GD Dataset Writer

We assume that you have already learned what is described in:
If you want to find the right Writer for your purposes, see Writers Comparison.
Short Summary
GD Dataset Writer writes data to a GoodData dataset.
| Component | Data output | Input ports | Output ports | Transformation | Transf. required | Java | CTL |
|---|---|---|---|---|---|---|---|
| GD Dataset Writer | GoodData Dataset | 1 | 0 | no | no | no | no |
Abstract
GD Dataset Writer writes data to a GoodData dataset. It maps the input data to a dataset's data loading columns. The writer supports both incremental loading and loading of all data.
Icon

Ports
| Port type | Number | Required | Description | Metadata |
|---|---|---|---|---|
| Input | 0 | yes | For received data records | Any |
This component has one input port and no output ports.
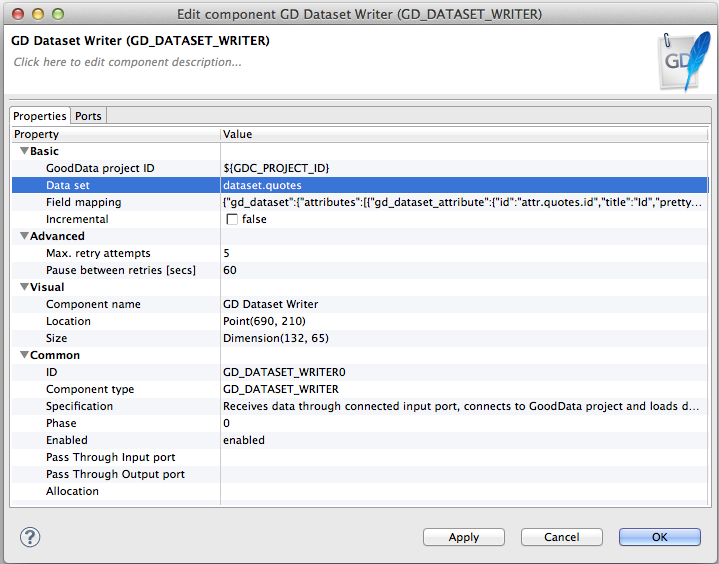
When you select this component, you must specify a GoodData project and a dataset to
which the data will be written. The component takes the current GoodData project by default (the project hash is stored in the GDC_PROJECT_ID parameter)
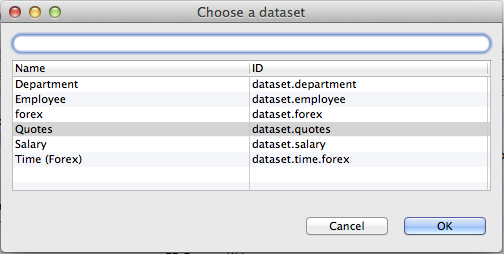
The most important attribute of the GD Dataset Writer is the Field mapping that defines how the input metadata fields map to the GoodData dataset columns. The mapping attribute is defined via the Mapping wizard in multiple steps. The first step involves matching of the input metadata fields (right side of the dialog) to the GoodData dataset's attributes, and facts. You need to select corresponding field in the Input fields drop-down listboxes. The dialog also takes care of the referenced datasets and date dimensions. The matching date dimension must be specified for date fields.
![[Note]](figures/note.png) | Note |
|---|---|
| See the Extracting Metadata from a GoodData Dataset for more details about deriving CloudConnect metadata from a GoodData dataset. |
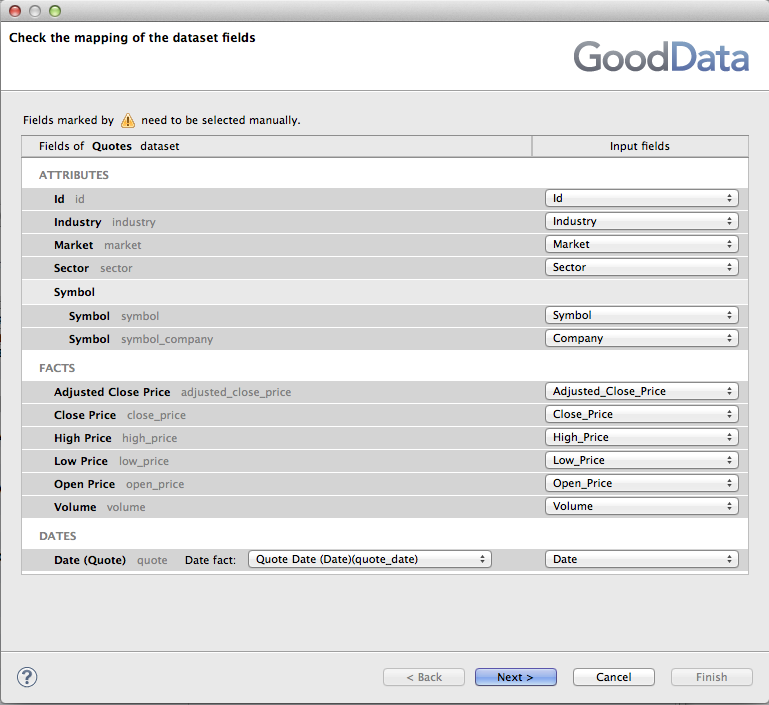
Similarly a referenced dataset connection point's label must be selected for linking the target dataset's to another dataset.
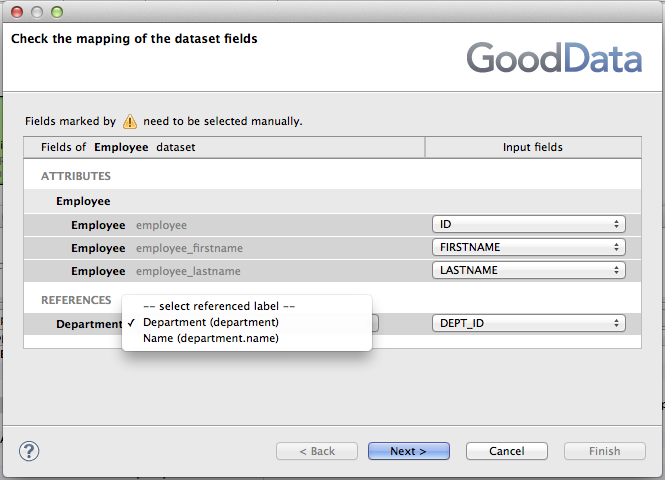
There are additional wizard steps for every dataset's attribute with multiple labels. A label that uniquely identifies every attribute's value must be selected in these steps. You'll usually select some kind of ID of the attribute here.
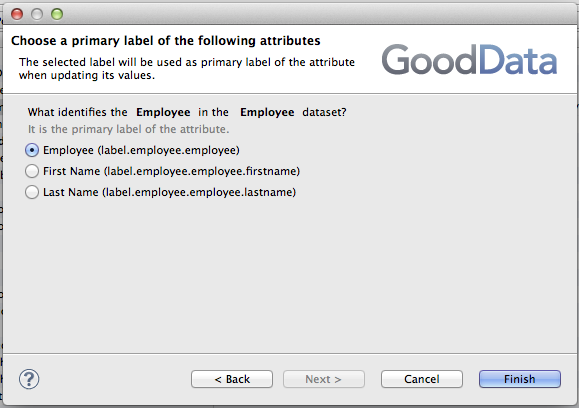
It is very important to decide whether the records should be
appended to the existing records in the dataset (Incremental = true) or whether the current data will be overwritten (Incremental = false).
The component supports advanced retry mechanism that can be parametrized by the Max. retry attempts and Pause between retries [secs] parameters.
GD Dataset Writer Attributes
| Attribute | Req | Description | Possible values |
|---|---|---|---|
| Basic | |||
| GoodData project ID |  | Specifies the GoodData project where the target dataset resides. The current project (project's hash in the GDC_PROJECT_ID parameter) is used by default. | Any valid GoodData project hash. The user who is logged in the CloudConnect Designer must have permission to access the project. |
| Dataset | | A target dataset where the data will be written. | |
| Field mapping | yes | Mapping of the input fields to the dataset loading columns. Please use the attribute dialog for the mapping definition. The mapping defines how input fields map to the columns that the selected GoodData dataset uses for data loading. | |
| Incremental | | Specifies if the data are appended to the existing data (true) or overwritten (false). | true/false |
| Advanced | |||
| Max. retry attempts | | Maximum number of retries that will be attempted if the previous attempts failed. Default value is 5. | |
| pause between retries [secs] | | This value specifies the delay between individual retries in seconds. Default is 60 seconds. | |