Object Renaming Utility
Object Renaming Utility is a utility that supports the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). Object Renaming Utility batch-renames and/or hides metadata objects in one or more workspaces based on the criteria that you have defined (what objects to rename/hide and in what workspaces to do so).
How Object Renaming Utility Works
When Object Renaming Utility runs, it renames and/or hides objects in the workspaces according to the criteria that you have defined in queries:
- The object to process
- The workspace that the object belongs to
- The new name for the object
- Whether the object is visible or hidden in the workspace
You can use Object Renaming Utility to process the following objects:
- Facts
- Metrics
- Attributes
- Attribute labels
- Variables
- Reports
- Insights
- Datasets
- Date dimensions (together with its attributes)
- Dashboards
- KPI Dashboards
- For date dimensions, Object Renaming Utility tries to keep the default format of attribute names and may not be able to rename attributes with customized names.
- For renamed facts, attributes, and metrics, KPI Dashboards show their old names.
Allowing Different Customers to Use Different Naming Conventions for the Same Objects
If some of your customers require a specific report, metric or another object be called differently, use Object Renaming Utility to change the name of that particular object.
If you want to rename objects to have their names in a different language, use native support for translation (see Metadata Localization).
Hiding Unwanted Objects from Users
If you need to hide some objects (for example, objects not used in a particular workspace) from the users, especially if you allow the users to create ad hoc reports, use Object Renaming Utility to hide these objects.
The hidden objects are hidden from all users in the workspace including the workspace administrators. This may make it difficult to use them.
If you use embedded Analytical Designer and only want to prevent users from seeing some objects there, consider using the includeObjectsWithTags and excludeObjectsWithTags URL parameters (see Embed Analytical Designer).
Hiding objects using Object Renaming Utility is not a security feature. Hiding an object only affects visibility of the object in various sections of the UI (such as Analytical Designer or LDM Modeler) and the API. It does not handle the users' ability to access the data in any way.
Setting Up Custom Fields in an LDM in a Multi-tenant Environment
If you use Life Cycle Management (see Managing Workspaces via Life Cycle Management), the logical data model (LDM) is aligned across the workspaces within a segment. If you need to add custom fields (facts, attributes, and so on to the LDM so that the LDM in each client workspace gets a different set of fields, do the following:
- Add a fixed number of placeholder fields to the LDM in the segment’s master workspace. For example, add attributes
custom1,custom2, …custom10to one or more datasets in the LDM. - After the LDM was propagated from the master workspace to the client workspaces, use Object Renaming Utility to rename the placeholder fields in the LDM for each client workspace based on what actual data is in a particular workspace.
- Use Object Renaming Utility to hide the remaining unused fields in each client workspace.
In this scenario, if you are using LCM bricks, you should run Object Renaming Utility regularly after the provisioning brick (see Provisioning Brick) to make sure that newly created client workspaces have the custom fields properly set. You may also need to run Object Renaming Utility after the rollout brick (see Rollout Brick) in case it changes the names back to the default ones in the client workspaces.
- Prepare separate placeholders for each type of a custom field (facts, attributes, dates, and so on).
- Object Renaming Utility does not take care of preparing data to be loaded to the custom fields. Make sure that the data is ready in the data source before loading it to the dataset.
- Make sure that you have the data prepared properly to be loaded by Automated Data Distribution (ADD; see Use Automated Data Distribution). All the workspaces still have the same LDM, and all the fields, including the hidden ones and containing empty values, in each dataset must be mapped to the appropriate source columns (see Mapping between a Logical Data Model and the Data Source). While the placeholder fields can have a different meaning for different clients, the overall structure of the LDM remains the same. For the mapping of a field, the field identifier is used, and the identifier does not change when the field itself is renamed.
Configuration File
Object Renaming Utility does not require any parameters in the configuration file.
Schedule Parameters
When scheduling Object Renaming Utility (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| rename_mode | string | yes | no | n/a | The identifier of the workspaces where objects to rename/hide belong to Possible values:
The value of this parameter defines what you provide in the |
| domain_name | string | see "Description" | no | n/a | The name of the domain where the workspaces belong to This parameter is mandatory only when |
| gd_encoded_params | JSON | yes | no | n/a | The parameters coding the queries |
| dry_run | Boolean | no | no | false | Specifies whether Object Renaming Utility should only generate a log with the objects that will be renamed/hidden instead of actual renaming/hiding of the objects.
|
| allow_blank_summary | Boolean | no | no | false | Specifies whether Object Renaming Utility allow the object description (which is provided in the
|
| dont_fail_on_error | Boolean | no | no | false | Specifies whether Object Renaming Utility fails when an error occurs.
Regardless of what this parameter is set to, all errors are recorded to the log where you can review it later. |
| number_of_threads | integer | no | no | 3 | The number of threads that will be used for processing the objects IMPORTANT: The default value is sufficient for an average workspace on a standard ADS instance. Do not change the default unless you are absolutely sure in the results that you want to achieve by changing it. |
| tag_update_mode | string | no | no | n/a | Specifies action to be applied to the tags property of the objects Possible values:
This is an optional parameter to be used only when you want to change the tags property of the object. |
Queries
The queries define the criteria for processing the objects: what objects to rename/hide and in what workspaces to do so.
Query Structure
You can specify the queries as a CSV file or a database table with the following columns:
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| source_identifier | string | yes | n/a | The identifier of the workspace where objects to rename/hide belong to What you provide in this column depends on the value of the
NOTE: If you use client IDs for identifying the workspaces, you can also specify the data product that each workspace belongs to (see |
| object_identifier | string | yes | n/a | The identifier of the object |
| object_name | string | yes | n/a | The new name for the object |
| deprecated | Boolean | yes | n/a | The flag that controls whether the object is hidden or visible in the workspace
NOTE: The |
| summary | string | no | n/a | The description of the object NOTE: To handle empty string or null values in the description, use the |
| data_product | string | no | default | (Only when you use client IDs in |
| tags | string | no | n/a | (Only when you use The tag value is used in the action defined by the |
| tag_update_mode | string | no | n/a | (Only when you use Specifies the action that applies to the tags property of specified object. The action defined in |
Here is an example of the query where workspace IDs are used to identify the workspaces (see the source_identifier column):
| source_identifier | object_identifier | object_name | deprecated | summary |
|---|---|---|---|---|
| e863ii0azrnng2zt4fuu81ifgqtyeoj21 | fact.inventory_itemscustom.customfact3 | custom price | 0 | Custom prices for Warehouse |
| fuu81ifgqtyeoj21e863ii0azrnng2zt4 | attr.listingscustom.customattribute1 | custom listing item | 0 | |
| fuu81ifgqtyeoj21e863ii0azrnng2zt4 | listingscustomdate1.dataset.dt | custom listing date | 1 | Custom date for Warehouse |
Here is an example of the query where client IDs are used to identify the workspaces (see the source_identifier column) and the data product is specified for each workspace:
| source_identifier | object_identifier | object_name | deprecated | data_product |
|---|---|---|---|---|
| p3489 | fact.inventory_itemscustom.customfact3 | custom price | false | product_a |
| a9800 | attr.listingscustom.customattribute1 | custom listing item | false | product_a |
| m4801 | listingscustomdate1.dataset.dt | custom listing date | false | default |
Query Source
Object Renaming Utility can read the queries from the following input data sources (see Types of Input Data Sources):
- Amazon Redshift
- Amazon S3
- GoodData Data Warehouse (ADS)
- Google BigQuery
- Microsoft Azure Blob
- Microsoft Azure SQL Database
- Microsoft Azure Synapse Analytics
- Microsoft SQL Server
- MongoDB Connector for BI
- MySQL
- Snowflake
- PostgreSQL
If you want to store the queries in an object storage service, specify the queries in a CSV file. If you want to store the queries in a data warehouse, specify the queries as an SQL query to this data warehouse.
When building a JSON structure for the queries as Types of Input Data Sources specifies, replace the input_source parameter with the queries_input_source parameter.
Example: The queries stored in an S3 bucket
{
"s3_client": {
"bucket": "rename",
"accessKey": "123456789",
"secretKey": "secret",
"region": "us-east-1",
"serverSideEncryption": "true"
},
"queries_input_source": {
"type": "s3",
"file": "folder/object_rename.csv”
}
}
Example: The queries obtained from ADS
{
"ads_client": {
"username": "john.doe@example.com",
"password": "secret",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"queries_input_source": {
"type": "ads",
"query": "SELECT source_identifier, object_identifier, object_name, deprecated, summary, data_product FROM object_rename;"
}
}
Queries as Schedule Parameters
When providing the queries as schedule parameters, you have to code them using the gd_encoded_params parameter (see General Parameters).
To code the queries, follow the instructions in Specifying Complex Parameters. Once done, you should have the gd_encoded_params parameter coding the queries and reference parameters encoding sensitive information that you will be adding as secure parameters.
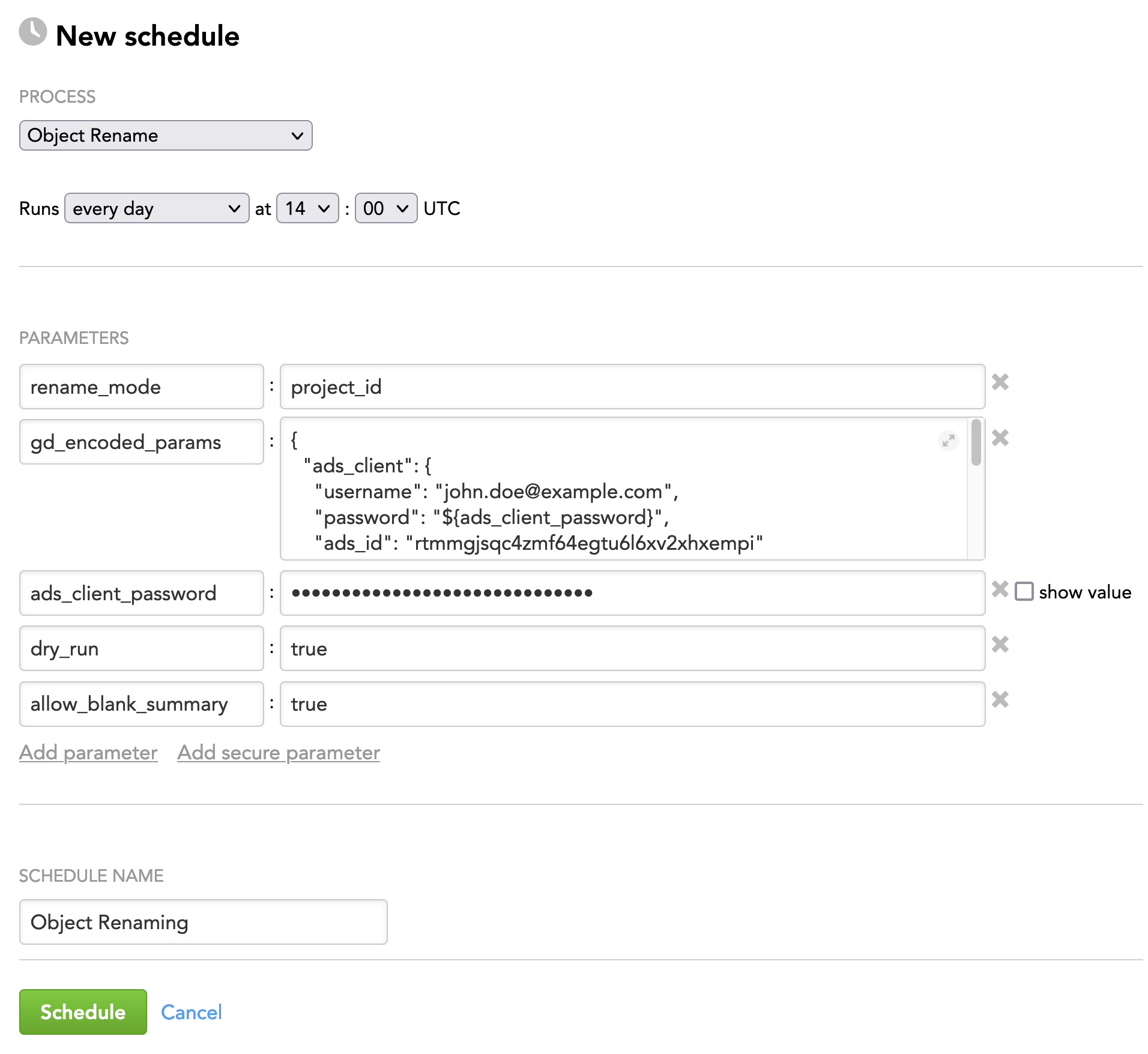
Example: The queries obtained from ADS (sensitive information present: ADS password) to be coded by the gd_encoded_params and a reference parameter encoding the ADS password
The following will become the value of the gd_encoded_params parameter:
{
"ads_client": {
"username": "john.doe@example.com",
"password": "${ads_client_password}",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"queries_input_source": {
"type": "ads",
"query": "SELECT source_identifier, object_identifier, object_name, deprecated, summary, data_product FROM object_rename;"
}
}
In addition, you have to add the reference parameter ads_client_password as a secure parameter.
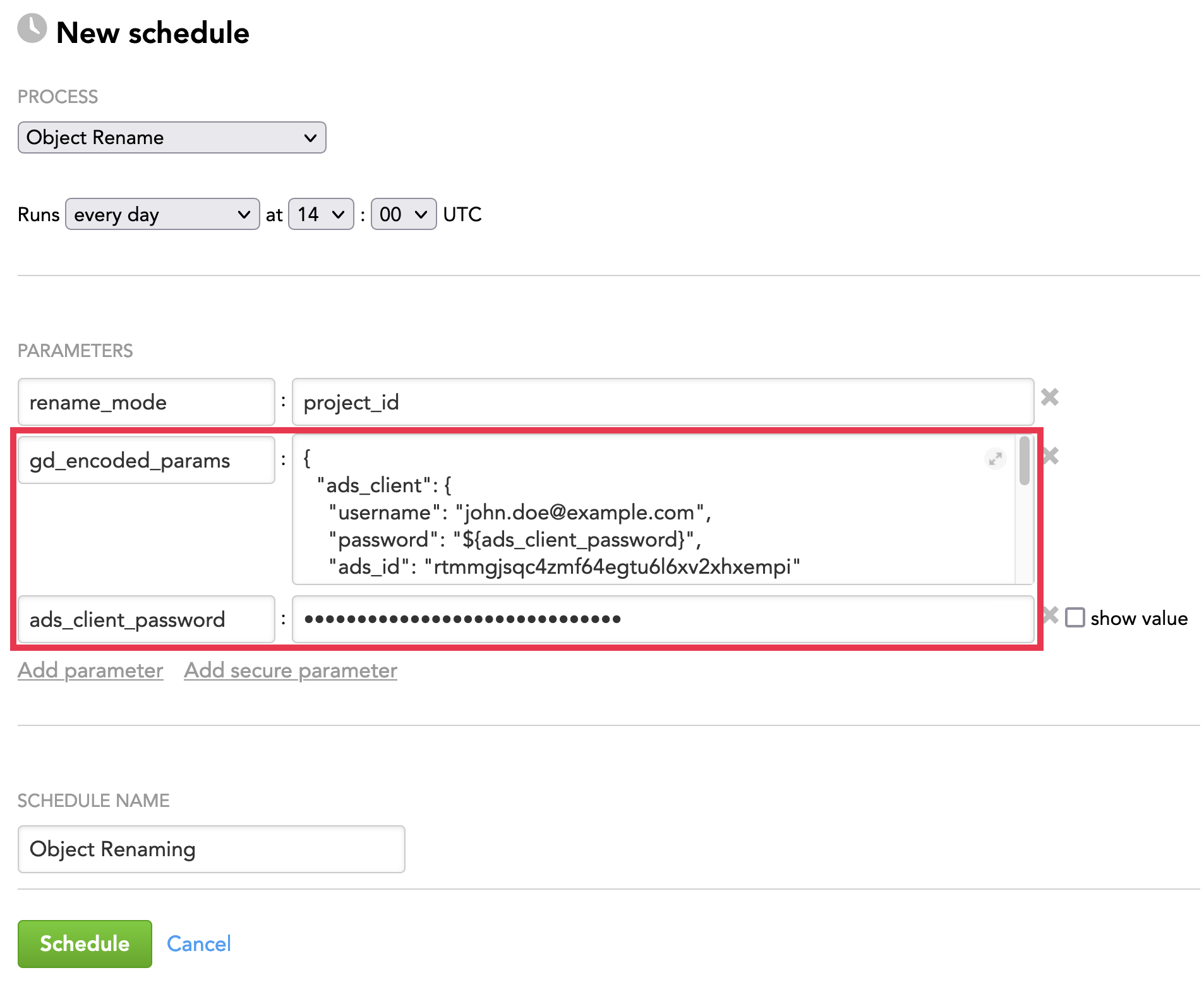
Schedule Example
The following is an example of how you can specify schedule parameters:
Logs and Error Handling
Object Renaming Utility generates a log with all the changes made and errors occurred.
- If an object specified in the queries cannot be found, Object Renaming Utility skips it, logs an error, and continues the execution as usual.
- If a workspace or data product specified in the queries cannot be found, Object Renaming Utility tries to process as many objects as it can but the execution finishes with a state of “Failed”.
By default, Object Renaming Utility fails when an error occurs. You can change this behavior by setting the dont_fail_on_error parameter to true (see General Parameters).
Advanced Settings
Run Object Renaming Utility Under a Different User
If you want to execute Object Renaming Utility under a different user than the default one, provide the following four parameters in the schedule. Otherwise, do not use any of these parameters and skip this section.
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Secure? | Default | Description |
|---|---|---|---|---|
| CLIENT_GDC_HOSTNAME | string | no | secure.gooddata.com | The white-labeled domain name in the format of The parameter name is case-sensitive and must be written in uppercase. |
| CLIENT_GDC_PROTOCOL | string | no | https | The protocol to transfer data over Explicitly set this parameter to The parameter name is case-sensitive and must be written in uppercase. |
GDC_USERNAME | string | no | n/a | The user under whom you want to execute Object Renaming Utility The parameter name is case-sensitive and must be written in uppercase. |
| GDC_PASSWORD | string | yes | n/a | The password for the user that you specified in the The parameter name is case-sensitive and must be written in uppercase. |