Schedule Executor
Schedule Executor is a utility that supports the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). Schedule Executor runs schedules in one or more workspaces based on the criteria that you have defined (what workspaces to look into and what schedules to run).
How Schedule Executor Works
When Schedule Executor runs, it searches through the workspaces that you have defined (either all the workspaces that Schedule Executor can access or only the workspaces in a specific environment), collects all the schedules from those workspaces, and looks for the parameter called mode in the collected schedules (see Configure Schedule Parameters). If the parameter exists in a schedule and is set to one of the values of the list_of_modes parameter in Schedule Executor itself, the schedule is run.
For example, you have schedules in your workspaces set up like this:
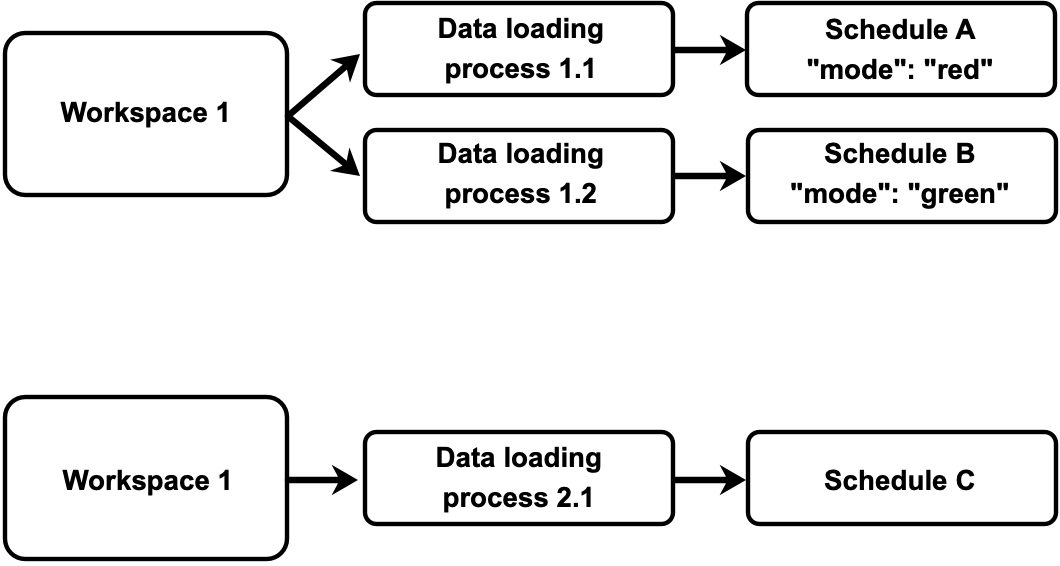
If you execute Schedule Executor with the list_of_modes parameter set to red|blue, the following will happen:
- Schedule Executor will run Schedule A because the
modeparameter of Schedule A is set tored, andredis one of the values of thelist_of_modesparameter in Schedule Executor. - Schedule Executor will not run Schedule B because the value of Schedule B’s
modeparameter is not listed among the values of thelist_of_modesparameter in Schedule Executor. - Schedule C will not be even considered for running because it does not have the
modeparameter at all.
Schedule Executor only starts the schedules. It does not wait for them to finish. Schedule Executor often finishes before the schedules.
Configuration File
Schedule Executor does not require any parameters in the configuration file.
Schedule Parameters
When scheduling Schedule Executor (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
list_of_modes | string | yes | no | n/a | See list_of_modes. |
number_of_schedules_in_batch | integer | no | no | 1000 | The number of schedules to be started in one run |
delay_between_batches | integer | no | no | 1 | The number of seconds between batch executions |
thread_count | integer | no | no | 5 | The number of threads that will be used for running schedules |
set_retry | Boolean | no | no | false | Specifies whether a failed schedule should be restarted.
|
dry_run | Boolean | no | no | false | Specifies whether Schedule Executor should only generate a log with the schedules that will be run instead of actual running of the schedules.
|
control_parameter | string | no | no | mode | The parameter in a schedule that you want to use instead of the default Use this parameter when your schedules do not have the |
work_done_identificator | string | no | no | ignore | Specifies whether Schedule Executor should automatically access all the workspaces that you have defined.
NOTE: The default value, |
| dataload_parameters_query | string | no | no | n/a | The SQL query for getting additional parameters that will be added to the schedules at execution NOTE: If this parameter is specified, the Example: You have a workspace with custom fields (such as attributes or facts) in the logical data model's datasets. To do so, you need to run data loading processes for this workspace in Use this parameter to instruct Schedule Executor to run the data load processes in For a complete process of adding custom fields and using this parameter, see Add Custom Fields to the LDMs in Client Workspaces within the Same Segment. |
execution_params | JSON | no | no | n/a | Additional parameters that will be added to the schedules at execution Format: You must encode this parameter using the NOTE: This parameter is ignored if the |
list_of_modes
The list_of_modes parameter contains the values that Schedule Executor will compare to the value of the mode parameter in schedules.
- If Schedule Executor finds the
modeparameter in a schedule and the parameter’s value is one of the values listed inlist_of_modes, the schedule will be run. - If Schedule Executor finds the
modeparameter in the schedule but the parameter’s value is not one of the values listed inlist_of_modes, the schedule will not be run. - If Schedule Executor does not find the
modeparameter in the schedule, the schedule will not be run.
If you provide multiple values, separate them by a vertical bar (|).
"list_of_modes": "red|green|blue"
In this example, Schedule Executor will run the schedules whose mode parameter is set to red, green, or blue, and will ignore all the other schedules.
Environment-Specific Parameters
By default, Schedule Executor runs the schedules in all the workspaces that the user under whom Schedule Executor runs can access.
You can narrow down the list of the workspaces that Schedule Executor should access and collect schedules from by specifying an environment that the workspaces are related to:
- Life Cycle Management (LCM): Schedule Executor accesses only the workspaces that are client workspaces within a specific segment in the specified data product and the domain. For more information about LCM, see Managing Workspaces via Life Cycle Management.
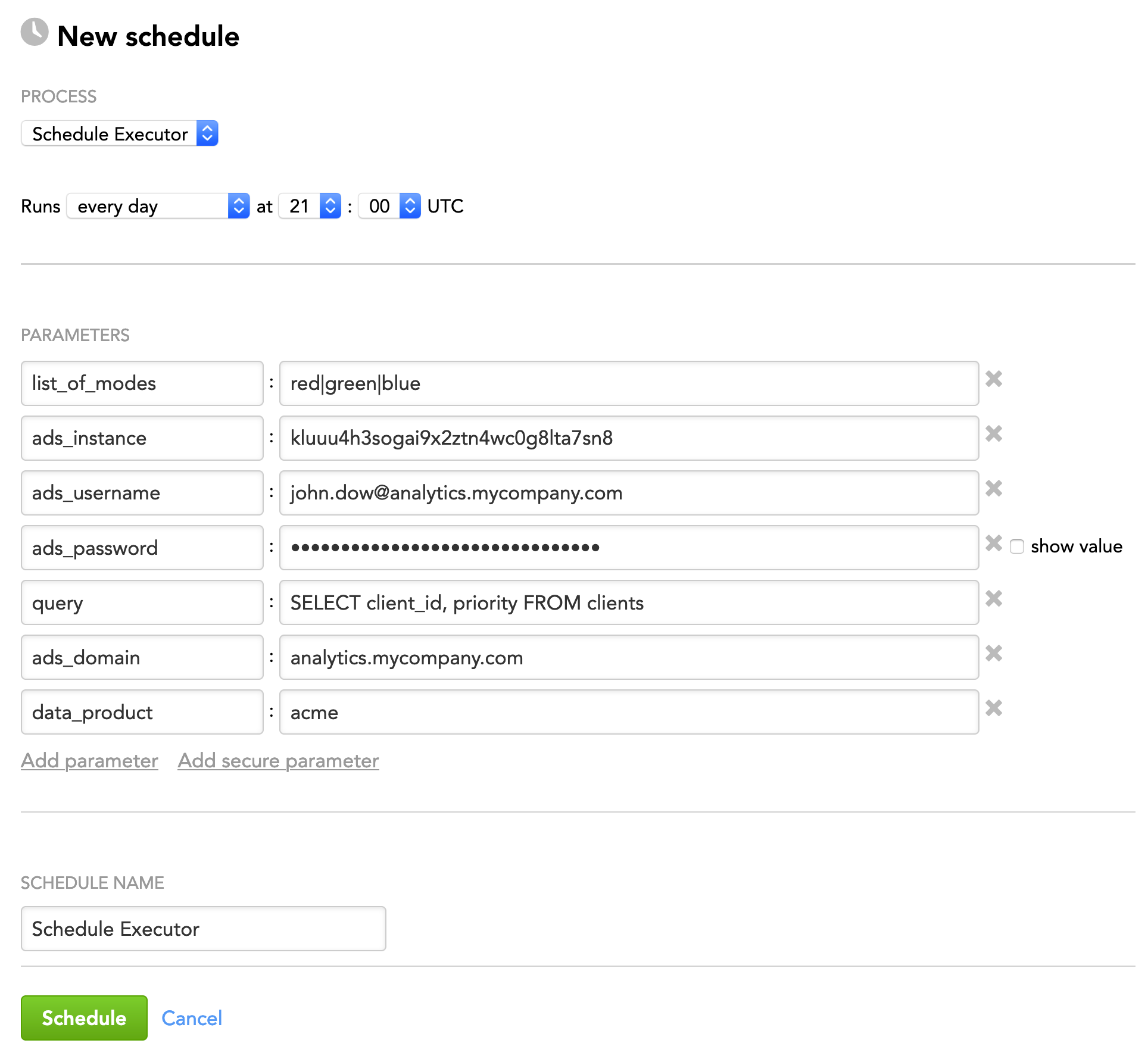
- Data Warehouse (ADS): Schedule Executor accesses only the workspaces that are returned by the SQL query that you constructed and executed against a specific Agile Data Warehousing Service (ADS) instance.
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
For LCM, you must schedule Schedule Executor as a domain admin.
| Environment | Parameter Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|---|
| LCM | domain | string | yes | no | n/a | The name of the domain where the workspaces to access belong to |
segment_list | string | yes | no | n/a | The name of the segments in the specified domain where the workspaces to access belong to If you provide multiple segments, separate them by a vertical bar ( Example: | |
| data_product | string | no | no | default | The data product that contains the segments where the workspaces to access belong to | |
| ADS | ads_instance | string | yes | no | n/a | The ID of the ADS instance to access |
| ads_username | string | yes | no | n/a | The access username to the ADS instance | |
| ads_password | string | yes | yes | n/a | The password for the user that you specified in the | |
| query | string | yes | no | n/a | The SQL query for getting the workspaces that Schedule Executor should access and collect schedules from
Example: | |
| ads_domain | string | see "Description" | no | n/a | The name of the domain where the workspaces to access belong to This parameter is mandatory only when you identify the workspaces by their client IDs (that is, the SQL query in the | |
| data_product | string | see "Description" | no | n/a | The data product within the specified domain where the workspaces to access belong to This parameter is mandatory only when you identify the workspaces by their client IDs (that is, the SQL query in the |
Schedule Examples
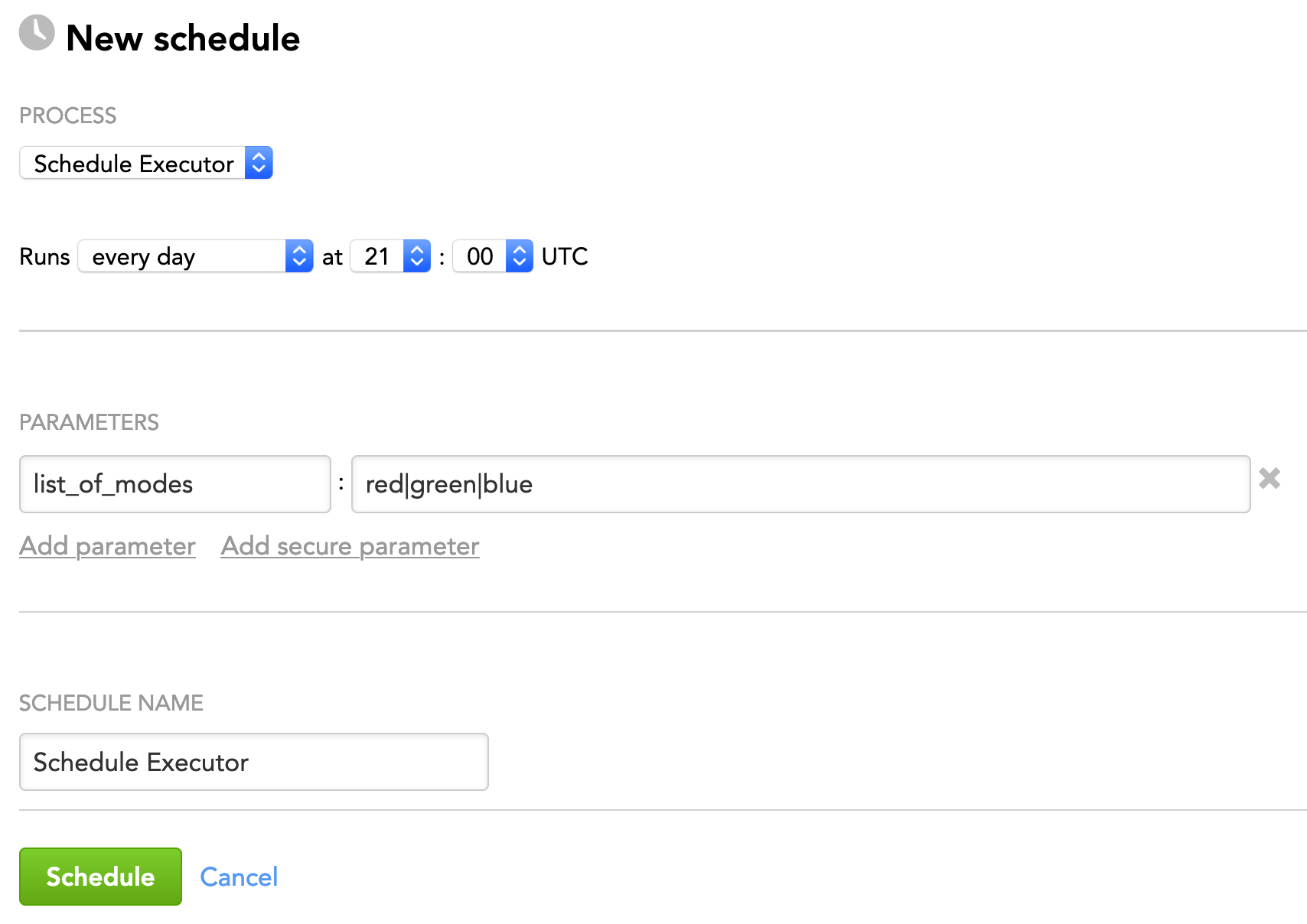
Example 1: Run schedules in all accessible workspaces based on the values of the schedules' mode parameter.
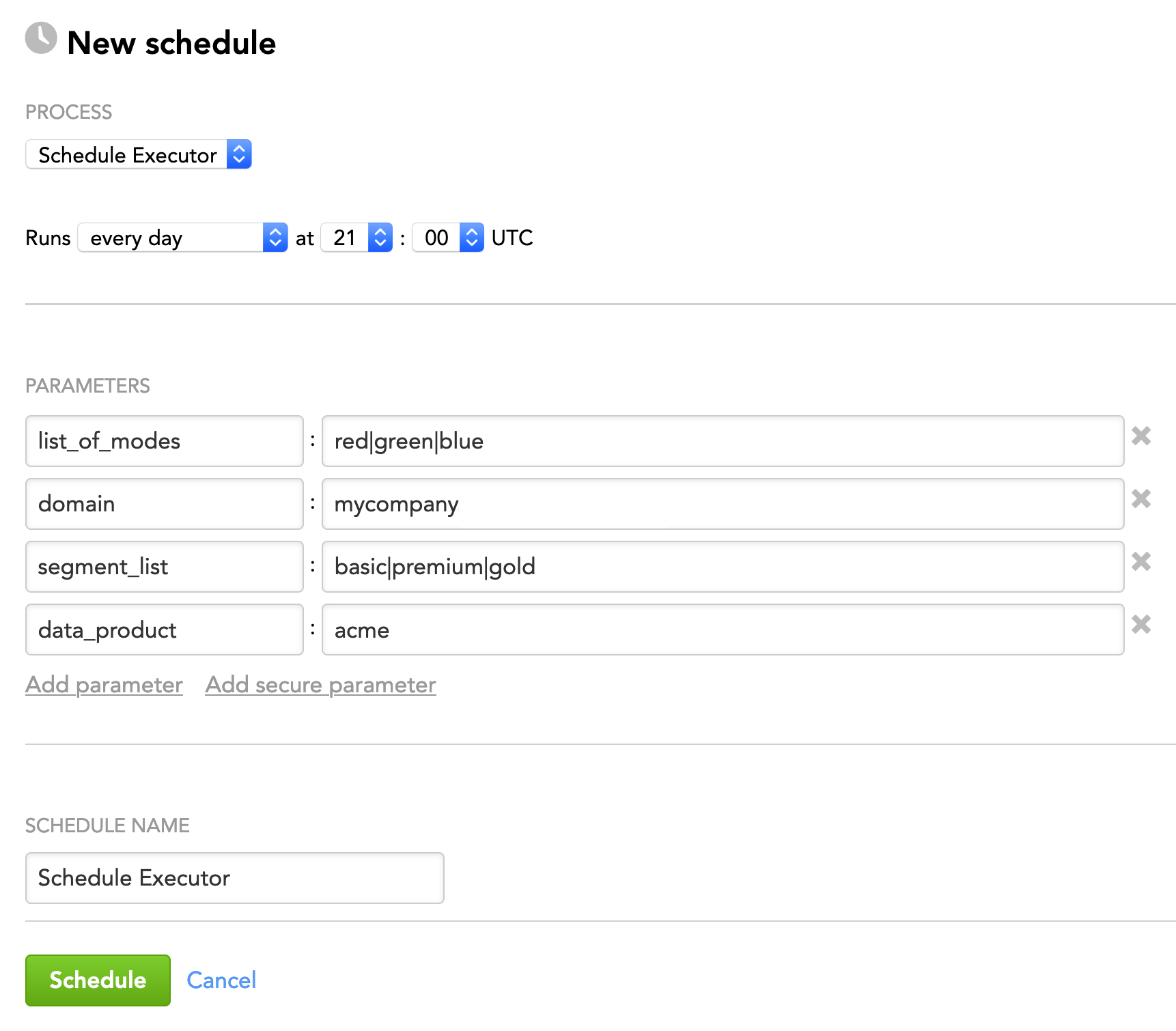
Example 2: Run schedules in all the client workspaces in the specified LCM segments based on the values of the schedules' mode parameter.
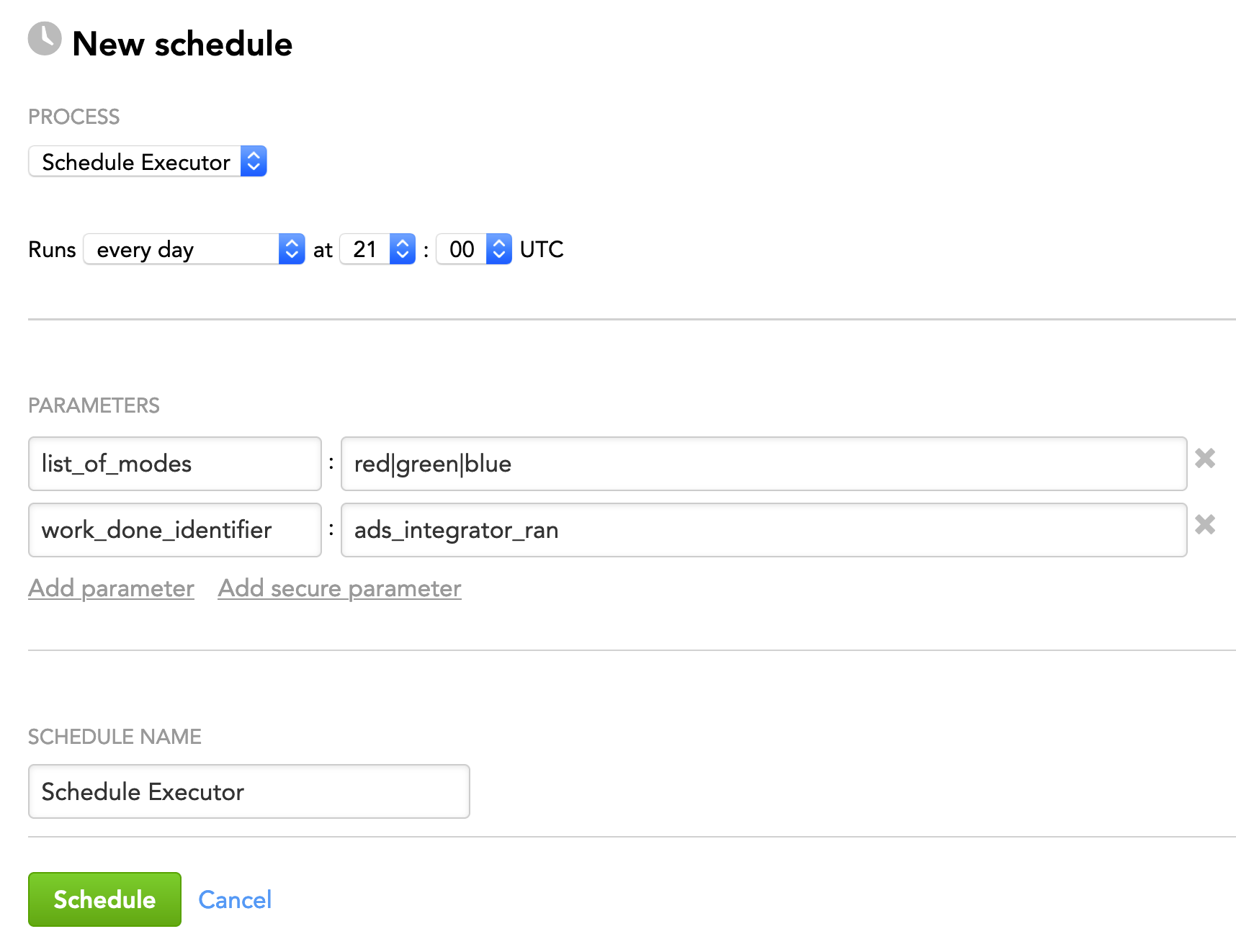
Example 3: Run schedules in all accessible workspaces based on the values of the schedules' mode parameter but only after ADS Integrator has uploaded some data to ADS and set the ads_integrator_ran metadata key to true. For more information, see this section.
Example 4: Run schedules based on the values of the schedules' mode parameter in the workspaces returned by the SQL query that you constructed and executed against the specified ADS instance.
Resource Limitation
The schedules are run in batches. The default number of schedules in a batch is 1000 (see the number_of_schedules_in_batch parameter), which is relatively large. In certain cases, however, the data loading processes that are executed through the schedules use the same resource (for example, a table in the database), therefore you may need to check for potential conflicts and configure how many schedules Schedule Executor will be running in one batch and/or how much time Schedule Executor should wait before it starts another batch.
To do so, use the number_of_schedules_in_batch parameter and the delay_between_batches parameter (see General Parameters). For example, if you have 100 schedules to run and want Schedule Executor to run those schedules in five batches (20 schedules per batch) and to wait five minutes between batches, set the number_of_schedules_in_batch parameter to 20 and the delay_between_batches parameter to 300 (the number of seconds in five minutes).
Advanced Settings
Run Schedule Executor Under a Different User
If you want to execute Schedule Executor under a different user than the default one, provide the following four parameters in the schedule. Otherwise, do not use any of these parameters and skip this section.
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Secure? | Default | Description |
|---|---|---|---|---|
| CLIENT_GDC_HOSTNAME | string | no | secure.gooddata.com | The white-labeled domain name in the format of The parameter name is case-sensitive and must be written in uppercase. |
| CLIENT_GDC_PROTOCOL | string | no | https | The protocol to transfer data over Explicitly set this parameter to The parameter name is case-sensitive and must be written in uppercase. |
GDC_USERNAME | string | no | n/a | The user under whom you want to execute Schedule Executor The parameter name is case-sensitive and must be written in uppercase. |
| GDC_PASSWORD | string | yes | n/a | The password for the user that you specified in the The parameter name is case-sensitive and must be written in uppercase. |
Run Schedule Executor Only After ADS Integrator Has Processed Some Data
If new data is loaded from your data sources frequently (for example, every hour) or without a predictable schedule, you may want to run data loading tasks only after ADS Integrator (see ADS Integrator) has uploaded some data to ADS.
Every time ADS Integrator has processed data and integrated it into ADS, it takes the value of the notification_metadata parameter from the metadata storage of the workspace where it is deployed (typically, it is the service workspace; see Data Preparation and Distribution Pipeline), creates a metadata key with the same name in the metadata storage, and sets this key to true.
You can use this functionality to instruct Schedule Executor to run the schedules only after ADS Integrator has switched the metadata key to true.
Steps:
Set the
notification_metadataparameter to some value that you will later be using as the name of the special key for Schedule Executor. To do so, use the API for creating a key-value pair in the workspace metadata storage. For example, you can set it toads_integrator_ran:"notification_metadata": "ads_integrator_ran"ADS Integrator will be creating and setting the
ads_integrator_ranmetadata key totrueevery time it has processed some data and integrated it into ADS.Use the value from Step 1 as the value of the work_done_identificator parameter in Schedule Executor:
"work_done_identificator": "ads_integrator_ran"Schedule Executor will look for this key in the workspace’s metadata. If this key is set to
true(which means that ADS Integrator has processed data and integrated it into ADS), Schedule Executor will run the schedules.
After Schedule Executor has run the schedules, it will reset the metadata key to false. Next time Schedule Executor will run the schedules again after ADS Integrator sets it back to true.
If you cannot or do not want to use the notification_metadata parameter, you can set up your own special key in the workspace’s metadata storage and use this key name as a value of the work_done_identificator parameter in Schedule Executor. Schedule Executor will run the schedules only when you set your special key to true.
After Schedule Executor has run the schedules, it will reset the key to false. Whenever you want Schedule Executor to run the schedules again, you must set the key back to true.