Data Preparation and Distribution Pipeline
The GoodData data preparation and distribution pipeline covers extracting data from data sources (such as Google Analytics, Salesforce, S3 and so on), transforming the data according to predefined rules, and distributing it to your workspaces.
Watch the GoodData webinar “Setting Up a Data Integration Pipeline for Repeatable Analytics Delivery” that demonstrates the end-to-end process of setting up the data load pipeline.
Data preparation and distribution pipeline components
The GoodData data preparation and distribution pipeline consists of the following components:
- Service workspace
- Data Integration Console
- Bricks
- Agile Data Warehousing Service
- Big Data Storage
- Automated Data Distribution
- Client workspaces
All data preparation and distribution pipeline components are an integral part of the GoodData platform, are hosted and run at GoodData’s side.
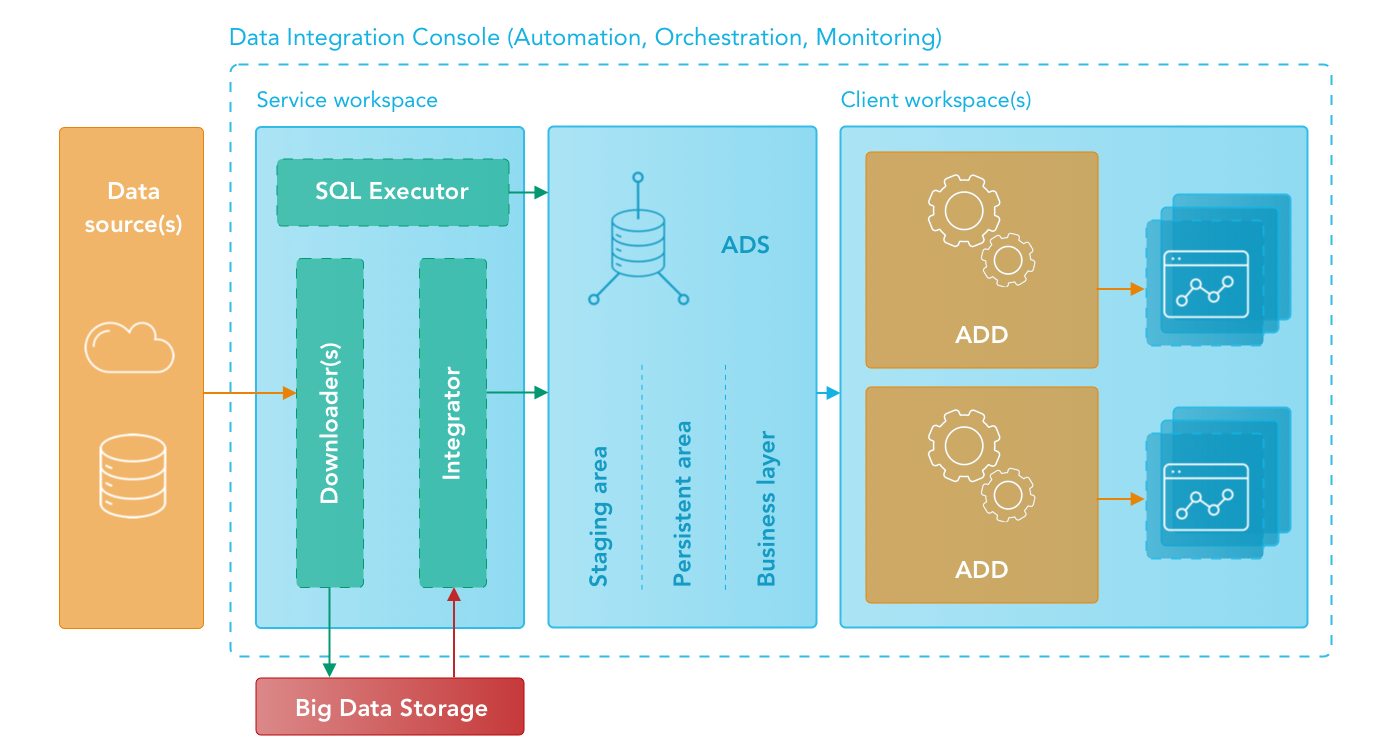
Service workspace
The service workspace is a workspace where you prepare data for all client workspaces. To prepare your data, you deploy bricks such as downloaders, integrators and executors.
If you need only one workspace, you do not need to have the service workspace. Having one client workspace is enough.
Data Integration Console
Data Integration Console (DISC) allows you to automate, orchestrate, and monitor your GoodData Integration. All data preparation and distribution pipeline components are consolidated into a workflow that consists of logically interconnected components. For more information, see Data Integration Console Reference.
Bricks
A GoodData brick is a component that performs a specific task based on the brick’s type.
- Downloaders download data from source systems and uploads it to Big Data Storage.
- CSV Downloader downloads CSV and Excel files from various sources.
- SQL Downloader downloads data from a database endpoint.
- Google Analytics Downloader downloads data from the Google API.
- Google Sheets Downloader downloads data from Google Sheets.
- Salesforce Downloader downloads data from the Salesforce API.
- Integrators transfer the downloaded data from BDS to ADS.
- ADS Integrator transfers the downloaded data to ADS (see Data Warehouse Reference).
- Executors transform the data within ADS or help automate ADD processes.
- SQL Executor runs SQL commands to transform the data stored in ADS.
- Utilities provide additional features that you can use to support your data pipeline.
- Schedule Executor runs schedules for Automated Data Distribution (ADD) data loading processes in one or more client workspaces.
- Object Renaming Utility batch-renames and/or hides metadata objects in one or more workspaces.
- Custom Field Creator creates additional fields (facts, attributes, or dates) in the logical data model in one or more workspaces.
- Date Dimension Loader loads date dimension data to date datasets in one or more workspaces.
For more information about the bricks, see Brick Reference.
Agile Data Warehousing Service
Agile Data Warehousing Service, or ADS (also known as “Data Warehouse”), is a fully managed, columnar data warehousing service for the GoodData platform. For more information about ADS functions and configurations, see Data Warehouse Reference.
You can use SQL Executor along with ADS to orchestrate the flow of SQL transformations to pre-aggregate, de-normalize, or process time-series data, build snapshots, consolidate multiple data sources, and so on.
Big Data Storage
Big Data Storage (BDS) is a part of the staging area sitting between the data sources and ADS. BDS uses the Amazon S3 object storage and acts as permanent storage for data extracts.
Automated Data Distribution
Automated Data Distribution (ADD) is a GoodData component that enables you to quickly upload data from ADS and distribute it to one or multiple workspaces. For more information about ADD, see Automated Data Distribution Reference.
You can use Schedule Executor to automatically run schedules for ADD data loading processes.
Client workspaces
A client workspace (also known as “project”) is a set of interrelated datasets and metrics, reports, and dashboards built on top of those data sets. You can have one or multiple workspaces.
How the data preparation and distribution pipeline components interact
The following high-level process outlines how the data preparation and distribution pipeline works and how its components interact:
A downloader (CSV Downloader, SQL Downloader, Google Analytics Downloader, Google Sheets Downloader, Salesforce Downloader) accesses the remote location where your source data is stored and downloads the data to BDS.
An integrator (ADS Integrator) fetches the downloaded data from BDS and uploads it to ADS.
An executor (SQL Executor) accesses the data in ADS and transforms it according to the predefined SQL scripts.
SQL Executor is optional. If you do not need to transform your data before distributing it to client workspaces, you do not have to use SQL Executor.Automated Data Distribution (ADD) distributes prepared data from ADS to client workspaces.
You can use Schedule Executor to automatically run scheduled ADD data loading processes based on the predefined criteria.Client workspaces are ready for end users to start building reports.