Use Automated Data Distribution
To start using Automated Data Distribution (ADD), do the following:
Ensure that each dataset in a workspace has the corresponding database object in the output stage, and this object serves as a source of data for the ADD process. To do so, we recommend that you use the SQL diff.
- You do not have to deploy the ADD process to the workspace first. The ADD process is automatically created after you configure the output stage parameters. The process is created under the name of ‘Automated Data Distribution’.
Configure the Output Stage Parameters
The output stage contains objects serving as a data source for populating data into workspaces.
In GoodData, terms workspace and project denote the same entity. For example, project ID is exactly the same as workspace ID. See Find the Workspace ID.
To configure the output stage, use the following gray page:
https://secure.gooddata.com/gdc/dataload/projects/{workspace_id}/outputStage
Configure the following parameters for the output stage:
- Output Stage
- (Optional) Client ID
- (Optional) Output Stage Prefix
To configure the parameters for a workspace, you have to have access to Data Warehouse. The access is checked at the time of configuring the parameters and retrieving data from Data Warehouse.
Output Stage
The Output Stage parameter is a URI pointing to the schema in the Data Warehouse instance that represents the output stage.
Although each Data Warehouse currently has one default schema that is equal to the instance itself (see Single Schema per Data Warehouse Instance), provide the URI of the schema and not the instance.
If Data Warehouse URI is the following:
/gdc/datawarehouse/instances/{data_warehouse_instance_id}
then the default schema URI would be the following:
/gdc/datawarehouse/instances/{data_warehouse_instance_id}/schemas/default
Client ID
The Client ID parameter identifies data records related to a particular workspace. This is an optional parameter.
Each workspace can have only one Client ID specified.
The Client ID parameter can be up to 255 characters long and can contain only the following characters:
- Numbers
- Lowercase and uppercase ASCII letters (a-z, A-Z)
- Underscore (_)
The Client ID parameter must be unique within a data product.
For Life Cycle Management (LCM) setup (see Managing Workspaces via Life Cycle Management), LCM acts as an authority, and the Client ID parameter is defined within the LCM hierarchy. The Client ID parameter within workspace OS is ignored. If this behavior is unwanted, contact GoodData Support.
We recommend that you use the same Data Warehouse instance as an output stage for a group of workspaces in the same domain. The Client ID parameter is used to determine which data records are related to which workspace. The value of the Client ID parameter is specified in the x__client_id column. When data is loaded to a particular workspace, only data with the corresponding value of the x__client_id column is loaded to this workspace.
- If the x__client_id column is not present in the output stage table, no filtering is done and all data is loaded to the corresponding dataset.
- If the x__client_id column is present in the output stage table and no Client ID is specified, ADD fails when the data is being loaded to the corresponding dataset.
Example:
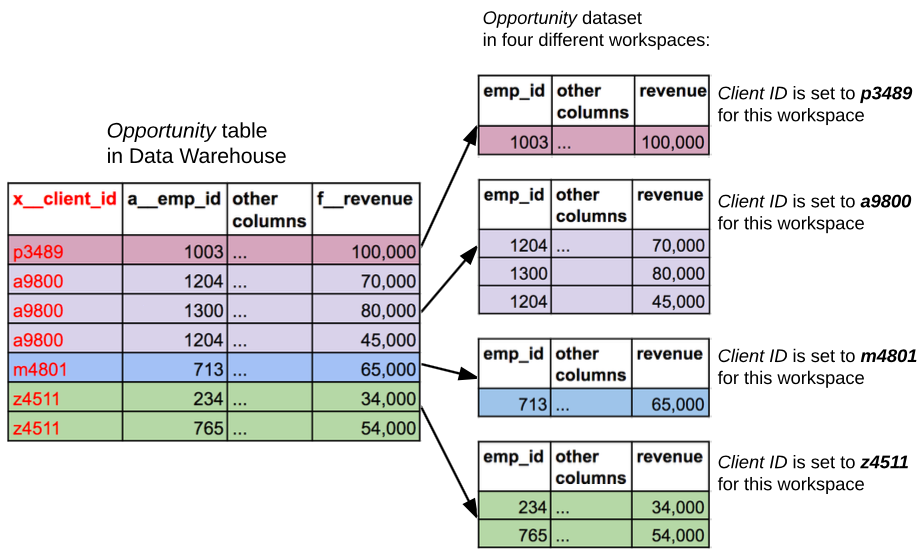
The following picture shows a situation where there are records in the output stage table holding information related to a few workspaces in a segment or even a domain. When the data is loaded to a workspace where a certain value of Client ID is set, only the records whose value in the x__client_id column matches the workspace’s Client ID parameter are loaded into the workspace.
Output Stage Prefix
The Output Stage Prefix parameter is a prefix that identifies all output stage objects and distinguishes them from the objects in other logical areas (input stage, persistent stage) of Data Warehouse. This is an optional parameter.
Typically, each logical area of Data Warehouse has its own schema in a common database instance. The current version of Data Warehouse does not support the schema concept. To overcome this limitation, we recommend that you use prefixes in the names of all objects in Data Warehouse logical areas.
You can choose any prefix according to your site’s naming convention and requirements. This prefix is removed from the output stage objects when the output stage objects and LDM are being matched.
Example:
Imagine a business entity (for example, Opportunity) that has its database objects in all three logical areas of Data Warehouse. With no schema support, you have to use prefixes for distinguishing these objects. For the Opportunity business object, you can use In_Opportunity, P_Opportunity and Out_Opportunity tables in the input stage, persistent stage, and the output stage correspondingly.
Example:
Let’s say you have a dataset called Opportunity (with dataset.opportunity as its LDM identifier) in the logical data model in your workspace. The corresponding output stage object would be opportunity.
However, if you are using prefixes for distinguishing database objects in different logical areas of Data Warehouse, you can use out_opportunity instead.
In this case, the Output Stage Prefix parameter is set to out_ . This prefix will be removed from the object name when matching dataset.opportunity and out_opportunity.
Use the SQL Diff
The API resource for SQL diff generates SQL commands for creating corresponding output stage objects. If such output stage objects already exist but have to be modified, SQL diff generates appropriate commands.
Each database object has to have its name and column names in accordance with the output stage objects naming convention (see Naming Convention for Output Stage Objects). The generated SQL is compliant with the output stage object naming convention.
In the database client that you are using, execute the generated commands on top of your Data Warehouse instance mapped as an output stage.
To check that the commands completed successfully, re-run the SQL commands. The returned results should indicate that the workspace LDM and the output stage objects match.
This may also help: