SQL Executor
SQL Executor is a component of the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). SQL Executor executes SQL commands to transform the data stored in Agile Data Warehousing Service (ADS) before it gets distributed to workspaces.
SQL Executor allows you to do the following:
- Execute SQL statements in parallel
- Iterate SQL statements
- Propagate parameters from ADS or the schedule of a deployed SQL Executor instance
- Customize the order of executing script files using a control file
- Generate SQL commands from templates written in the Liquid template language
The following time limitations are applied:
- The maximum time of running an SQL Executor process is 5 hours.
- The maximum time of running a single query is 2 hours.
Supported File Types
SQL Executor can process the following types of script files:
Standard SQL scripts (.sql) are used to run SQL commands. A standard SQL script file can contain one or more SQL commands. If a script file contains multiple commands, the commands are processed one after the other in one thread. SQL comments are supported.
PSQL scripts (.psql) are used to populate SQL Executor parameters from ADS. You can read up to 100 parameter values from ADS. A PSQL script must start with the following expression on the first line:
/* DEFINE(parameter_name) */ISQL scripts (.isql) are used for iteration over a set of SQL commands. An ISQL script must start with the following expression on the first line:
/* ITERATION(parameter_name) */By default, commands in an ISQL script run sequentially. To make them run in parallel, specify the number of parallel threads as follows:
/* ITERATION(parameter_name,number_of_threads) */For example:
/* ITERATION(partitions,4) */When deciding on the number of parallel threads to specify, consider the general workload and other running processes. Too many parallel threads may slow down performance.
Additionally, SQL Executor can process auxiliary files that facilitate work with the script files:
- Control files (.csv) are used to customize the order of executing script files (alternatively to automatic mode when the script files are processed by phase numbers).
- Liquid template files (.liquid) are used to create complex SQL scripts.
- Parameter definition files (.json, .yaml) provide a structured source of parameters for the templates.
Naming Conventions for Script Files
SQL Executor expects script file names to be in the following format:
{phase_number}_{script_name}.{extension}
- {phase_number} is the number of the phase when the script should be executed. Group your scripts into phases to define the execution order. For example, any script in Phase 2 will not be executed until all scripts in Phase 1 have finished.
- {script_name} is the name of the script.
- {extension} is the file extension. The extension can be one of the following:
- sql is a simple SQL script.
- psql is a script used for reading parameters from ADS.
- isql is a script iterating through a predefined collection of parameters.
Example:
1_insert_1.sql
1_insert_2.sql
2_load_params.psql
3_drop_table.sql
4_iteration_1.isql
4_iteration_2.isql
S3 Folder Structure
SQL Executor expects the following structure of your S3 location:
| Folder | Purpose | Note |
|---|---|---|
{SOURCE_ROOT} | The root folder | The folder where SQL scripts are stored You specify this folder by the 'folder' parameter in SQL Executor schedule parameters. |
{SOURCE_ROOT}/param_definitions/ | The location of parameter definition files | This folder is required only if you have parameter definition files. Otherwise, it is optional. |
{SOURCE_ROOT}/templates/ | The location of Liquid template files | This folder is required only if you have Liquid template files. Otherwise, it is optional. |
If you have control files, specify their location in the ‘control_file_path’ parameter in SQL Executor schedule parameters.
Configuration File
SQL Executor does not require any parameters in the configuration file.
Schedule Parameters
When scheduling SQL Executor (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
folder | string | yes | no | n/a | The folder in your S3 location where SQL scripts are stored and that acts as the root folder for SQL Executor (see S3 Folder Structure) Format: |
| access_key | string | yes | no | n/a | The access key for the S3 location |
| secret_key | string | yes | yes | n/a | The secret key for the S3 location |
| ads_instance_id | string | yes | no | n/a | The ID of the ADS instance where the data is located |
| ads_username | string | yes | no | n/a | The access username to the ADS instance where the data is located |
| ads_password | string | yes | yes | n/a | The password to access the ADS instance where the data is located |
| ads_server | string | no | no | the domain where SQL Executor is running | The URL used to access the ADS instance |
| control_file_path | string | no | no | n/a | The path to the control file in the S3 location (see Supported File Types) Format: |
cc_path | string | no | no | empty | The path to COPY command files on the S3 location that you want to download before executing SQL scripts Format: s3://your_bucket/path/to/files/ |
| resource_pool | string | no | no | empty | The resource pool to connect to the database |
| number_of_threads | integer | no | no | 4 | The number of SQL commands executed in parallel |
| region | string | no | no | n/a | The code of the region of the S3 bucket where SQL scripts are stored Use this parameter if your S3 bucket is not in the North America region. |
Schedule Example
The following is an example of how you can specify schedule parameters:
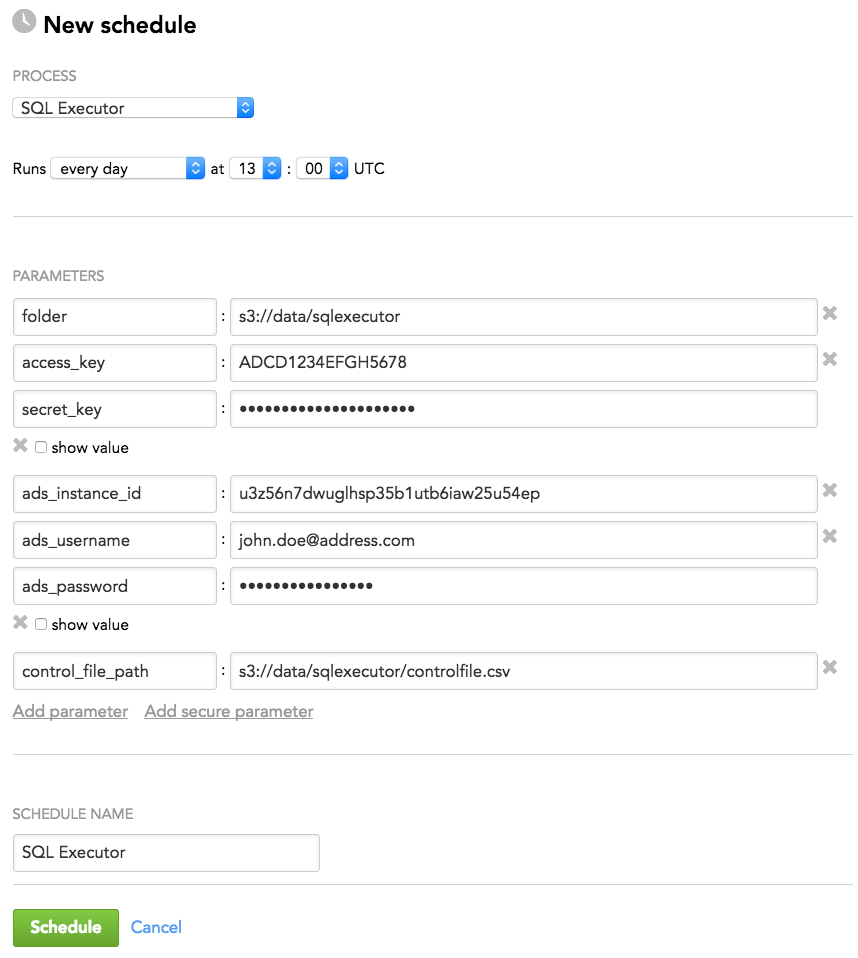
Supported Features
SQL Executor supports various features. Some features are available for specific file types that are noted in parentheses.
- (PSQL) Read parameters from ADS
- (PSQL, ISQL) Iterate parameters obtained from ADS
- (SQL, PSQL, ISQL) Control script execution using conditions
- Reference a schedule parameter in a script
- Generate complex scripts using Liquid template files
- Customize the order of executing script files
(PSQL) Read parameters from ADS
In a PSQL script file, you can define a script that loads a parameter key/value combination from ADS. You can read up to 100 parameter values from ADS.
A PSQL script must start with the following expression on the first line:
/* DEFINE(parameter_name) */
The command following this expression must be an SQL SELECT statement returning two columns named ‘key’ and ‘value’. If the SELECT statement returns two lines with the same key, only the last line is used.
In all script files executed after the PSQL script, you can reference the parameter by ${parameter_name['key']}.
Example: You have the ‘Settings’ source table:
| Id | Setting |
|---|---|
| type | GOLD |
| environment | Linux |
| browser | Chrome |
In your PSQL script file, you provide the following script:
/* DEFINE(settings) */
SELECT Id AS "Key", Setting AS "Value" FROM Settings
The following SQL script is executed after the PSQL script:
DELETE FROM Customers WHERE type = '${settings['type']}' AND browser = '${settings['browser']}';
SQL Executor executes the SQL script as follows:
DELETE FROM Customers WHERE type = 'GOLD' AND browser = 'Chrome';
(PSQL, ISQL) Iterate parameters obtained from ADS
In a PSQL script file, you can define a script that returns a list through which you can iterate by a subsequent SQL statement. This script must return the ‘key’ column and any number of columns that are used as parameters in ISQL script files. If the SELECT statement returns two lines with the same key, only the last line is used.
Example: You have the ‘custom_partitions’ source table:
| table_name | partition |
|---|---|
| account | 55 |
| account | 60 |
| opportunity | 55 |
| opportunity | 60 |
| product | 55 |
| product | 60 |
In your PSQL script file, you provide the following script:
/* DEFINE(partitions) */
SELECT row_number() OVER (order by table_name) AS "key",table_name AS table_name,partition AS partition FROM custom_partitions
In your ISQL script file, you provide the following script:
/* ITERATION(partitions) /
SELECT DROP_PARTITION('${table_name}', ${partition});
SQL Executor executes the ISQL script as follows:
SELECT DROP_PARTITION('account', 55);
SELECT DROP_PARTITION('account', 60);
SELECT DROP_PARTITION('opportunity', 55);
SELECT DROP_PARTITION('opportunity', 60);
SELECT DROP_PARTITION('product', 55);
SELECT DROP_PARTITION('product', 60);
(SQL, PSQL, ISQL) Control script execution using conditions
Use conditions to control the script execution.
To specify a condition, use the following expression:
/* CONDITION(parameter_name) */
- When the parameter used in the condition is set to 1 (integer or string), the script is executed.
- When the parameter is set to any other value, the script is not executed.
Example: In your SQL script file, you provided the following scripts:
/* CONDITION(DELETE_TABLE) */
DELETE * FROM my_test_table;
/* CONDITION(TEST_COLLECTION['enabled']) */
DELETE * FROM my_test_table;
SQL Executor executes the PSQL script as follows:
/* CONDITION(TEST_COLLECTION['enabled']) */
/* DEFINE(partitions) */
SELECT row_number() over (order by table_name) as "key",table_name as table_name,partition as partition from custom_partitions;
Reference a schedule parameter in a script
You can enter additional schedule parameters (see Schedule Parameters) and refer to them in a script using ${parameter_name}. When executing, SQL Executor replaces ${parameter_name} with the appropriate parameter value from the schedule.
Example: You enter the ‘customer_type’ parameter in the schedule and set it to ‘GOLD’.
In your SQL script file, you provide the following script:
SELECT Id, Name FROM Customers WHERE customer_type = '${customer_type}';
SQL Executor executes the script as follows:
SELECT Id, Name FROM Customers WHERE customer_type = 'GOLD';
Generate complex scripts using Liquid template files
When you need to use long or complex SQL scripts, generate them using Liquid template files (*.liquid).
A Liquid template file can be called from any SQL script using a function call where the function name refers to the name of the template file. For example, ‘test_template.liquid’ would have the function name ‘test_template’. If the function call includes too many parameters, specify them in a parameter definition file.
The template files must be stored in {SOURCE_ROOT}/templates/ folder (see S3 Folder Structure).
Example: You provide the following Liquid template file named ‘test_template.liquid’:
INSERT INTO {{table_name}}
(
{% for field in fields %}{{ field }} {% unless forloop.last %},{% endunless %}{% endfor %}, {{custom_field}}
)
SELECT
{% for field in fields %} a.{{ field }} {% unless forloop.last %},{% endunless %}{% endfor %}, a.{{custom_field}}
FROM {{another_table}} a;
Your SQL script file has the following function call:
...some SQL code...
#{test_template(table_name="test_table_target",
another_table="test_table_source", fields=["name","country"],
custom_field="hash")}
...some other SQL code...
SQL Executor executes the SQL script as follows:
INSERT INTO test_table_target
(
name, country, hash
)
SELECT a.name, a.country, a.hash
FROM test_table_source a;
Read parameters from a parameter definition file
If you have too many parameters in a function call in a script, you can specify them in a parameter definition file (*.json or *.yaml) and reference the file in the call. When executing, SQL Executor loads the parameters from the parameter definition file.
The parameter definition files must be stored in {SOURCE_ROOT}/param_definitions/ folder (see S3 Folder Structure).
Example: The SQL script file has a function call with the parameter definition file named ‘my_parameter_file_name.json’. Notice that the ‘param_definitions’ subfolder is not explicitly specified as a part of the path because it is automatically resolved at processing.
...some SQL code...
#{test_template(param_definition_file="my_parameter_file_name.json")}
...some other SQL code...
Customize the order of executing script files
To customize the order of executing script files, use a control file.
The control file is a CSV file with the following columns:
| Column name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| script_name | string | yes | n/a | Contains the name of the script that should be executed |
| predecessor_name | string | yes | n/a | Contains script predecessors (the scripts that must finish before your script can be executed) The script predecessors must be separated with a vertical bar ( | ). Example: |
| priority | integer | no | 0 | Contains the number that defines the priority of the row |
Example:
script_name,predecessor_name
1_get_lsts_delete.sql,
2_insert_data_1.sql,1_get_lsts_delete.sql
2_insert_data_2.sql,1_get_lsts_delete.sql
2_insert_data_3.sql,1_get_lsts_delete.sql
2_insert_data_4.sql,1_get_lsts_delete.sql
2_insert_data_5.sql,1_get_lsts_delete.sql
2_insert_data_6.sql,1_get_lsts_delete.sql
3_check_data.sql,2_insert_data_1.sql|2_insert_data_2.sql|2_insert_data_3.sql|2_insert_data_4.sql|2_insert_data_5.sql|2_insert_data_6.sql
4_perform_miracle.sql,3_check_data.sql
5_load_collection.psql,4_perform_miracle.sql
6_use_params.sql,5_load_collection.psql
7_iteration_test.isql,6_use_params.sql
8_drop_everything.psql,7_iteration_test.isql
The following picture shows the dependency graph generated by the control file:
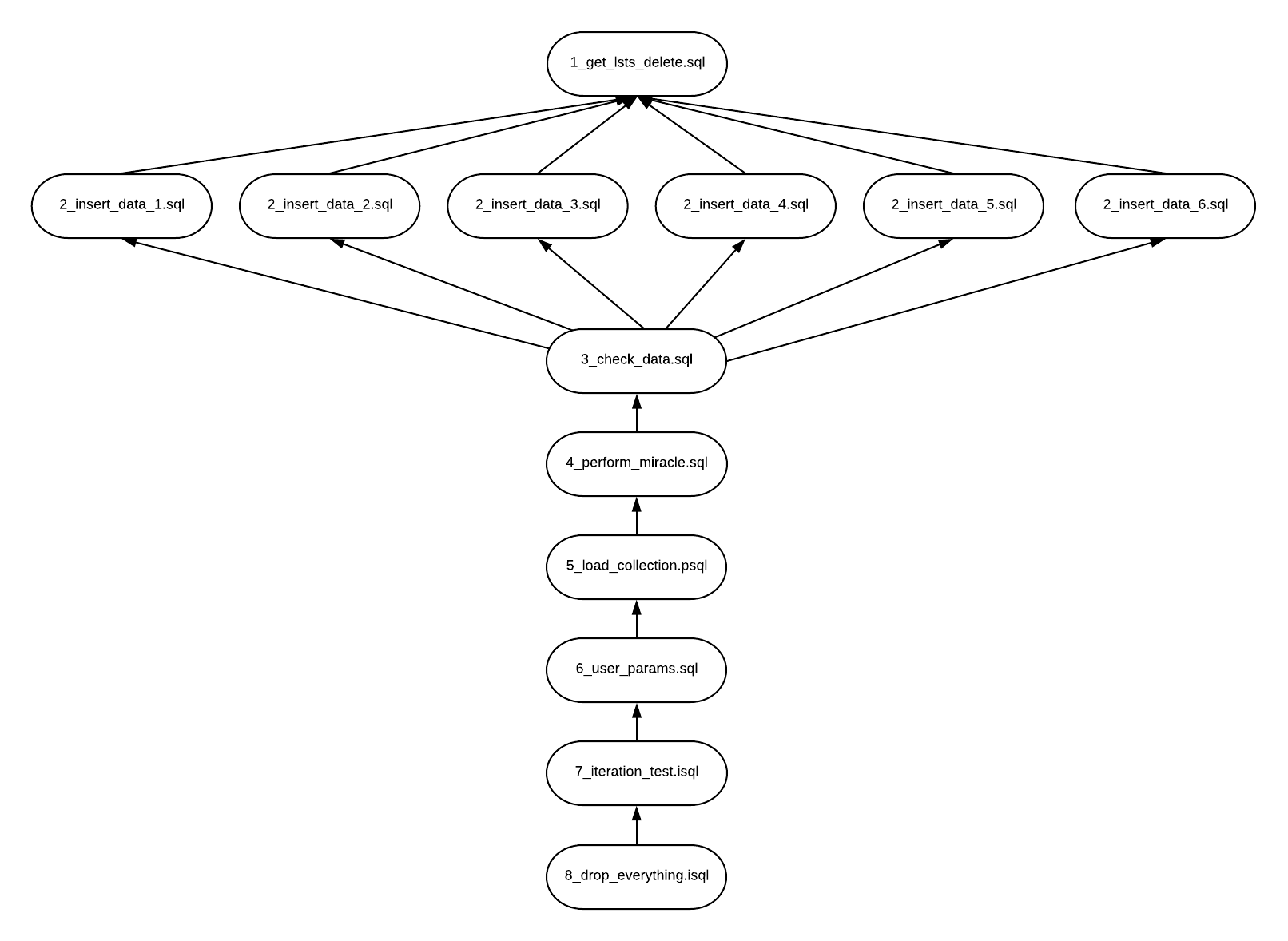
- The execution starts on the first (top) level, with
1_get_lsts_delete.sql. - After the first-level script finishes, all the scripts on the second level (
2_insert_data_x.sql) are executed in parallel using the standard parallel settings. - After the second-level scripts finish, all the other scripts are executed serially.