Set Up Automated Data Distribution v2 for Data Warehouses
Automated Data Distribution (ADD) v2 for data warehouses is designed to load data to segments (groups) of workspaces. ADD v2 fetches data from a data warehouse for hundreds of workspaces in one query, which is more efficient than loading data for each workspace separately.
The process of setting up ADD v2 can have a different number of steps to complete.
- If you have a single workspace to distribute data to, go to Integrate the Data to Your Workspaces.
- If you have multiple workspaces and have them organized in segments (as in LCM; see Managing Workspaces via Life Cycle Management), go to Integrate the Data to Your Workspaces.
- If you have multiple workspaces and do not have them organized in segments, go to Organize the Workspaces.
Organize the Workspaces
Read this section if you have multiple workspaces and do not have them organized in segments. Otherwise, go to Integrate the Data to Your Workspaces.
When you have multiple workspaces to distribute the data to, you need to organize those workspaces into a specific structure to instruct ADD v2 what data should be loaded to what workspaces. This structure is based on segments, where a segment combines workspaces with the same logical data model (LDM). This structure is similar to the one that you have when using LCM and uses the same terminology. To learn the LCM terminology, review Managing Workspaces via Life Cycle Management.
If LCM is not implemented on your site, you do not have to set it up and use it as a feature. You only need to create a segment-based structure of your workspaces similar to LCM.
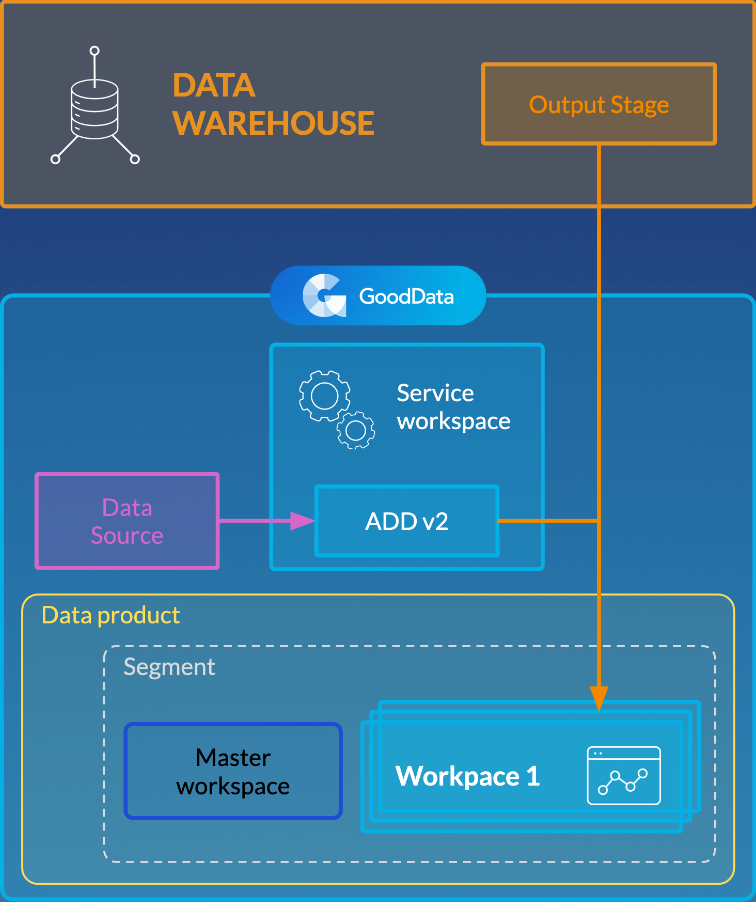
- Workspaces with the same LDM are organized in segments. Each segment has a master workspace, and the other workspaces in this segment are called clients, or client workspaces.
- Segments belong to data products. A data product can contain multiple segments.
- A service workspace is a workspace where ADD v2 data load processes are deployed and run. The service workspace does not belong to any segment and does not have to contain any data or LDM. It is usually a dummy workspace that is used only for deploying ADD v2 processes in it.
To organize the workspaces, you are going to use the APIs. Execute those APIs as a domain administrator.
Steps:
Assign the client workspaces to the appropriate segment. For each client workspace, set the client ID. For more information about the client ID, see Automated Data Distribution v2 for Data Warehouses.
If you have a large number of client workspaces, you can use the API for assigning client workspaces to segments in bulk.
Add the Client ID Column to the Output Stage Tables/Views
Make sure that the Output Stage table/views that you want to distribute separately per workspace has the x__client_id column. This column should contain the values corresponding to the client ID values of your client workspaces. For more information about the client ID, see Automated Data Distribution v2 for Data Warehouses.
Integrate the Data to Your Workspaces
Each data warehouse has its own specific details related to integration with the GoodData platform. Review those details for the data warehouse that you use:
- GoodData-Azure SQL Database Integration Details
- GoodData-Azure Synapse Analytics Integration Details
- GoodData-BigQuery Integration Details
- GoodData-Microsoft SQL Server Integration Details
- GoodData-MongoDB BI Connector Integration Details
- GoodData-MySQL Integration Details
- GoodData-PostgreSQL Integration Details
- GoodData-Redshift Integration Details
- GoodData-Snowflake Integration Details
Steps:
Create a Data Source. The Data Source describes the connection string to your data warehouse.
For information about how to create a Data Source for your data warehouse, see Create a Data Source.
Create the Output Stage in your Data Warehouse (see Create the Output Stage based on Your Logical Data Model). The Output Stage corresponds with the LDM of your workspace (in case of multiple workspaces organized in segments, the LDM of a segment’s master workspace).
Deploy an ADD v2 process (see Deploy a Data Loading Process for Automated Data Distribution v2).
Create a schedule for the deployed process to automatically execute the data loading process at a specified time (see Schedule a Data Load).
Best Practices
When setting up direct data distribution from the data warehouses, we recommend that you apply the following best practices for better data load performance:
- Use tables/views to store data for all customers together with the client IDs. ADD v2 can load such data to the customers’ workspaces much faster than when the data is stored per customer in dedicated tables/views. For more information about client IDs, see Automated Data Distribution v2 for Data Warehouses.
- Use incremental loads instead of full loads. For more information, see Load Modes in Automated Data Distribution v2 for Data Warehouses.
- If you have a large number of client workspaces, adjust the settings of the loading process to prevent timeouts during data load.
- Set up the number of workspaces that should be processed in one query. This processing include downloading data from your data warehouse, filtering the data based on the client IDs, and distributing it to the workspaces accordingly.
- To set this number for a domain, use the platform settings. For more information about the platform settings and how to set up a platform setting, see Configure Various Features via Platform Settings.
- For incremental data loads, use the
dataload.incrementalProjectsChunkSizeplatform setting. The default is 100. The maximum allowed number is 500. Set it to your preferred number. - For full loads, use the
dataload.fullProjectsChunkSizeplatform setting. The default is 4. The maximum allowed number is 500. Set it to your preferred number.
- For incremental data loads, use the
- To set this number for a particular data load task, add the
GDC_DOWNLOAD_PROJECTS_CHUNK_SIZEparameter to the task’s schedule and set it to your preferred number (see Configure Schedule Parameters or the API for running a schedule). If this parameter is specified, it will override the number of workspaces set by the platform settings at the domain level.
- To set this number for a domain, use the platform settings. For more information about the platform settings and how to set up a platform setting, see Configure Various Features via Platform Settings.
- Set up the number of threads running in parallel in a data load task. The default is 1. Other possible values are 2, 3, and 4. To set this number for a particular data load task, add the
queryParallelismparameter to the task’s schedule and set it to your preferred number (see Configure Schedule Parameters or the API for running a schedule).
- Set up the number of workspaces that should be processed in one query. This processing include downloading data from your data warehouse, filtering the data based on the client IDs, and distributing it to the workspaces accordingly.
Example
Imagine that you have 100 client workspaces and your data is loaded in incremental mode. With the default settings (dataload.incrementalProjectsChunkSize set to 100 and queryParallelism set to 1), data for all 100 client workspaces will be retrieved in one query, and only one thread will be running in a task.
You can optimize the loading processes as follows:
- Set
dataload.incrementalProjectsChunkSizeto 25. - Set
queryParallelismto 4.
These settings allow for splitting the client workspaces into four queries (25 workspaces per query) and running four threads in parallel in each task.