Data Pipeline Blueprints
Data pipeline blueprints describe the data extraction and transformation. This article describes the general flow of building a pipeline. For a comprehensive guide, see ELT Blueprint.
End-to-End ELT
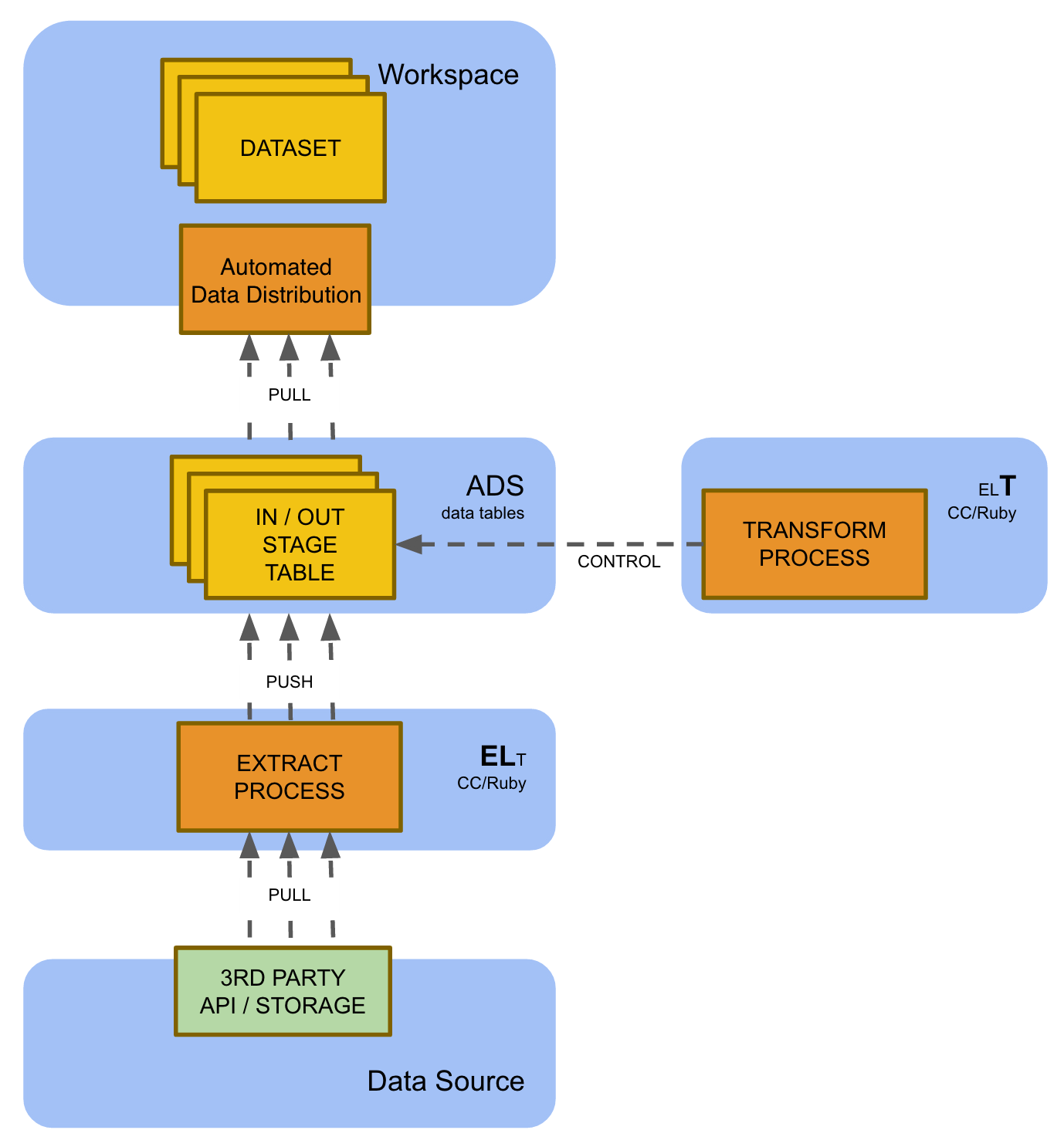
This is currently the most comprehensive GoodData data pipeline blueprint. End-to-End ELT (Extract Load Transform) leverages a custom extraction process (Ruby) for incremental data extraction, staging data transformation in ADS, and Automated Data Distribution (for details, see Automated Data Distribution).
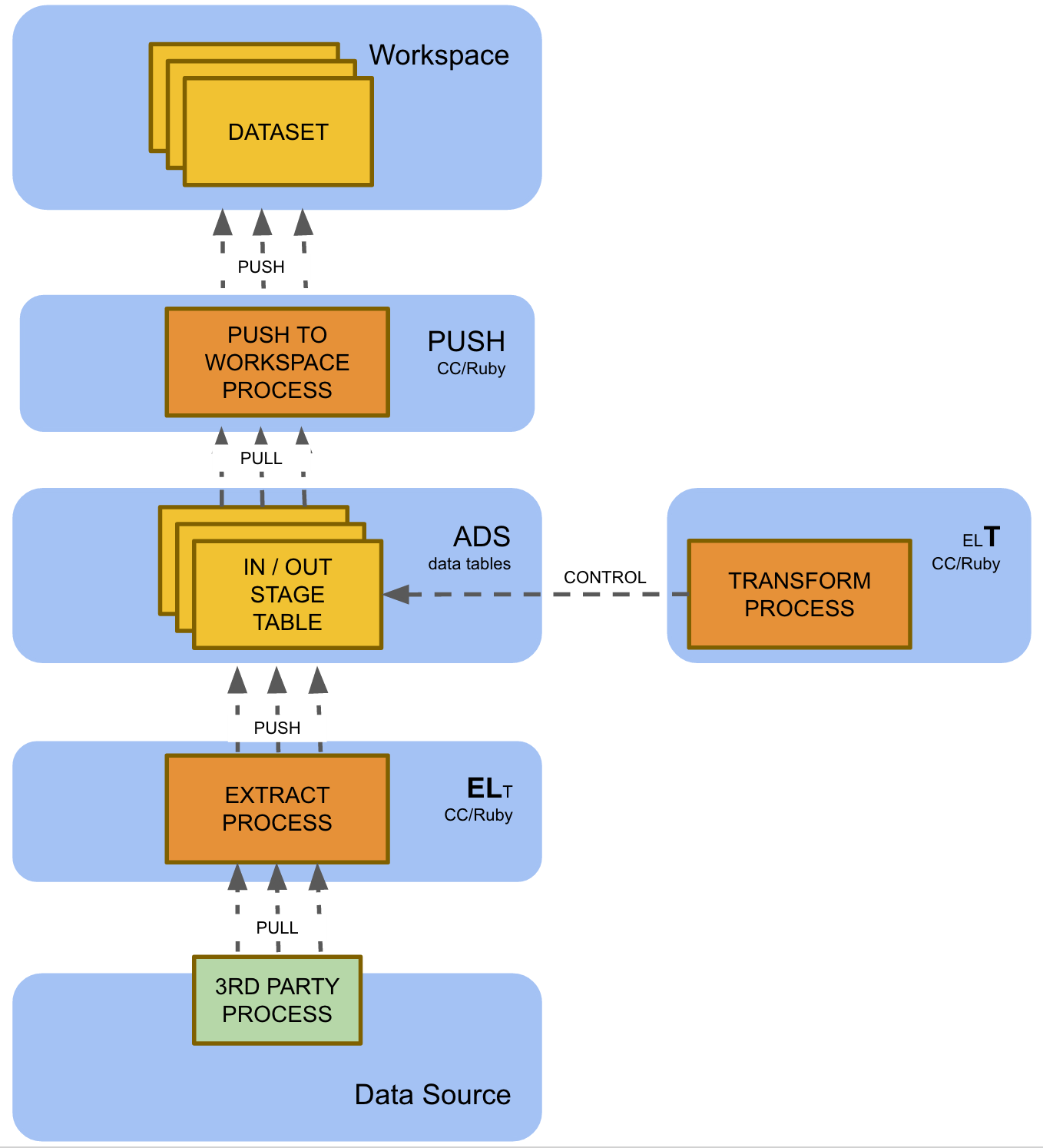
This blueprint is currently used for the largest GoodData multi-tenant solution implementations with hundreds and thousands of tenants. It is the only option in following situations:
- Multi-tenant solution that populates multiple workspaces with data, including:
- PbG (Powered by GoodData) solutions when the data is spread into multiple workspaces (usually a workspace is mapped to an ultimate customer/tenant)
- Corporate solutions that populate multiple workspaces (for example, sales/marketing/support workspaces) with data from a single ADS instance
- Incremental workspace data loading (large data volumes in workspaces)
There is a variant of this blueprint that leverages the Automated Data Distribution for workspace loading. This variant is recommended in situations when the data loaded to the workspace is small enough so it can be loaded in full. This may require a significant data aggregation or filtering (that reduces data volume) in the ADS.