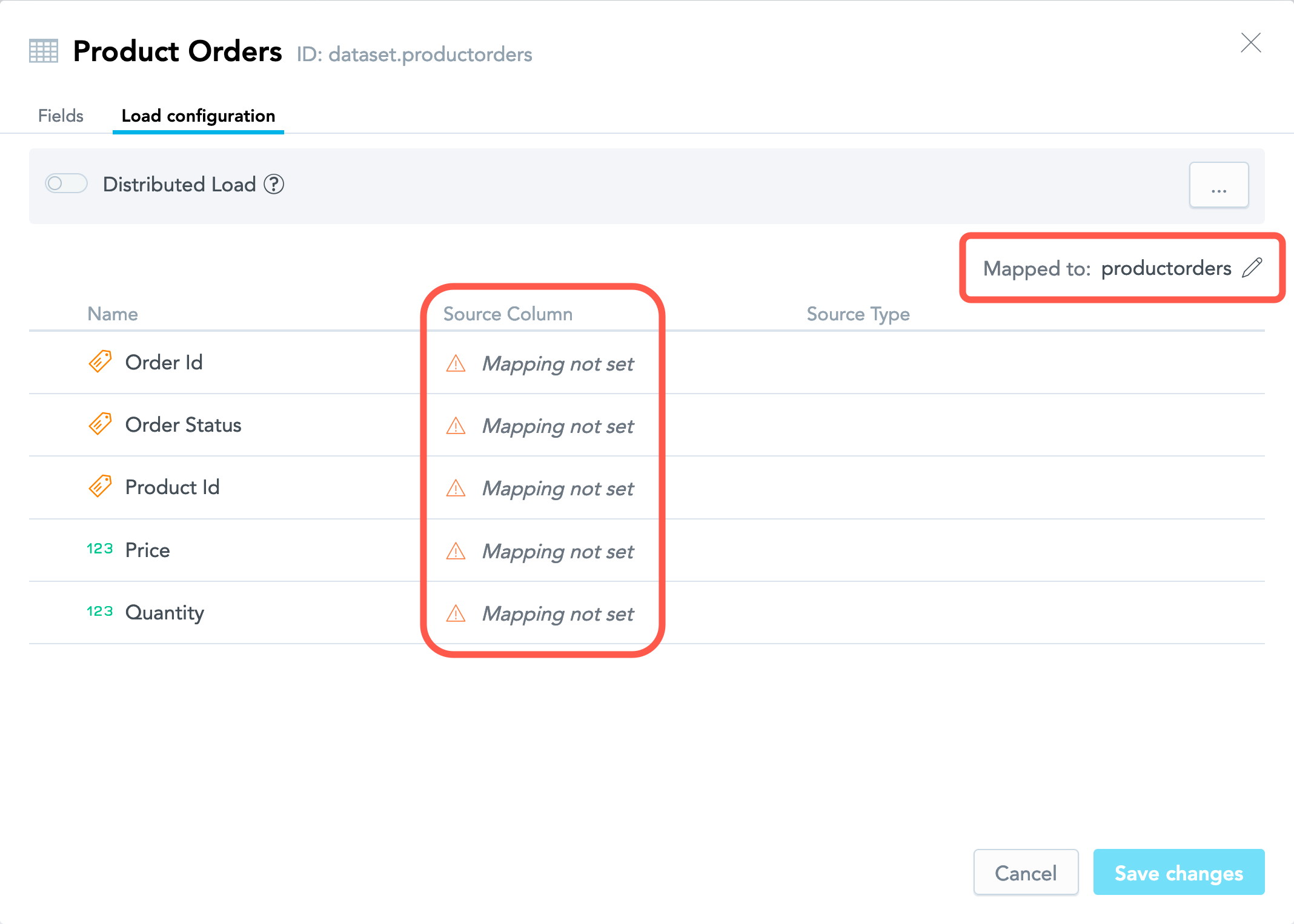
Close the dataset details dialog. You are now going to download the CSV template.
Download the CSV Template
The CSV template is a CSV file with a single header row representing the names of the source columns that are expected in a CSV file from which you will be loading data to this dataset. The CSV template also defines the delimiter (a comma, by default).
If the dataset was created from a CSV file, the CSV template contains the column names according to those names in the CSV file. Here is an example of what the CSV template may look like:
"order_id","order_status","product_id","price","quantity"If the dataset was created manually, the CSV template generates the column names according to the naming conventions (see Naming Convention for Output Stage Objects in Automated Data Distribution v2 for Data Warehouses and Naming Convention for Source Files in Automated Data Distribution v2 for Object Storage Services) and automatically maps them to the dataset fields. Here is an example of what the CSV template may look like:
"a__orderid","a__orderstatus","a__productid","f__price","f__quantity"
Steps:
- Click Load on the left.
- Under Datasets Loads, locate the dataset where you want to update the data, click the menu button for this dataset, and click Download as a CSV Template. A CSV template file is generated.
- Follow the instructions in your browser to save the generated file.
Generate a CSV File with the New Data
Use the CSV template to generate a CSV file with the correct column names and fill it with the data to upload to the dataset.
The data from the CSV file will be uploaded to the dataset in full load mode (the existing data will be overwritten), therefore make sure that the CSV file contains all the data that you want to be in the dataset (not only an incremental update).
The order of the columns in the CSV file is not important.
The CSV file can have more columns than the fields in the dataset. Those extra columns in the CSV file would not have any fields in the dataset mapped and will be ignored at data load.
Load the Data from the CSV File to the Dataset
Once you have the CSV file ready, load the data from this file to the dataset.
Steps:
- Click Load on the left.
- Under Datasets Loads, locate the dataset where you want to update the data, and click Update from file. You are prompted to browse for the CSV file.
- Select the CSV file, and click Import. The loading process starts. When the loading completes, you see a message that the data has been uploaded. Close this message.
You can immediately start analyzing the data. To do so, click Analyze on the top navigation bar. You are redirected to Analytical Designer, where you can create insights from your data. For more information, see Create Insights.