Comparando valores filtrados dinamicamente em um único relatório
Ao trabalhar com GoodData, os usuários muitas vezes restringem os dados de um relatório com um filtro de dashboard para que determinadas categorias de dados sejam omitidas, enquanto outros são incluídas nos cálculos do relatório.
Este artigo discute o cenário no qual você deseja permitir que usuários comparem os valores de uma métrica, quando todas as categorias estão incluídas com os seus valores e algumas categorias são filtradas, e o usuário deseja usar um filtro de dashboard para controlar dinamicamente as categorias filtradas em um determinado tempo.
Imagine que você deseja comparar uma métrica entre dados filtrados para segmentos específicos para o valor em todos os segmentos - e tudo isso em um único relatório. Por exemplo, você deseja visualizar a tendência em um gráfico de linha com uma linha que representa o segmento selecionado e outra para toda a base.
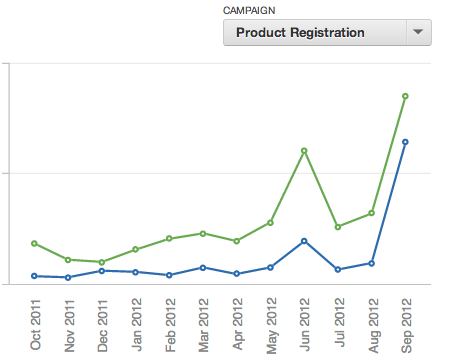
Nesse cenário, o usuário deve ser capaz de selecionar o segmento dinamicamente usando um filtro de dashboard.
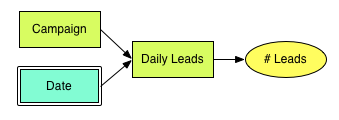
Por exemplo, você pode rastrear o número médio diário de negócios pontenciais advindos de várias campanhas de marketing, que naturalmente se traduzem para o modelo de dados lógico a seguir:
Solução 1: FILTRO PRINCIPAL WITHOUT
Os requisitos parecem implicar que precisamos de duas métricas: Média diária de negócios potenciais pelo filtro de campanha e uma métrica semelhante que não é filtrável. Vamos definir nossas duas métricas como segue:
Nº médio de negócios potenciais
SELECT AVG(Nº de negócios potenciais)
# médio de negócios potenciais (todos os registros)
SELECT AVG (Nº de negócios potenciais) WITHOUT PARENT FILTER
A cláusula WITHOUT PARENT FILTER isola eficazmente todos os filtros definidos nos dashboards, relatórios ou métricas exteriores. Isso é resolvido, mas tem um efeito colateral indesejado: nosso dashboard pode incluir outros filtros (tipicamente um filtro de data) que se espera que afete as méticas tanto ‘parcialmente’ como ‘integralmente’ - se você selecionar para filtrar o período dos últimos 30 dias, seu interesse é na contribuição de campanha para todos os negócios potenciais criados durante os últimos 30 dias, em vez de todos os negócios potenciais em geral.
Solução 2: Variáveis
Existem três tipos de menus suspensos de filtro que podem ser colocados em dashboard do GoodData: filtro de atributo, filtros de data e filtros variáveis. Mais comumente, só usamos filtros de atributo e a data, mas filtros variáveis podem ser muito úteis em algumas situações específicas.
Variáveis GoodData filtradas são realmente apenas duplicatas de outros atributos de projeto que são pré-filtradas para um subconjunto do valores de atributo. Em outras palavras, as variáveis filtradas são espaços reservados para a expressão: “Attribute IN (Value1, Value2, …).”
O GoodData também comporta variáveis numéricas, mas elas não são relevantes neste caso). Mas também é possível criar uma variável para servir como uma duplicata de algum atributo sem realmente filtrar nenhum de seus valores. Na verdade, a configuração padrão é não filtrar quaisquer valores.
Depois de criar uma variável filtrada, você pode usá-la para ajudar a definir relatórios (através de filtros de variável) e métricas como o seguinte:
SELECT AVG (Nº de negócios potenciais) WHERE Campaign_Variable
Tenha em mente que quando Campaign_Variable é definida de tal forma que não há valores de atributo filtrados para serem excluídos, a métrica acima irá calcular resultados idênticos à métrica SELECT AVG (Nº de negócios potenciais). Mas com um filtro de dashboard Campaign_Variable, os usuários serão capazes de redefinir Campaign_Variable dinamicamente, manipular eficazmente a métrica variável, enquanto a métrica original permanece inalterada.
Enquanto as variáveis nos permitem atender a todos os nossos objetivos originais, elas têm pelo menos uma deficiência. Enquanto filtros de dashboard de atributo podem ser interligados em relações cascata matriz/secundário, isto não é compatível com filtros de variáveis. Se os filtro de dashboard em cascata são uma prioridade em seu projeto, pode ser necessário recorrer a outra solução.
Solução 3: Conectando campanhas indiretamente
A última solução pode parecer que foi projetada por um cientista maluco (na verdade, foi). Mas trata-se apenas uma aplicação bastante incomum de filtragem de conjunto de dados cruzados com injeção de filtro. É baseado na ideia de injetar um filtro (link) usando uma submétrica COUNT baseada em um conjunto de dados de associação (também conhecido como tabela de fatos sem rosto) conectando nosso conjunto de dados principal (negócios potenciais diários) e o atributo de campanha.
Isso exige uma mudança de modelo:

Como você pode ver, a campanha já não é mais referenciada por negócios potenciais diários. isso significa que perdemos a vantagem da métrica Negócios Potenciais Diários serem automaticamente filtradas por um filtro de dashboard de campanha - este é o comportamento pretendido.
Nossa métrica ‘parcial’ agora se parece com isto:
SELECT AVG(Nº de Negócios Potenciais)
WHERE (SELECT COUNT(Associação de Campanha de Negócios Potenciais Diários)
BY Negócios Potenciais, ALL OTHER) > 0
O truque é que o filtro de campanha afeta a submétrica COUNT, a parte BY negócios potenciais, ALL OTHER assegurará que a submétrica COUNT é calculada para cada registro de Negócios Potenciais Diários e a condição ‘maior que zero’ selecionará apenas os registros de Negócios Potenciais Diários de modo que eles estejam conectados à campanha selecionada através de pelo menos um registro na tabela de associação.
Se preferimos manter a campanha disponível para habitual divisão e filtragem em vez de movê-la para um conjunto de dados associado, podemos manter o modelo e adicionar um atributo duplicado que é usado apenas pelo filtro de dashboard. Nesse caso, o modelo de dados seria o seguinte:

A definição da métrica “parte” permanecerá o mesmo.
Conclusão
Um dashboard que compara uma seleção baseada em filtro com um valor não filtrado (ou até mesmo várias seleções de filtro entre si) pode ser feito facilmente com variáveis, pois elas permitem aplicar a regra de filtragem diretamente em uma parte específica de uma métrica, em vez da filtragem de toda a métrica.
Podemos produzir os mesmos resultados conectando o atributo de filtragem ao conjunto de dados principal indiretamente através de uma tabela de associação e aplicando o filtro a uma submétrica COUNT.
A versão mais trivial é adicionar a cláusula WITHOUT PARENT FILTER à métrica ‘inteira’. No entanto, não é prático, pois elimina todos os filtros, incluindo os filtros de data que geralmente queremos aplicar à ‘toda’ a métrica também.