Google Analytics Downloader
Google Analytics Downloader is a component of the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). Google Analytics Downloader downloads data from a Google Analytics account via the Google API.
Configuration File
Creating and setting up the brick’s configuration file is the third phase of building your data pipeline. For more information, see Build Your Data Pipeline.
For more information about configuring a brick, see Configure a Brick.
Minimum Layout of the Configuration File
The following JSON sample is the minimum layout of the configuration file that Google Analytics Downloader can use. If you are using more bricks, you can reuse some sections of this configuration file for other bricks. For example, the ‘downloaders’ section can list more downloaders, and the ‘integrators’ and ‘ads_storage’ sections can be reused by other downloaders and executors (see Configure a Brick).
This sample describes the use case of one instance of Google Analytics Downloader that downloads two entities from a Google Analytics account.
Copy the sample and replace the placeholders with your values.
You can later enrich the sample with more parameters depending on your business and technical requirements (see Customize the Configuration File).
{
"entities": {
"ga_profile": {
"global": {
"custom": {
"type": "ga_profile",
"hub": ["id"]
}
}
},
"table_1_name": {
"global": {
"custom": {
"dimensions": "ga_dimension_1,ga_dimension_2,ga_dimension_3",
"metrics": "ga_metric_1,ga_metric_2,ga_metric_3",
"hub": ["column_1_name","column_2_name","column_3_name"]
}
}
},
"table_2_name": {
"global": {
"custom": {
"dimensions": "ga_dimension_4,ga_dimension_5,ga_dimension_6",
"metrics": "ga_metric_4,ga_metric_5,ga_metric_6",
"hub": ["column_1_name","column_2_name","column_3_name"]
}
}
}
},
"downloaders": {
"ga_downloader_id": {
"type": "ga",
"entities": ["ga_profile","table_1_name","table_2_name"]
}
},
"ga": {
"client_id": "google_client_id"
},
"integrators": {
"ads_integrator_1": {
"type": "ads_storage",
"entities": ["ga_profile","table_1_name","table_2_name"]
}
},
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {}
}
}
The placeholders to replace with your values:
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| entities -> ga_profile -> global -> custom -> hub | array | yes | n/a | The table columns to generate a primary key for the 'ga_profile' section Unless your data does not contain the ID, keep this as is: |
| entities -> table_x_name | string | yes | n/a | The database tables where Google Analytics Downloader downloads the data to |
| entities -> table_x_name -> global -> custom -> dimensions | string | yes | n/a | The dimensions for the entity. For available dimensions, see https://developers.google.com/analytics/devguides/reporting/core/dimsmets. Example: ga:date,ga:hostname,ga:pagePath,ga:pageTitle |
| entities -> table_x_name -> global -> custom -> metrics | string | yes | n/a | The metrics for the entity. For available metrics, see https://developers.google.com/analytics/devguides/reporting/core/dimsmets. Example: ga:bounces,ga:pageviews,ga:entrances |
| entities -> table_x_name -> global -> custom -> hub | array | yes | n/a | The table columns to generate a primary key Example: NOTE: The 'segment' and 'filters' columns may be null. If you are using either or both columns in the 'hub' parameter, it may contain null values, too. To replace null values in the 'hub' parameter with the '(empty)' string, you can set the 'substitute_empty_values' parameter to 'true' (see Add optional parameters). |
| downloaders -> ga_downloader_id | string | yes | n/a | The ID of the Google Analytics Downloader instance Example: ga_downloader_1 |
| downloaders -> ga_downloader_id -> entities | array | yes | n/a | The database tables into which Google Analytics Downloader downloads the data Must be the same as the database table names in 'entities -> table_x_name' |
| ga -> client_id | string | yes | n/a | Your Google client ID Example: 9414861317621.apps.googleusercontent.com |
| integrators -> ads_integrator_id | string | yes | n/a | The ID of the ADS Integrator instance Example: ads_integrator_1 |
| integrators -> ads_integrator_id -> entities | array | yes | n/a | The names of the entities that this ADS Integrator instance processes Must be the same as the database table names in 'entities -> table_x_name' |
| ads_storage -> instance_id | string | yes | n/a | The ID of the Agile Data Warehousing Service (ADS) instance into which the data is uploaded |
ads_storage -> username | string | yes | n/a | The access username to the Agile Data Warehousing Service (ADS) instance into which the data is uploaded |
Customize the Configuration File
You can change default values of the parameters and set up additional parameters.
Specify load mode per entity
You can set load mode for a specific entity (a different value than the ‘full’ parameter in the ‘ga’ section sets, see Add optional parameters).
"table_1_name": {
"global": {
"custom": {
"dimensions": "ga_dimension_1,ga_dimension_2,ga_dimension_3",
"metrics": "ga_metric_1,ga_metric_2,ga_metric_3",
"hub": ["column_1_name","column_2_name","column_3_name"],
"full": true|false // optional
}
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| full | Boolean | no | false | Specifies load mode for a specific entity
|
Add multiple instances of Google Analytics Downloader
When you use only one instance of Google Analytics Downloader, it reads its remote location parameters from the ‘ga’ section.
If you use multiple instances of Google Analytics Downloader and each instance has a separate location to download data from, add several ‘ga’ sections and give each section a unique name (for example, ‘ga_users’ or ‘ga_sales’).
"ga_users": {
"client_id": "google_client_1_id"
},
"ga_sales": {
"client_id": "google_client_2_id"
}
For each instance of Google Analytics Downloader in the ‘downloaders’ section, add the ‘settings’ parameter and set it to the name of the section that contains settings for this Google Analytics Downloader instance.
"downloaders": {
"ga_downloader_1_id": {
"type": "ga",
"settings": "ga_users",
"entities": ["ga_profile","table_1_name","table_2_name"]
},
"ga_downloader_2_id": {
"type": "ga",
"settings": "ga_sales",
"entities": ["ga_profile","table_1_name","table_2_name"]
}
}
Add optional parameters
Depending on your business and technical requirements, you can set one or more optional parameters affecting the data load process.
"ga": {
"client_id": "google_client_id",
"full": true|false, // optional
"rolling_days": number_of_days, // optional
"substitute_empty_values": true|false, // optional
"number_of_threads": number_of_threads, // optional
"use_resource_quotas": true|false // optional
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| full | Boolean | no | false | Specifies load mode used for loading data to the database
|
| rolling_days | integer | no | 14 | The number of days back from the last run that the data should be downloaded from |
| substitute_empty_values | Boolean | no | false | Specifies how to handle null values in the 'hub' parameter that may be caused by empty values in 'segment' and 'filters' columns (see the 'entities -> table_x_name -> global -> custom -> hub' parameter in Minimum Layout of the Configuration File)
|
| number_of_threads | integer | no | 1 | The number of parallel threads |
| use_resource_quotas | Boolean | no | false | (Only for Google Analytics 360 users) Specifies whether to prevent data sampling using resource based quotas (see https://developers.google.com/analytics/devguides/reporting/core/v4/resource-based-quota)
|
Customize integrators
The ‘integrators’ and ‘ads_storage’ sections define the behavior of integrators.
"integrators": {
"ads_integrator_1": {
"type": "ads_storage",
"entities": ["ga_profile","table_1_name","table_2_name"]
}
},
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {}
}
If you want to add more parameters or change the defaults, see ADS Integrator.
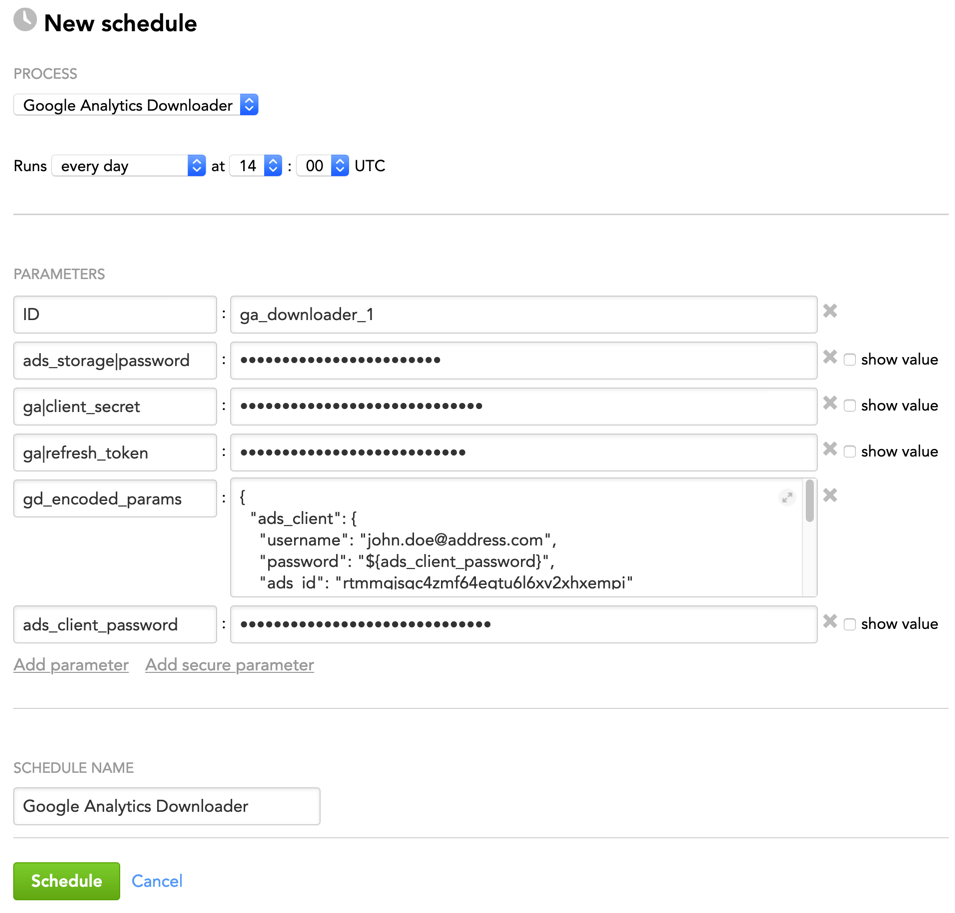
Schedule Parameters
When scheduling Google Analytics Downloader (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
Some parameters contain the names of the nesting parameters, which specifies where they belong in the configuration hierarchy. For example, a parameter entered as ga|options|password is resolved as the following:
"ga": {
"options": {
"password": ""
}
}
Enter such parameters as is (see Schedule Example).
| Name | Typ | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| ID | string | yes | no | n/a | The ID of the Google Analytics Downloader instance being scheduled Must be the same as the value of the 'downloaders -> ga_downloader_id' parameter in the configuration file (see Minimum Layout of the Configuration File) Example: ga_downloader_1 |
| ads_storage|password | string | yes | yes | n/a | The password to access the ADS instance to upload the data to |
| ga|client_secret | string | yes | yes | n/a | The Google client secret |
| ga|refresh_token | string | yes | yes | n/a | The OAuth refresh token For information about using OAuth 2.0, see https://developers.google.com/identity/protocols/oauth2. |
| gd_encoded_params | JSON | see 'Description' column | no | n/a | The parameters coding the queries for Google Analytics Downloader (see Queries) |
Queries
Queries represent an additional configuration for the entities that allows you to specify what profiles should be downloaded for each entity. In addition, you can configure the initial date (for full load mode or for the first run in incremental load mode) as well as a segment and filters that are propagated to an API call.
In subsequent runs, the start date is calculated as the date of the last run minus either the number of rolling days (if specified; see the ‘rolling_days’ parameter in Add optional parameters) or 14. The end date is always the current date.
Query Structure
You can specify the queries as a CSV file or a database table with the following columns:
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| entity | string | yes | n/a | The name of the entity NOTE: This parameter is case-sensitive. |
| profile_id | string | yes | n/a | The Google Analytics profile ID including the 'ga:' prefix Example: ga:123456789 |
| segment | string | yes | n/a | The Google Analytics segment. For more information about segments, see https://developers.google.com/analytics/devguides/reporting/core/v3/reference#segment. |
| filters | string | yes | n/a | The Google Analytics filters. For more information about filters, see https://developers.google.com/analytics/devguides/reporting/core/v3/reference#filters. |
| initial_load_start_date | string | yes | n/a | The start date for the first run or for a data load in full load mode Format: YYYY-MM-DD |
Here is an example of the query file:
'entity','profile_id','segment','filters','initial_load_start_date'
'user','ga:101029490',,,'2016-01-01'
'user_type','ga:101029490',,,'2016-01-01'
'site_traffic','ga:101029490',,,'2016-01-01'
'page_traffic','ga:101029490',,,'2016-01-01'
'user','ga:118107442',,,'2016-01-01'
'user_type','ga:118107442',,,'2016-01-01'
'site_traffic','ga:118107442',,'ga:browser=~^Firefox','2016-01-01'
'page_traffic','ga:118107442',,,'2016-01-01'
Query Source
Google Analytics Downloader can read the queries from any supported input data source (see Types of Input Data Sources).
- If you want to store the queries in an object storage service, specify the queries in a CSV file.
- If you want to store the queries in a data warehouse, specify the queries as a query to this data warehouse.
When building a JSON structure for the queries as Types of Input Data Sources specifies, replace the ‘input_source’ parameter with the ‘queries_input_source’ parameter.
Example: The queries stored on the staging area
{
"queries_input_source": {
"type": "staging",
"path": "ga_queries.csv"
}
}
Example: The queries obtained from ADS
{
"ads_client": {
"username": "john.doe@address.com",
"password": "secret",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"queries_input_source": {
"type": "ads",
"query": "SELECT entity, profile_id, segment, filters, initial_load_start_date FROM ga_queries;"
}
}
Queries as Schedule Parameters
When providing the queries as schedule parameters, you have to code them using the ‘gd_encoded_params’ parameter (see Schedule Parameters).
To code the queries, follow the instructions in Specifying Complex Parameters. Once done, you should have one or more parameters depending on whether you have sensitive information (such as passwords, secret key, and so on) to enter:
- If you do not have sensitive information, you should have only the ‘gd_encoded_params’ parameter coding the queries.
- If you have sensitive information, you should have the ‘gd_encoded_params’ parameter coding the queries and reference parameters encoding sensitive information that you will be adding as secure parameters.
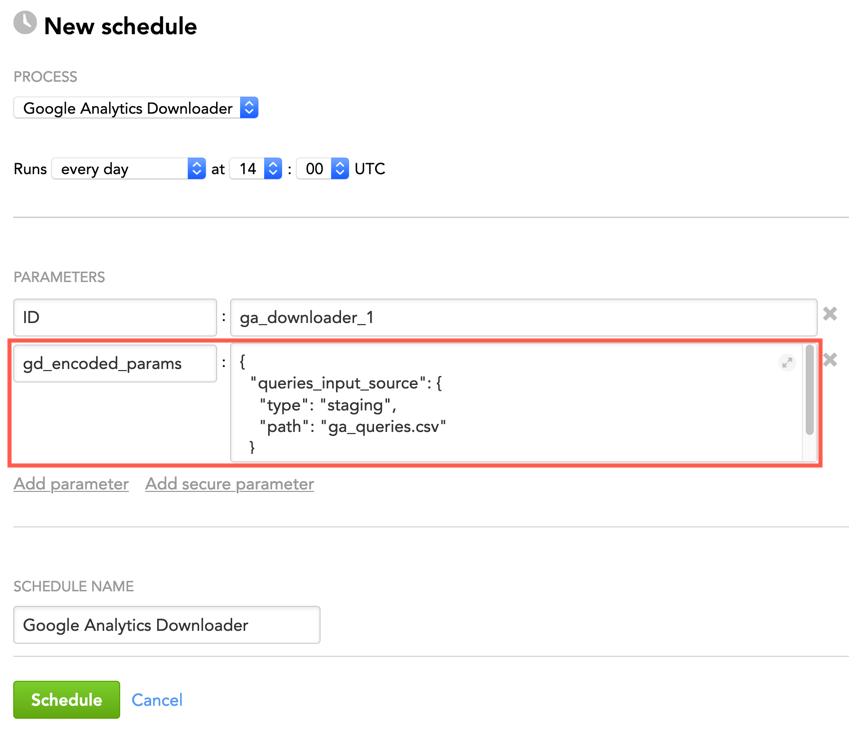
Example: The queries on the staging area (no sensitive information) to be coded by the ‘gd_encoded_params’ parameter
{
"queries_input_source": {
"type": "staging",
"path": "ga_queries.csv"
}
}
Example: The queries obtained from ADS (sensitive information present: ADS password) to be coded by the ‘gd_encoded_params’ and a reference parameter encoding the ADS password
The following will become the value of the ‘gd_encoded_params’ parameter:
{
"ads_client": {
"username": "john.doe@address.com",
"password": "${ads_client_password}",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"queries_input_source": {
"type": "ads",
"query": "SELECT entity, profile_id, segment, filters, initial_load_start_date FROM ga_queries;"
}
}
In addition, you have to add the reference parameter ‘ads_client_password’ as a secure parameter.
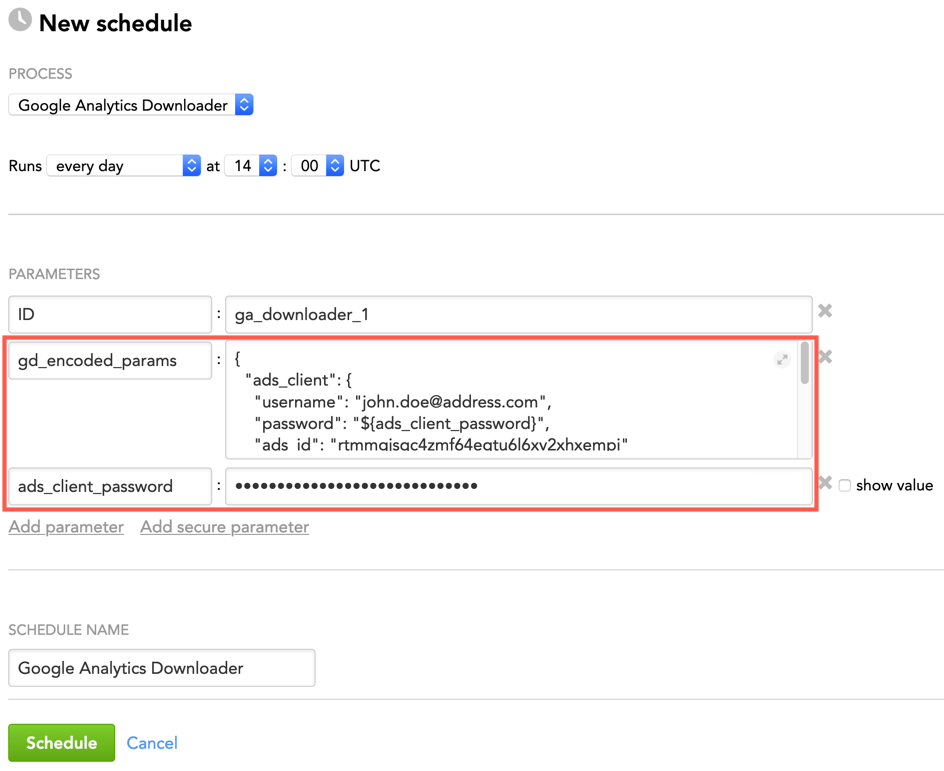
Schedule Example
The following is an example of how you can specify schedule parameters: