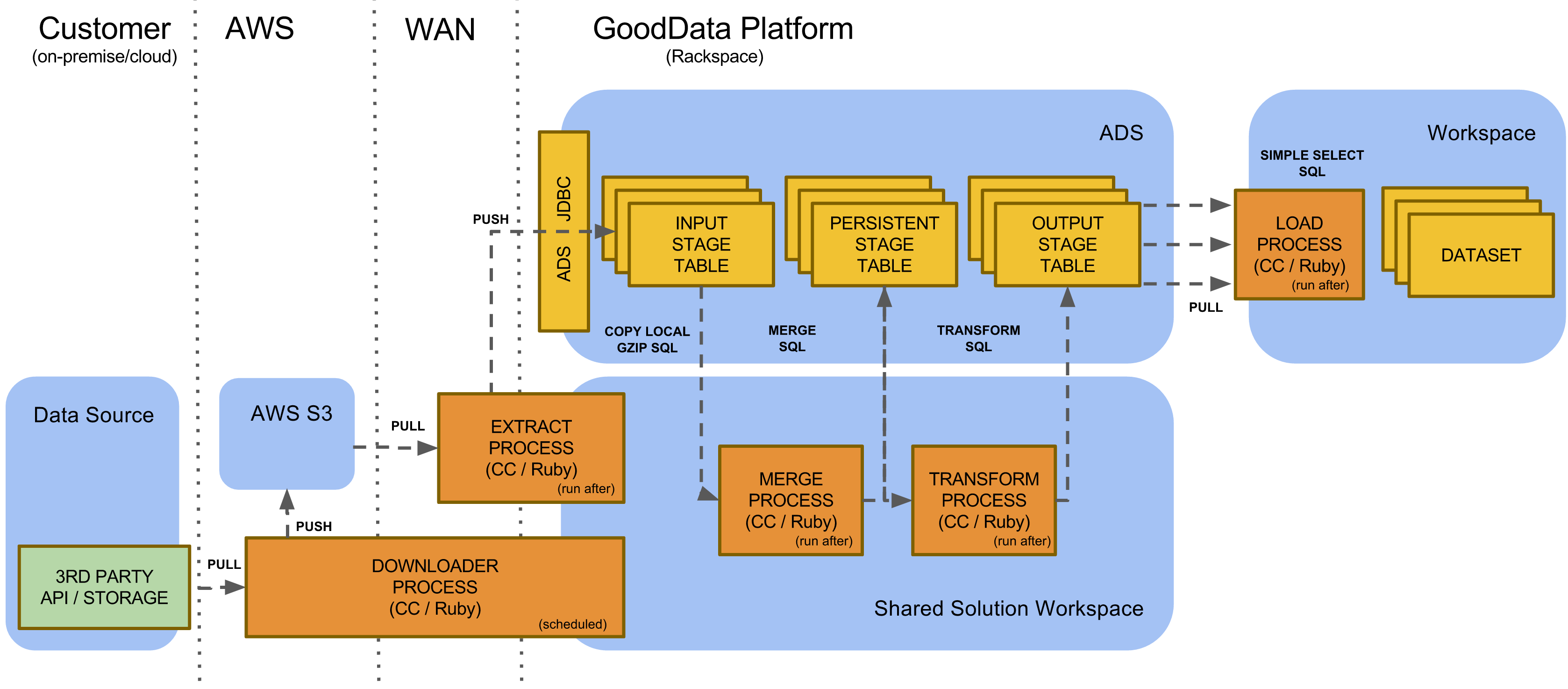
ELT Blueprint
ELT Blueprint is currently the most comprehensive GoodData data pipeline blueprint. It leverages a custom extraction process (Ruby) for incremental data extraction, data staging and transformation in ADS, and the custom workspace loading process.
Data Flows
The figure below describes the ELT blueprint data flows that consist of following phases:
- Download - data is downloaded from a third-party API or data storage to solution private Amazon S3 bucket.
- Extract - data increment is extracted from the S3 bucket to ADS input stage tables.
- Merge - the data increment is merged to the persistent tables.
- Transform - persistent data is transformed into the output stage tables.
- Load - data is loaded into one or more workspaces.
All the phases above should be executed as independent platform processes.
Ideally, each phase is executed under different platform account (username/password). This allows customization of resource limits for different types of processing (for example, ADS resource pools).
We’ll describe the different phases of the ELT blueprint in following paragraphs.
General Limits & Concurrency
The Platform Limits document describes general platform limits that apply to all processes executed in all phases of the data flow.
Accessing this document requires a login to view this page. If you do not have access, you can register via sign-in on the GoodData Support portal.
Download
The GoodData platform process transfers data from customer premises to a solution-private AWS S3 bucket (access credentials of this S3 bucket are not shared with the customer). The S3 bucket serves as the ultimate data backup (99.999999999% durability).
Download Guidelines
Incremental data download is strongly recommended. Use the full data download only in cases when the data source doesn’t support any form of incremental extraction (for example, creation timestamp based mechanism). Some data increment overlap is strongly recommended. Duplicate data records are resolved later in the Extract and Merge phases.
Granularity of the data downloads is very important. Different business data entities should be downloaded by separate downloaders (separate executions for each business entity swim-lane). Multi-tenant solutions (PbG or EDM) must download single entity data for all tenants during single downloader execution.
Downloaders are deployed in the solution workspace for single-tenant (for example, enterprise) solutions. For multi-tenant solutions, the downloader is deployed in a separate shared workspace that does not contain any of the tenant’s analytical objects (for example, dashboards, reports).
D ownloader executions should be orchestrated with the subsequent processing using run-after scheduling.
Use solution specific AWS S3 credentials for different solutions. Make sure that the solution-specific credentials are restricted to the solution specific bucket or URI.
Use the Amazon S3 server-side encryption store all data on the S3 bucket.
Limits & Concurrency
All General Limits apply. Additional bandwidth limits apply:
Limit | Value | Description |
|---|---|---|
| S3 upload throughput | < 70 GB/hr | The largest object that can be uploaded in a single PUT is 5 GB. |
| WebDAV upload throughput | < 50 GB/hour | Maximum WebDAV input data bandwidth |
| WebDAV requests | < 300/min |
General SQL Guidelines
As all subsequent ELT blueprint phases involve SQL driven processing, we’ll first mention general guidelines for ADS SQL statements. This paragraph contains general ADS SQL statement guidelines that are applicable across all ELT blueprint phases. For more details on ADS performance, see Performance Tips.
Avoid persistent record DELETEs and UPDATEs
Ideally local temporary tables are used for the data that must be cleaned up after a session wraps up to avoid explicit data deletion. Sometimes however, data tables must be persistent for various reasons (e.g. parallel data loading). You can use persistent tables in these situations. Always use TRANCATE TABLE instead of DELETE when you need to remove all data from these persistent tables.
In many cases you’ll only need to remove or update certain records (e.g. all records with specific business dates) from persistent tables. Use the DELETE or UPDATE with a WHERE clause as the last option. Consider the following options first:
Partition the table by the key that you are using for record deletion (e.g. business date) and use DROP_PARTITIONS instead of DELETE for removing a table’s records.
Do not use partitioning in cases when there are more than 100 partitions on a single table.Use append only processing when each record change is INSERTed into the persistent table (instead of DELETEd or UPDATEd). Latest and greatest records can be then identified while reading the table (SELECT) using an exernal function (for example, ROW_NUMBER).
- Use the ROW_NUMBER rather than FIRST_VALUE or LAST_VALUE analytical functions for better performance.
Analyze Statistics
Every significant data modification (INSERT/UPDATE/DELETE) should be followed with the ANALYZE_STATISTICS SQL statement.
SELECT ANALYZE_STATISTICS( 'stg_splunk_processes_merge' );
Do not use Views
Do not use views for complex SQL statement simplification. Unfortunately, Vertica query optimization does not work well with views.
Avoid RESEGMENT and BROADCAST in EXPLAIN
Define ADS table and projection segmentation in a way that no SQL statement EXPLAIN contains RESEGMENT and BROADCAST operations.
Use MERGEJOINS with GROUP BY PIPELINED
Try to avoid HASH JOINS and CROSS JOINS using proper table and projection ordering clauses. The same applies to GROUP BY operations. Tweak the ordering for Vertica to use GROUP BY PIPELINED operations.
Avoid Unnecessary SORTing
Define default table sorting to avoid unnecessary SORT operations in the EXPLAIN query.The COPY LOCAL supportsThe COPY LOCAL supports
Use DIRECT Hints for all DML Operations
All data manipulation SQL statements that affect more than 1,000 records must use the /*+DIRECT*/ hint. On the other hand, do not use the /*+DIRECT*/ hint with SQL statements that touch less than 1,000 records.
Use as Few Projections as Possible
Use as few projections as possible to minimize data insertion, update and deletion overhead.
Refrain from Ad Hoc Table Creation
Refrain from using ad-hoc persistent tables in ADS. Whenever you use an ad-hoc table, use CREATE LOCAL TEMPORARY TABLE … ON COMMIT PERSIST SQL statement. Any cross-session persistent tables must be pre-created before their first use (CREATE TABLE IF NOT EXISTS) and TRUNCATEd instead of DELETEd.
Optimize the column storage
ADS supports different column level encodings options. The optimal encoding depends on the column data type and cardinality (number of unique values). Consult this article for different encoding options, or contact GoodData Support.
Extract and Merge
The data extraction stages the most recent data increment from the solution-private S3 bucket to the ADS input stage tables. The merge process then merges the data increment from the staging tables to the persistent tables. The merge process reconciles potential data overlaps and duplicities that can be added during the previous phases. Both extract and merge continue processing data in separate business entity swim-lanes.
Extract & Merge Guidelines
The reference implementation uses the business date stored in ADS audit tables to identify the data increment (on the S3) that needs to be staged in ADS. A similar business date driven mechanism is recommended for your extract process implementation.
Input Stage Table Structure
The input stage tables should have proper segmentation and ordering so the data pipeline SQL statements comply with the General SQL Guidelines above. Usually the input stage tables that hold facts should only contain the default projection segmented and ordered by the table’s primary key for tables that contain (later) fact table data. Small (up to single digit million records) dimension tables should be created as UNSEGMENTED ALL NODES ordered by its primary key.
Input Stage Tables DDL:
-- fact input stage table
CREATE TABLE src_stg_fact(fact_id AS expr, .... , col_n AS expr)
fact_id INT ,
col_1 VARCHAR (32),
...
col_n VARCHAR (64)
)
ORDER BY fact_id
SEGMENTED BY HASH(fact_id) ALL NODES;
-- small dimension input stage table
CREATE TABLE src_stg_dim(dim_id AS expr, .... , col_n AS expr)
dim_id INT ,
col_1 VARCHAR (32),
...
col_n VARCHAR (64)
)
ORDER BY dim_id
UNSEGMENTED ALL NODES;
Persistent Stage Table Structure
The persistent stage tables should be optimized for the transformation SQL queries performance (see General SQL Guidelines). By default the input stage table’s projections should be segmented and ordered by the table’s primary key. The default mode for small dimension tables is UNSEGMENTED ALL NODES. Additional projections with different segmentation and ordering might be handy for optimal transformation execution. These projections are specific for each solution. Please make sure that you are not using more projections than necessary (at most ~ three projections per ADS table).
COPY LOCAL for Input Stage Tables Population
ADS input stage tables are populated via COPY LOCAL SQL statements that are issued over the ADS JDBC driver (see Download the JDBC Driver). Never use individual INSERT statements for the input stage table population.
We recommend compressed CSV format for the input files. Data files larger than 50 GB (compressed or uncompressed) should be broken down to 50 GB chunks.
The COPY LOCAL supports copying multiple data files of the same structure. We recommend combining multiple data files into a single COPY LOCAL statement rather than issuing separate COPY LOCAL for each file. In other words, use as few COPY LOCALs as possible. Also in case of multi tenant solutions (e.g. PbG or EDP) combine the multiple tenant’s data into single COPY LOCAL statement.
COPY LOCAL syntax:
COPY src_stg_tbl(col_1 AS expr, .... , col_n AS expr)
FROM LOCAL ‘filename’ GZIP
DELIMITER ','
ESCAPE AS '"'
NULL ''
SKIP 1
EXCEPTIONS ‘exceptions-file’
REJECTED DATA ‘rejected_data_file’
ABORT ON ERROR
DIRECT;
Here are the recommended COPY LOCAL options:
No WITH PARSER option
- Use the GdcCsvParser in following situations:
- You need specific ESCAPE / ENCLOSED BY option.
- Your texts contain end-of-lines.
GZIP compression for saving network bandwidth
DIRECT to write directly to the Vertica ROS Container
NULL for specifying NULL representation in the CSV file
SKIP for skipping CSV header (if any)
ABORT ON ERROR to abort processing in case of bad data formatting
- If some errors are acceptable use EXCEPTIONS and REJECTED DATA options to specify where the errors and failing records are stored.
Intra-record Transformations
Any intra-record transformations (e.g. columns computed from other record’s columns) should be performed in the COPY LOCAL SQL statement itself. Here is an example:
COPY LOCAL transformations:
COPY src_stg_tbl(id, name , closed_date AS COALESCE (( "closed_date" at timezone 'UTC' ):: VARCHAR (255), '' ))
FROM LOCAL 'opportunity.csv.gz' GZIP
DELIMITER ','
ESCAPE AS '"'
NULL ''
SKIP 1
ABORT ON ERROR
DIRECT;
Merging Data to Persistent Tables
Merging data to persistent staging tables should avoid any data manipulation SQL statements except INSERT (FROM SELECT) and MERGE (no DELETE or UPDATE statements) because of exclusive locking. The best option is the INSERT … SELECT SQL statement:
INSERT … SELECT EXAMPLE:
INSERT /*+DIRECT*/ INTO stg_splunk_processes ( "request_id" , "transformation_id" , "executable" , "sys_valid_from" )
SELECT "request_id" , "transformation_id" , "executable" , "sys_valid_from" FROM src_splunk_processes;
-- then read the latest and greatest values from the stg_splunk_processes table
SELECT a.request_id, a. "transformation_id" , a. "executable"
FROM ( SELECT ROW_NUMBER() OVER (PARTITION BY request_id ORDER BY "sys_valid_from" DESC ) AS rownum,
request_id, "transformation_id" , "executable" FROM stg_splunk_processes) a
WHERE a.rownum = 1;
MERGE SQL statement with UPDATE is OK in case when the identification of the latest and greatest record versions during the persistent tables reading is too expensive. Here is example MERGE SQL statement usage:
MERGE example:
MERGE /*+DIRECT*/ INTO stg_splunk_processes_merge o
USING src_splunk_processes temp
ON ( o.request_id = temp .request_id )
WHEN MATCHED THEN UPDATE SET
"request_id" = temp . "request_id" ,
"transformation_id" = temp . "transformation_id" ,
"executable" = temp . "executable"
WHEN NOT MATCHED THEN INSERT (
"request_id" , "transformation_id" , "executable"
) VALUES (
temp . "request_id" ,
temp . "transformation_id" ,
temp . "executable"
);
Optimized MERGE is strongly recommended when merging data to the persistent tables. Here are the conditions that must be satisfied for the optimized MERGE execution
- The target table’s join column has a unique or primary key constraint.
UPDATEandINSERTclauses include every column in the target table.UPDATEandINSERTclause column attributes are identical.- The target table projections contain the MERGE statement keys (the keys used in the ON clause) in their ORDER BY clauses (the keys can be at the end of the ORDER BY - the position does not matter). MERGE can get completely stuck and timeout after a long time, abruptly, if a target projection misses MERGE key(s) in ORDER BY.
Limits & Concurrency
All General Limits apply. It is important to realize that ADS is staging storage for transformation purposes not a persistent data warehouse. This is why the ADS doesn’t feature full disaster recovery. It is assumed that ADS can be reloaded in full from the Amazon S3 bucket described above. Additional ADS specific limits are also applicable.
Transform
The transform process restructures data from the persistent stage tables to the output stage tables. This phase usually uses very specific SQL statements to transform data to a shapes that can be loaded into workspace datasets with simple SELECT queries. This phase usually breaks the business entity swim-lanes. Still this phase’s SQL statements should process data for all tenants of multi-tenant solution at the same time.
Transform Guidelines
Usually the transformation is implemented via some sort of INSERT … SELECT (full output stage build) or MERGE (incremental output stage build) SQL statements. So first and foremost, all General SQL Guidelines and the guidance from the Extract and Merge section apply here.
In general optimization for speed rather than storage footprint is recommended. In other words persist intermediary transformation results in local temporary tables instead of executing the same transformation multiple times. Also decouple complex SQL statements to a sequence of simpler statements that persist their results in local temporary tables.
The persistent output stage is especially important for multi-tenant solutions with multiple workspace loading processes (workspace per tenant scenario). You should move as much complexity as possible into as few SQL statements with one-per-all-tenants granularity.
The full reload of the output stages is recommended only for solutions with small data volumes (< 100M records). Larger output stages should be built incrementally. The guidelines described in the Merging Data to Persistent Tables apply to this incremental output stage reload.
Limits & Concurrency
All General Limits and the limits from the Extract and Merge section above apply.
Load
The load process transfers data from ADS output stage tables to a workspace. Unlike most of the previous phases, data is transferred between two physically separate data storages (Vertica => Postgres or Vertica => Vertica). It is important to recognize that in case of the multi-tenant solutions (PbG and EDM) the data needs to be usually transferred to multiple workspaces (there is usually one workspace per tenant). This implies higher query concurrency and this is why it is important for the load processes to only use trivial (SELECT * FROM output_stage_table type) SQL statements. If a solution requires any complex data transformation, the complexity should be moved to earlier phases (e.g. transform) that are executed once per all tenants.
The load phase can be implemented with platform processes (e.g. Ruby or CloudConnect) or with Automated Data Distribution. We recommend using Automated Data Distribution wherever possible as it contains bandwidth optimizations (e.g. skip the WebDav storage and JDBC proxy). Please refer to the Automated Data Distribution usage guidance in the Workspace Data Loading with Custom Fields Blueprint document.
Load Guidelines
The load process should have as low footprint on ADS as possible. We recommend only simple SELECT * type of queries with no GROUP BY, SORT, JOINs, no subqueries in the WHERE clause. A simple WHERE clause is OK.
In multi-tenant solution the shared ADS output stage table’s data are distributed into multiple workspaces. A simple discriminator column (ideally project PID) should be used in the WHERE clause to identify the records loaded to a specific tenant’s workspace.
Please refer to the Workspace Data Loading Blueprint document for the workspace data loading specific guidance.
The load process must be deployed to the target workspace where the data is analyzed. In case of a multi-tenant solution, there are multiple concurrent processes deployed to tenant workspaces. The load processes must be scheduled to run after the shared transform process finishes loading into the ADS output stage tables. The Schedule Execution Brick implementation of cross-project scheduling is recommended for the multi-tenant processes. Make sure that the number of concurrent queries is aligned with the maximum concurrent ADS processes limit.
Use Automated Data Distribution wherever applicable as it provides optimized workspace data loading.
Limits & Concurrency
All General Limits and the limits from the Extract and Merge section apply. Please refer to the workspace loading limits in the Workspace Data Loading Blueprint document.
Multi-tenant Solutions (PbG and EDM)
This paragraph summarizes the guidelines for implementing multi-tenant solutions (e.g. PbG or EDM) that involve multiple workspaces (one per each solution tenant / end customer).
Download, Extract, Merge, and Transform Platform Processes
The Download, Extract, Merge, and Transform phases of the data pipeline must process all tenants data (no process instances on per-tenant basis). In other words, the number of solution process invocations (that implement Download, Extract, Merge, and Transform phases ) executed on the platform must not grow with the number of tenants. These shared data processes are deployed in a solution-specific project and are organized in a simple workflow using the run-after schedule triggers.
High-Frequency ELT
For solutions where high-frequency loads (i.e. more than 12 loads per day) are required and cannot be met by the single transformation process as outlined above due to a large number of tenants (typically more than 1000) the following recommendations apply:
Parallel Execution
Design and implement transformation SQLs so that multiple instances of expensive and time consuming queries can execute in parallel while each executing instance operates on a different subset of data. Do this especially in cases when transformations are MERGE JOIN heavy.
Simplified example: instead of doing single INSERT FROM SELECT <complex transform> do multiple ( N) INSERT FROM SELECT <complex transform> WHERE HASH(<columns>) % N = i.
The <columns> should be those on which the physical projection is sorted by. Implementing parallelism like this is usually not straightforward for transformations that perform aggregations - such transformations may need further changes to produce correct results.
Allow Concurrent Transformation and Upload to Workspaces
Do not let upload to workspaces block transformation of data for the next increment. Use append-only output stage tables so that the running transformation cannot touch the data concurrently being uploaded to workspaces from output stage. While this is not a complex thing to do, remember that output stage compaction mechanisms should also be in place to prevent running out of disk space.
Additional Considerations
The bigger the solution, the more important to have optimal transformation phase. Strongly consider the following:
If possible denormalize data model and favor duplication - especially if there are large dimension tables
If joins cannot be avoided optimize for MERGE JOIN - even at the cost of additional projections or intermediate materialization steps
- Not doing this may lead to out of memory issues - especially when applying parallel execution as outlined above.
Review Take Advantage of Table Partitions and decide whether it is possible to use partitioning to speed up upload to workspaces or MERGE operations.
Loading Workspaces Processes
The workspaces loading uses one platform process per tenant. The workspace loading processes are deployed into each tenant’s workspace. The GoodData platform does not currently support cross-workspace schedule triggers. We recommend using the Schedule Execution Brick implemented by GoodData services for triggering the workspace loading processes (deployed in the tenant’s workspaces). The scheduling mechanism should only trigger the processes for workspaces that have changed data in the ADS output stages.
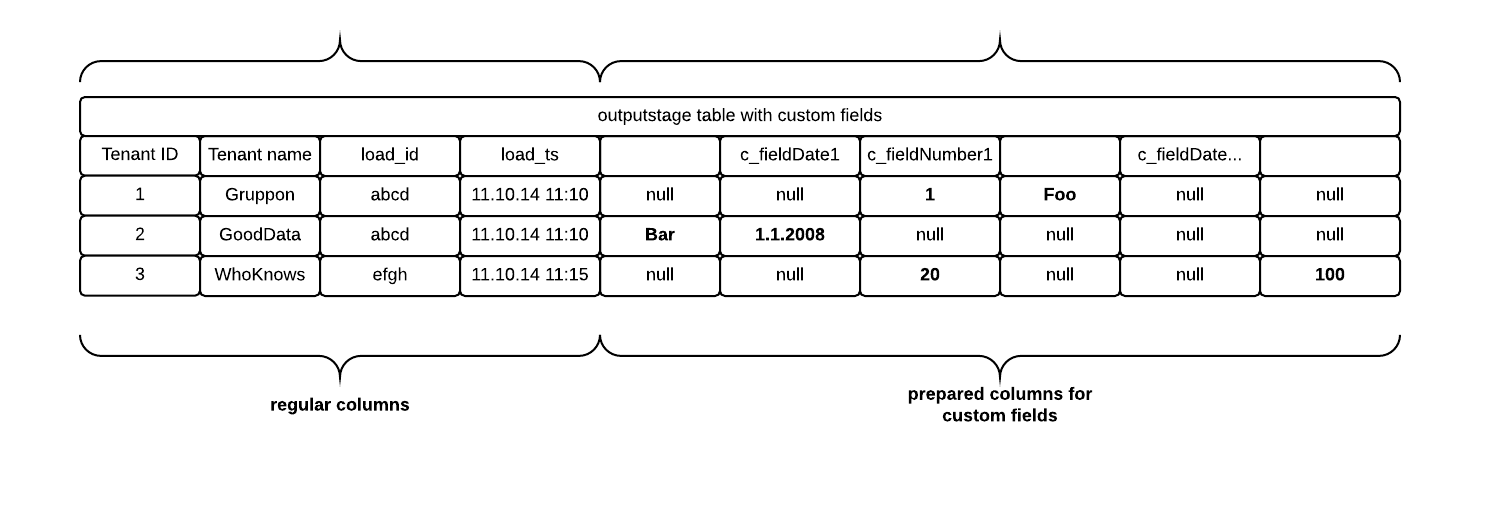
Custom Fields Processing
Custom fields are feature of the multi-tenant solutions. A solution tenant (end customer) can customize their workspace LDM with a specific set of data fields (dates, attributes, facts). ADS supports at most 250 columns. So the 250 is the limit for total number of an entity’s standard and custom fields.
The initial data flow phases (Download, Extract, Merge, and Transform) process all tenants data at once. The underlying data structures (ADS tables) are shared by all tenants. The all tenants set of custom fields can easily outgrow the ADS table columns limit. So we need to use generic column approach for implementing custom fields.
Generic Custom Fields
The generic custom fields approach extends each ADS table (in all stages) with generic columns. There are generic dates, generic textual columns, and generic numeric columns in all tables. Each tenant uses a different set of fields to store their custom fields. All data pipeline transformations and mappings (e.g. ADS output stage to workspace) must understand and correctly map the specific tenant’s custom ADS columns to the custom fields in the data source and LDM.