ADS Integrator
ADS Integrator is a component of the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). ADS Integrator takes the data that has been downloaded by a downloader (see Downloaders) and integrates it into Agile Data Warehousing Service (ADS) (see Data Warehouse Reference).
How ADS Integrator Works
The following picture shows how data for one entity is integrated into ADS when the default settings are used:
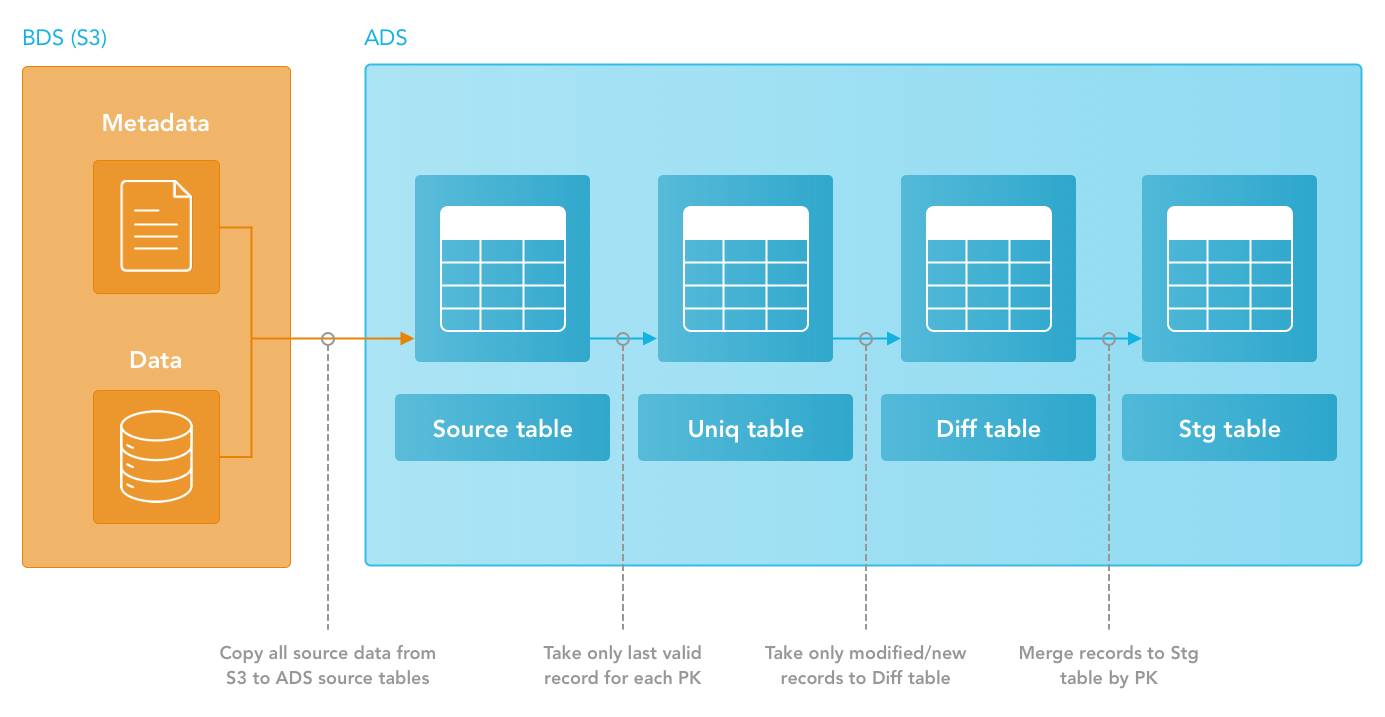
When integrating data downloaded by a downloader, ADS Integrator relies on the information stored in the S3 files' metadata and the S3 metadata folder. If you want to change any parameter in a downloader’s configuration, do so in the metadata files manually.
Data Tables
Source Table
The source tables are at the beginning of the data integration process. COPY commands integrate the prepared data from the BDS to the source tables.
If you use JSON files, the data first is integrated from the BDS to the flex tables and then copied from the flex tables to the source tables.
The naming convention of the source tables is the following: src_(downloader_name)_(entity_name)_merge
In some cases, the source tables can be used directly. However, when ADS Integrator runs with the default settings, data should be read from the stage tables. ADS Integrator adds system fields to each row.
The source tables have the following system fields:
| Name | Type | Description |
|---|---|---|
_sys_hub_id | string | The MD5 hash of all key fields |
| _sys_hash | string | The MD5 hash of all fields except the system fields |
| _sys_captured_at | timestamp |
|
| _sys_is_deleted | Boolean |
|
| _sys_filename | string | The name of the source file |
| _sys_load_id | integer | The reference to the '_sys_load_id' system table |
Stage Table
After successful integration, the data is loaded to the stage tables. Then, these tables are ready for use and the ETL can be connected here.
The naming convention of the stage tables is the following: stg_(downloader_name)_(entity_name)_merge
ADS Integrator adds system fields to each row.
The stage tables have the following system fields:
| Name | Type | Description |
|---|---|---|
_sys_id | string | The MD5 hash of all key fields. During integration, the value is copied from the '_sys_hub_id' field of the source table. |
| _sys_hash | string | The MD5 hash of all fields except the system fields. During the integration, the value is copied from the '_sys_hash' field of the source table. |
| _sys_valid_from | timestamp | During the integration, the value for this field is copied from the '_sys_captured_at' field of the source table. If multiple batches are integrated and each of them contains the same key, this value will contain the date when the key last occurred in the integrated data. |
| _sys_load_id | Boolean | During the integration, the value for this field is copied from the '_sys_load_id' field of the source table. |
| _sys_is_deleted | string | During the integration, the value for this field is filled when the record is marked as 'is_deleted' (deleted records). The deleted records are used when you want to remove some of already loaded values from the stage tables. The following options are available:
See the 'remove_deleted_records' parameter in Add optional parameters. |
Flex Table
If your source files are JSON files (see “Use JSON files as source files” in CSV Downloader), ADS Integrator first integrates the JSON source files from the BDS into flex tables before copying them to the source tables. When integrating the JSON files into the flex tables, ADS Integrator uses the Vertica fjsonparser parser to process the JSON files, either with or without flattening the nested data. Then, ADS Integrator processes the data from the flex tables according to the XPath notations specified in the feed file (see Feed File) and integrates the data into the source tables.
The naming convention of the flex tables is the following: src_(downloader_name)_(entity_name)_flex
The flex tables have the following system fields:
| Name | Type | Description |
|---|---|---|
__raw__ | string | The processed data from the source JSON files |
Rejected Table
If the ‘enable_rejected_table’ parameter is set to ‘true’, a special table is created for rejected records for each entity.
The naming convention of the rejected tables is the following: rejected_(downloader_name)_(entity_name)
In the rejected tables, you can use only SELECT queries. DML and DDL queries are not supported.
The maximum number of rows in a rejected table is to 100000. When this limit is reached, all the data is deleted from the table within the next run of ADS Integrator. To change the maximum allowed number of the rows in rejected tables, set the ‘rejected_table_cleanup_rows_limit’ parameter.
The rejected table contains the following fields:
| Name | Type | Description |
|---|---|---|
| node_name | varchar | The name of the Vertica node where the source file was located |
| file_name | varchar | The name of the file being loaded |
| session_id | varchar | The session ID number in which the COPY statement occurred |
| transaction_id | integer | The identifier for the transaction within the session, if any; otherwise, NULL |
| statement_id | integer | The unique identification number of the statement within the transaction that included the rejected data |
| batch_number | integer | (Internal use) The number of the batch (chunk) that the data comes from |
| row_number | integer | The rejected row number from the source file |
| rejected_data | long varchar | The data that was not loaded |
| rejected_data_orig_length | integer | The length of the rejected data |
| rejected_reason | varchar | The error that caused the rejected row This column returns the same message that exists in a load exceptions file when you do not save to a table. |
System Tables
Batch Table
The batch table is used only when ADS Integrator is running in batch mode.
The batch table contains information about the processed batches. If a batch is processed correctly, the batch table contains the STARTED event and the FINISHED event.
The batch table contains the following fields:
| Name | Type | Description |
|---|---|---|
id | integer | The unique numeric ID generated from the sequence |
| sequence | integer | The sequence number, if exists |
| identification | varchar | The identification of the batch In most cases, the identification is same as the ID of the downloader that was used for downloading this batch. |
| load_last_batch | timestamptz | The time when the batch was created on the BDS |
| filename | varchar | The name of the file from which the batch was created |
| load_event | varchar | The type of the event Possible values:
|
| load_time | timestamptz | The time when the event was created (by the now() function during the inserting) |
| is_deleted | Boolean |
|
Load Table
The load table is used in both batch mode and entity mode.
The load table contains information about the progress of the load for each entity.
The load table contains the following fields:
| Name | Type | Description |
|---|---|---|
load_id | integer | The unique numeric ID generated from the sequence |
| load_src | varchar | The type of the downloader that downloaded the entity |
| load_entity | varchar | The name of the entity |
| load_last_batch | timestamptz | The time when the file for the entity was saved on the BDS. If multiple files are integrated in one run, this field contains the last value. |
| load_event | varchar | The type of the event. Possible values:
|
| load_time | timestamptz | The time when the record was inserted into the database |
| is_deleted | Boolean |
|
| batch_id | integer | (Only for batch mode) The reference to the batch table |
File Table
The file table is used in both batch mode and entity mode.
The file table contains information about the integrated files and additional details on each of them.
The file table contains the following fields:
| Name | Type | Description |
|---|---|---|
id | integer | The unique numeric ID generated from the sequence |
| load_id | integer | The reference to the load table |
| load_at | timestamptz | The time when the file was loaded to the database |
| entity_name | varchar | The name of the entity connected to the file |
| filename | varchar | The original name of the file |
| bds_filename | varchar | The name of the file on the BDS |
| file_size | integer |
|
| file_hash | varchar |
|
Configuration File
Creating and setting up the integrator’s configuration file is the third phase of building your data pipeline (see Build Your Data Pipeline).
For more information about configuring a brick, see Configure a Brick.
Minimum Layout of the Configuration File
The following JSON samples are the minimum layout of the configuration file that ADS Integrator can use. The samples differ in load mode that ADS Integrator use:
- Batch mode
- Entity mode
Choose the mode that is compatible with the downloader that you are using:
- Choose batch mode when you want to process the data downloaded by CSV Downloader.
- Choose entity mode when you want to process the data downloaded by any downloader except for CSV Downloader.
Copy the appropriate sample and replace the placeholders with your values.
You can later enrich the sample with more parameters depending on your business and technical requirements (see Customize the Configuration File).
Batch Mode
Batch mode is supported by CSV Downloader only.
In batch mode, the data for all entities is put to the source tables first. Then, if all data is correctly copied to the source tables, the process continues. If an error occurred during integrating any of the entities into the batch, the whole process stops, and no data is integrated into the stage tables.
By default, ADS Integrator processes only one batch, but you can change this (see Specify the number of batches to process in one run).
{
"integrators": {
"ads_integrator_id": {
"type": "ads_storage",
"batches": ["csv_downloader_1","csv_downloader_2"]
}
},
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {}
}
}
Entity Mode
Entity mode is supported by all downloaders except for CSV Downloader.
In entity mode, entities are processed one by one. The data from one entity is loaded to the source tables and then integrated into the stage tables.
ADS Integrator processes all the files from one entity that are present in the BDS.
{
"integrators": {
"ads_integrator_id": {
"type": "ads_storage",
"entities": ["entity_1","entity_2","entity_3"]
}
},
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {}
}
}
The placeholders to replace with your values:
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| integrators -> ads_integrator_id | string | yes | n/a | The ID of the ADS Integrator instance Example: ads_integrator_1 |
| integrators -> ads_integrator_id -> batches | array | see 'Description' | n/a | (Batch mode only) The IDs of the CSV downloader instances that this ADS Integrator instance processes Example: csv_downloader_1 |
| integrators -> ads_integrator_id -> entities | array | see 'Description' | n/a | (Entity mode only) The names of the entities that this ADS Integrator instance processes Example: entity_1 |
| ads_storage -> instance_id | string | yes | n/a | The ID of the ADS instance into which the data is uploaded |
ads_storage -> username | string | yes | n/a | The access username to the ADS instance into which the data is uploaded |
Customize the Configuration File
You can change default values of the parameters and set up additional parameters.
When you set up an optional parameter, it is saved in the S3 file’s metadata (not in the metadata folder, but in an attribute of the file itself). To change the parameter value later, edit the metadata files manually.
Set the data integration strategy
The integration strategy defines how data is integrated into the stage tables on ADS.
- merge: This strategy uses one key for all operations (uniqueness, merging, and so on). This key is computed during the COPY command as an MD5 of all the fields that are marked as primary key in the ‘hub’ setting of the entity (see the system field ‘_sys_hub_id’ in the source table).
- merge_with_pk: This strategy uses all primary keys for all operations (uniqueness, merging, and so on).
The final output is the same for either strategy. The only difference is how the final projection created on stage tables is optimized.
For the merge integration strategy, the projection is optimized for one ID field.
For the merge_with_pk strategy, the projection is optimized for all primary keys in the order they are set up in the entity’s settings (the ‘hub’ parameter in the section of the configuration file that describes the downloader you are using):
"entities": { "table_1_name": { "global": { "custom": { "hub": ["column_1_name","column_2_name","column_3_name"] } } } }
If you want to set a different data integration strategy for a specific entity, use the advanced parameter ‘default_strategy_override’ (see Adjust advanced settings).
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {
"default_strategy": "merge|merge_with_pk" // optional
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| default_strategy | string | no | merge | The data integration strategy used to integrate data into the stage tables on ADS
|
Add multiple ADS Integrators
You can use multiple instances of ADS Integrator to process your downloaders. Update the ‘integrators’ section to contain multiple subsections: a subsection per ADS Integrator instance. Each subsection must refer the ID of the corresponding ADS Integrator instance.
Depending on what downloaders you are using, you need to specify load mode for each ADS Integrator instance: batch mode or entity mode.
"integrators": {
"ads_integrator_1_id": {
"type": "ads_storage",
"batches": ["csv_downloader_1","csv_downloader_2"]
},
"ads_integrator_2_id": {
"type": "ads_storage",
"batches": ["csv_downloader_3"]
},
{
"ads_integrator_3_id": {
"type": "ads_storage",
"entities": ["entity_1","entity_2","entity_3"]
},
"ads_integrator_4_id": {
"type": "ads_storage",
"entities": ["entity_4","entity_5","entity_6"]
}
}
Use a different server
By default, ADS Integrator uses secure.gooddata.com to access to the ADS instance. You can specify a different URL (for example, you are a white-labeled customer).
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"server": "your.server.url", // optional
"options": {}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| server | string | no | secure.gooddata.com | The URL used to access the ADS instance |
Use COPY FROM S3 instead of COPY FROM LOCAL
If your source files are stored in an S3 location (see ‘Use an S3 location’ in CSV Downloader), the files are first downloaded from the S3 location and then loaded using the COPY FROM LOCAL command. Using COPY FROM S3 loads the files directly from the S3 location which may be faster.
- If you use your own S3 location and not a GoodData-managed one, contact GoodData Support so that they enable data load from your S3 location to your ADS instance. In the request, include the ID of your ADS instance (see the ‘instance_id’ parameter in Minimum Layout of the Configuration File) and the name of the S3 bucket.
- If you decide to use COPY FROM S3 and at the same time choose not to enable rejected tables (see the ‘enable_rejected_table’ parameter), you will not be able to review rejected records because they will be skipped and not stored anywhere.
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {
"copy_from_s3": true|false
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| copy_from_s3 | Boolean | see 'Description' | false | Specifies what COPY command is used for downloading the data from an S3 location.
NOTE: If you use Parquet source files (see 'Use Parquet files as source files' in CSV Downloader), set this parameter to 'true'. |
Specify how to proceed in case of errors and rejected records
By default, if an error occurs and some data cannot be integrated into ADS, ADS Integrator fails. To make ADS Integrator ignore errors, set the ‘abort_on_error’ parameter to ‘false’. This disables the ABORT ON ERROR option in each COPY command.
To additionally specify how to treat the records that have not been parsed during the process and have been rejected, use the optional ‘enable_rejected_table’ parameter.
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {
"abort_on_error": true|false, // optional
"enable_rejected_table": true|false // optional
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| abort_on_error | Boolean | no | true | Specifies whether the ABORT ON ERROR option in each COPY command is enabled or disabled.
|
| enable_rejected_table | Boolean | no | false | (Only when 'abort_on_error' is set to 'false') Specifies how ADS Integrator treats the rejected records.
NOTE: You can also set the 'enable_rejected_table' parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| rejected_table_cleanup_rows_limit | integer | no | 100000 | The maximum number of rows allowed in a rejected table When the maximum number is reached, all the data is deleted from the table within the next run of ADS Integrator. IMPORTANT: The default value is sufficient for an average workspace on a standard ADS instance. Setting it to a greater value may result in consuming too much space on your ADS instance. Do not change the default unless you are absolutely sure in the results that you want to achieve by changing it. |
To be notified of the ignored records, set up a notification triggered by a custom event (see Create a Notification Rule for a Data Loading Process). Set error-in-data-processing as the custom event triggering the notification, and use the {$params.list_of_files} variable in the message body, which will include a list of ignored files in the notification email.
Add optional parameters
Depending on your business and technical requirements, you can set one or more optional parameters affecting the data integration process.
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"disable_file_level_logging": true|false, // optional
"options": {
"integration_group_size": number_of_files, // optional
"remove_deleted_records": true|false, // optional
"group_by_version": true|false // optional
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| disable_file_level_logging | Boolean | no | false | Specifies whether ADS Integrator logs information to the _sys_file table
Set this parameter to 'true' if you want to disable the '_sys_filename' field (see Source Table for more information about the '_sys_filename' field; see the 'ignored_system_fields' parameter in Adjust advanced settings for more information about disabling system fields). |
| integration_group_size | integer | no | 1 | The number of files to be integrated in one COPY command NOTE:
|
| remove_deleted_records | Boolean | no | false | Specifies how to handle the records in the stage table that have the '_sys_is_deleted' field set to 'true'.
NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| group_by_version | Boolean | no | false | (For CSV Downloader only) Specifies how ADS Integrator processes different versions of the same data records in the source data (see 'version' in Feed File) in one run
|
Configure additional settings in the source table and stage table
To extend the source table and stage table with additional settings, configure computed fields. For more details, see Computed Fields.
Add system fields to the load table or file table
To add the system fields to the load table or file table, configure system fields. Data can populate these fields only from the runtime metadata. The runtime metadata is filled in by downloaders. To find out what metadata a downloader creates, see the corresponding downloader’s article in Downloaders.
The ‘system_table_fields’ section contains arrays of parameters for the load table and file table.
"system_table_fields": {
"file_table": [
{
"name": "custom_parameter",
"type": "parameter_data_type",
"function": "function_name"
}
],
"load_table": [
{
"name": "custom_parameter",
"type": "parameter_data_type",
"function": "function_name"
}
]
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| name | string | yes | n/a | The name of the custom parameter |
| type | string | yes | n/a | The type of the custom parameter Possible values:
|
| function | string | yes | n/a | The function that will fill in the system field with the runtime metadata parameter Format: Example: |
Example:
"system_table_fields": {
"file_table": [
{
"name": "load_param",
"type": "string-255",
"function": "runtime_metadata|load_param"
}
]
}
Specify the number of batches to process in one run
When working with batch mode, you can specify how many batches ADS Integrator should process in one run.
[Example]{.ul}: Entity data in all batches is in incremental load mode You have 10 batches to process, and the number of batches in one run is set to 5.
The 10 batches will be processed in the next two runs of ADS Integrator.
ADS Integrator downloads all the data for the number of the batches that you have specified and checks whether all entities have only one version of metadata.
- If yes, ADS Integrator will process all data in one run: copy all the data to the source table and then use MERGE to put it to the stage table.
- If not, ADS Integrator will split the data into multiple parts and process them independently. The order of the batches will be preserved.
[Example]{.ul}: Some entity data is in full load mode, the rest is in incremental load mode You have 10 batches to process, and the number of batches in one run is set to 5. The entity data in Batch 5 and Batch 8 are marked as ‘full’.
In the first run, ADS Integrator takes the batches from 1 through 5. Batch 5 is the one with full load mode, so ADS Integrator ignores all incremental batches before this batch and only processes Batch 5.
In the second run, ADS Integrator ignores Batch 6 and Batch 7 (incremental mode), then processes Batch 8 (full mode), and then processes incremental batches: Batch 9 and Batch 10.
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {
"number_of_batches_in_one_run": number_of_batches // optional
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| number_of_batches_in_one_run | integer | no | 100 | The number of batches that ADS Integrator should process in one run |
Use link files
When you are using CSV Downloader and chose to use link files (see ‘Use link files’ in CSV Downloader), set ADS Integrator that processes this instance of CSV Downloader to use the link files.
If your source files are PGP-encrypted, see Enable processing of PGP-encrypted source files when using link files.
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {
"remote": {
"type": "s3",
"access_key": "access_key",
"bucket": "bucket_name"
}
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| access_key | string | yes | n/a | The access key to the S3 bucket where the source data is stored |
| bucket | string | yes | n/a | The name of the S3 bucket where the source data is stored |
When later scheduling this ADS Integrator instance in the Data Integration Console, provide the ‘ads_integrator|options|remote|secret_key’ parameter in the schedule (see General Parameters).
Enable processing of PGP-encrypted source files when using link files
When you are using link files in CSV Downloader (see ‘Use link files’ in CSV Downloader) and your source files are PGP-encrypted, enable ADS Integrator that processes this instance of CSV Downloader to process encrypted files.
Steps:
Set ADS Integrator that processes this instance of CSV Downloader to use the link files.
"ads_storage": { "instance_id": "data_warehouse_instance_id", "username": "dw_email@address.com", "options": { "remote": { "type": "s3", "access_key": "access_key", "bucket": "bucket_name" } } }Name Type Mandatory? Default Description access_key string yes n/a The access key to the S3 bucket where the source data is stored bucket string yes n/a The name of the S3 bucket where the source data is stored Add the ‘encryption’ parameter under ‘ads_storage’ -> ‘options’, and give it a unique name (for example, ‘encryption_1’).
"ads_storage": { "instance_id": "data_warehouse_instance_id", "username": "dw_email@address.com", "options": { "remote": { "type": "s3", "access_key": "access_key", "bucket": "bucket_name" }, "encryption": "encryption_1" } }Add a new section to the configuration file and name it with the same unique name that you used for the ‘encryption’ parameter. In this example, it is ‘encryption_1’. This section should contain one parameter, ‘type’, set to ‘pgp’:
"encryption_1": { "type": "pgp" }When later scheduling this ADS Integrator instance in the Data Integration Console, provide the ‘ads_integrator|options|remote|secret_key’ parameter (see General Parameters) and the parameters that are related to the decryption of the PGP-encrypted source files (see Encryption-Specific Parameters).
Adjust advanced settings
ADS Integrator allows you to adjust various advanced settings, which, for example, can help improve performance.
Change these settings only if you are confident in executing the task or have no other options. Adjusting the advanced settings in a wrong way may generate unexpected side effects.
Proceed with caution.
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {
"resource_pool": "resource_pull", // optional
"pool_timeout": number_of_seconds, // optional
"integrate_without_sys_hash": true|false, // optional
"keep_values_when_deleted": true|false, // optional
"default_strategy_override": {"entity_1": "strategy_name","entity_2": "strategy_name"}, // optional
"max_connections": number_of_connections, // optional
"connection_refresh_time": number_of_minutes, // optional
"multi_load": true|false, // optional
"use_direct_hint_in_copy": true|false, // optional
"truncate_source_tables": true|false, // optional
"disable_statistics_stg": true|false, // optional
"disable_sys_load_id_logging": true|false, // optional
"disable_sys_id": true|false, // optional
"use_uniq_table": true|false, // optional
"insert_to_stage": true|false, // optional
"skip_projection_check": true|false, // optional
"segmentation": segmented|unsegmented, // optional
"partition_by": "field_name", // optional
"drop_source_partition": true|false, // optional
"source_projection": { <custom_segmentation> }, // optional
"ignored_system_fields": "["sys_field_1","sys_field_2"]", // optional
"join_files": true|false, // optional
"finish_in_source": true|false, // optional
"recreate_source_tables": true|false, // optional
"number_of_parallel_queries": number_of_copy_commands, // optional
"number_of_parallel_entities_integrations": number_of_entities_to_source, // optional
"number_of_parallel_integrations": number_of_entities_to_stage // optional
}
}
Change these settings only if you are confident in executing the task or have no other options. Adjusting the advanced settings in a wrong way may generate unexpected side effects.
Proceed with caution.
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| resource_pool | string | no | n/a | The resource pool to connect to the database |
| pool_timeout | integer | no | 240 | The maximum timeout (in seconds) specifying how long ADS Integrator waits for a new connection to be created |
| integrate_without_sys_hash | Boolean | no | false | Specifies whether '_sys_hash' (see Source Table and Stage Table) is used.
Set this parameter to 'true' if you want to disable the '_sys_hash' field (see Source Table and Stage Table for more information about the '_sys_hash' field; see the 'ignored_system_fields' parameter in this table for more information about disabling system fields). WARNING: Suppressing the '_sys_hash' field may result in reduced integration performance due to potentially costly hash joins. Proceed with caution. NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| keep_values_when_deleted | Boolean | no | false | (Full loads only) Specifies how to handle the latest values in the records that are marked to be deleted from the ADS instance.
|
| default_strategy_override | JSON | no | { } (empty hash, as in: | Sets a different data integration strategy for a specific entity (a different value than the 'default_strategy' parameter sets, see Set the data integration strategy) Example: |
| max_connections | integer | no | 50 | The maximum number of open connections to ADS |
| connection_refresh_time | integer | no | 15 | The period (in minutes) after which the connection gets refreshed |
| multi_load | Boolean | no | false | Specifies whether multi-load mode is enabled (that is, one entity can be loaded by multiple instances of ADS Integrator) By default, one entity can be loaded by only one instance of ADS Integrator. For performance reasons, you may want to allow multiple instances of ADS Integrator to load the same entity. For example, if you have an entity that is downloaded by 10 downloaders, you may want to process this entity with two instances of ADS Integrator.
|
| use_direct_hint_in_copy | Boolean | no | true | Specifies whether the DIRECT hint is allowed in the COPY command
NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| truncate_source_tables | Boolean | no | true | Specifies whether to truncate the source table and to recreate the used sequences
NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| disable_statistics_stg | Boolean | no | false | Specifies whether the ANALYZE_STATISTICS function is forbidden for use on the stage tables
NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| disable_sys_load_id_logging | Boolean | no | false | (For CSV Downloader only) Specifies whether logging to the '_sys_load_id' system table is enabled
|
| disable_sys_id | Boolean | no | false | Specifies whether the '_sys_id' field (see Stage Table) and the '_sys_hub_id' field (see Source Table) are used
|
| use_uniq_table | Boolean | no | true | Specifies whether input data should be loaded to the uniq table
NOTE: Use this parameter only when you are sure that the input data does not contain duplicates. |
| insert_to_stage | Boolean | no | false | Specifies whether the MERGE command is used when the data is inserted into the stage table
|
| skip_projection_check | Boolean | no | false | Specifies whether to check for the correct projection.
NOTE: Set this parameter to 'true' if you want to set custom segmentation and the order in projections (see the 'source_projection' parameter in this table). |
| source_projection | JSON | no | n/a | Sets custom segmentation and the order in projections Example: NOTES:
|
| segmentation | string | no | n/a | The expression to segment a table by To prevent segmentation, set this parameter to 'unsegmented'. NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| partition_by | string | no | n/a | The name of the field to set the partition to NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| drop_source_partition | Boolean | no | false | (Only for CSV Downloader) Specifies whether to drop the partition in the source tables (see Source Table)
NOTE: You can also set this parameter at the entity level. To do so, add it to the 'custom' section of the entity. |
| ignored_system_fields | array | no | false | The system fields added by ADS Integrator to each table that you want to disable NOTE: To be able to use this parameter, set 'finish_in_source' to 'true' (see the 'finish_in_source' parameter in this table). Additionally:
|
| join_files | Boolean | no | false | Specifies whether to join files to one bigger file before sending them to ADS
NOTE: The files must not have headers. Using this parameter is not recommended for files greater than 100 Mb. |
| finish_in_source | Boolean | no | false | Specifies whether to end data integration at the source table phase
Set this parameter to 'true' if you want to disable some system fields that ADS Integrator adds to each table (see the 'ignored_system_fields' parameter in this table). |
| recreate_source_tables | Boolean | no | false | Specifies how to handle the source tables
|
| number_of_parallel_queries | integer | no | 8 | The number of COPY commands to run in parallel when integrating one entity (see How ADS Integrator Works) SQL operation to run: COPY FROM LOCAL Example: If ADS Integrator processes 100 batches and each batch has 5 files for the entity, the total number of files that needs to be processed is 500. If you set the 'number_of_parallel_queries' parameter to 10, ADS Integrator will create 10 slots for COPY commands (up to 10 COPY commands can run simultaneously). Therefore, in the ideal case, the 500 files will be processed 10 times as fast as when this setting is set to 1. IMPORTANT: The default value is sufficient for an average workspace on a standard ADS instance. Do not change the default unless you are absolutely sure in the results that you want to achieve by changing it. |
| number_of_parallel_entities_integrations | integer | no | 1 | (Batch mode only) The number of entities to be integrated in parallel to the source table (see How ADS Integrator Works). The operations performed during integration are similar to those performed when you have the 'finish_in_source' parameter set to 'true' (see the 'finish_in_source' parameter in this table). SQL operations to run:
Example: If you set this parameter to 2 and the 'number_of_parallel_queries' parameter is set to 5, then you have 5 entities, and each of these entities has multiple files for processing. ADS Integrator will create 2 slots (based on 'number_of_parallel_entities_integrations'). Inside these 2 slots, ADS Integrator will create another 5 slots for COPY commands. As a result, you are going to have up to 10 COPY commands running simultaneously, 5 for each entity. IMPORTANT: The default value is sufficient for an average workspace on a standard ADS instance. Do not change the default unless you are absolutely sure in the results that you want to achieve by changing it. |
| number_of_parallel_integrations | integer | no | 1 | (Batch mode only) The number of entities to be integrated in parallel to the stage table (filling in the uniq table, the diff table, and the stage table; see How ADS Integrator Works) SQL operations to run:
Example: If you have 10 entities and you set this parameter to 2, ADS Integrator will create 2 slots for the integration command. If all the entities have the same amount of data, the integration (without loading to the source table) runs twice as fast as when this setting is set to 1. IMPORTANT: The default value is sufficient for an average workspace on a standard ADS instance. Do not change the default unless you are absolutely sure in the results that you want to achieve by changing it. |
Schedule Parameters
When scheduling ADS Integrator (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
Some parameters contain the names of the nesting parameters, which specifies where they belong in the configuration hierarchy. For example, a parameter entered as ads|options|password is resolved as the following:
"ads": {
"options": {
"password": ""
}
}
Enter such parameters as is (see Schedule Example).
| Name | Typ | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| ID | string | yes | no | n/a | The ID of the ADS Integrator instance being scheduled Example: ads_integrator_1 |
| server_side_encryption | Boolean | no | no | false | Specifies whether ADS Integrator can work with an S3 location where server-side encryption is enabled
|
| ads_storage|password | string | yes | yes | n/a | The password for the user that is specified in the configuration file under ads_storage -> username The user and the password are used to access the specified ADS instance where the data will be uploaded to. |
| ads_integrator|options|remote|secret_key | string | see 'Description' column | yes | n/a | (Only when ADS Integrator uses link files) The access key to the S3 bucket where the source data is stored |
Encryption-Specific Parameters
If you enable processing of PGP-encrypted source files when using link files, provide the encryption-specific parameters as secure schedule parameters (see Configure Schedule Parameters).
Some parameters contain the names of the nesting parameters, which specifies where they belong in the configuration hierarchy. For example, a parameter entered as csv|options|password is resolved as the following:
"csv": {
"options": {
"password": ""
}
}
Enter such parameters as is (see Schedule Example).
| Parameter Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| encryption_name|private_key | string | yes | yes | n/a | The private key used for decrypting the PGP-encrypted files If the private key itself is encrypted, also provide the passphrase to decrypt it (see the 'encryption_name|passphrase' parameter). NOTE: Although you are entering the private key as a secure parameter, its value will be visible right after you paste it in the parameter value field (the show value check-box is selected) because it is a multi-line string. To hide the value, un-select the show value check-box. When the schedule is saved, the value will not appear in clear-text form in any GUI or log entries. For more information, see Configuring Schedule Parameters. |
encryption_name|passphrase | string | see 'Description' | yes | n/a | The passphrase used to decrypt the private key if it is encrypted This parameter is mandatory only when the private key (see the 'encryption_name|private_key' parameter) is encrypted. Otherwise, do not use it. |
Schedule Example
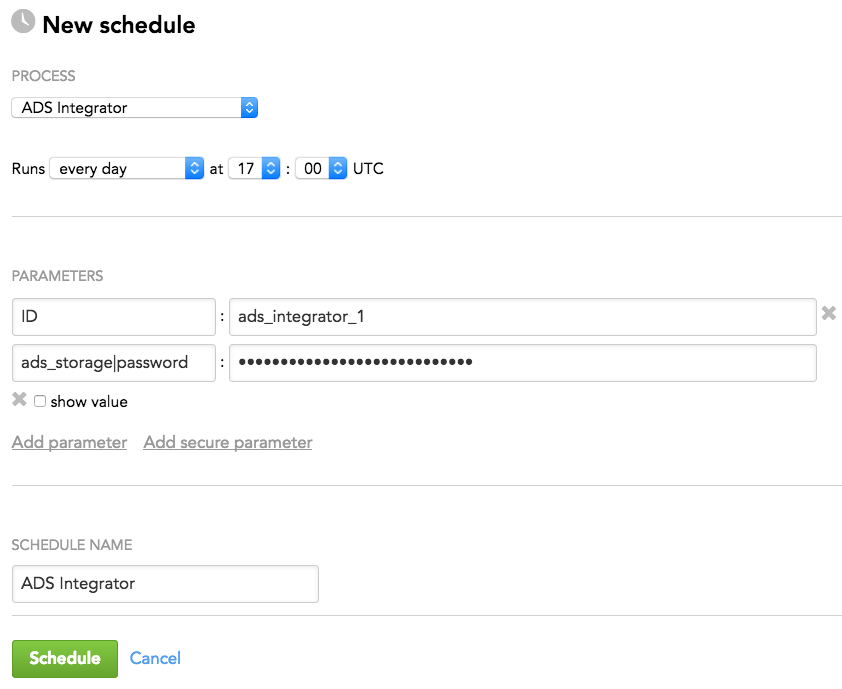
The following is an example of how you can specify schedule parameters:
Best Practices
For better performance, we recommend that you apply the following best practices when using ADS Integrator:
- Keep the total size of the files in one integration group below 1 GB. An integration group is usually a part of the manifest file containing x files, where x is the value of the ‘integration_group_size’ parameter (see Add optional parameters). The default of this parameter is 1, therefore unless you change it, the files are integrated one by one.
- When processing many smaller files, set the ‘integration_group_size’ parameter to a higher value to copy all the files in a single COPY command (see Add optional parameters). Note, however, that setting this parameter to a higher value will stop loading new rows to the file table.
- Do not use the ‘integration_group_size’ parameter if you have multiple versions of a data record in your source data.
- For better performance on big tables, set the ‘disable_statistics_stg’ parameter to ‘true’ (see Adjust advanced settings).
- Use the ‘skip_projection_check’ parameter (see Adjust advanced settings) only as a last resort or a temporary solution.
- Use the ‘integrate_without_sys_hash’ parameter (see Adjust advanced settings) carefully. Suppressing the ‘_sys_hash’ field may result in reduced integration performance due to potentially costly hash joins.
- Make sure that the source table and stage table have the same columns so that optimized MERGE is used.