Users Brick
The users brick helps you manage users within your domain or workspace. You can do the following:
- Add new users to the domain
- Add new users to the workspace
- Delete from the workspace the users not specified in the source data
- Update the existing users' information according to the source data
You can use the users brick even if you do not have LCM.
This article covers both use cases of using the users brick: when you have LCM and when you do not have LCM.
Look for the “LCM only” and “Non-LCM only” notes to find information relevant to your situation. The information not marked with one of those notes is relevant for both LCM and non-LCM use cases.
For information about how to use the brick, see How to Use a Brick.
In GoodData, terms workspace and project denote the same entity. For example, project ID is exactly the same as workspace ID. See Find the Workspace ID.
Prerequisites
Before using the users brick, make sure that the following is true:
- A domain is implemented at your site, and a domain admin exists.
- A workspace and a workspace admin exist in your domain.
How the Brick Works
Based on the parameters that you specified, the users brick does some or all of the following:
- Adds new users to the domain
- Adds new users to the workspace
- Deletes from the workspace the users not specified in the input data
- Updates the existing users' data according to the input data
Adding Users to a Domain and a Workspace
Adding a user consists of two consecutive steps:
- A user is added to a domain. The user can now access the GoodData platform but cannot access any workspace. In the context of access rights, the domain is not connected to any workspace, and the user added to the GoodData platform cannot access any workspace on the platform until added or invited to the workspace. The user can be added to the platform by either of the following ways:
The user can sign up themselves.
The domain admin adds the user.
The domain admin can see all the users within the domain and manage them, as needed. The domain admin is the only person who can access the domain as an entity. For more information, see Your GoodData Domain.
- The user is added or invited to a workspace with a user role assigned (see User Roles). The user is now allowed to perform certain operations upon the workspace data according to their role. A user role is a set of permissions that a user is given within a particular workspace. A workspace admin can invite a user to a workspace by email, but only a domain admin can add the user directly.
Updating Users in a Domain and a Workspace
When you use the users brick to update the domain, all the users that you provided in the source data are added to the domain.
- The new users (present in the source data, not present in the domain) are added.
- The existing users (present in the source data and in the domain) are updated.
- If you did not provide an update for a specific user or a user’s property, this user/user’s property remains intact.
In other words, only the users/properties that you explicitly specified will be updated. If you did not mention a user/property in the input data, this user/property will not be touched.
Let’s look at the example. Imagine your source data looks like this:
| login | |
|---|---|
| john@example.com | john@company.com |
The current data in the domain looks like this:
| login | first_name | last_name | |
|---|---|---|---|
| john@example.com | john@example.com | John | Doe |
After you run the users brick, the data in the domain will look like the following:
| login | first_name | last_name | |
|---|---|---|---|
| john@example.com | john@company.com | John | Doe |
Notice that John’s email was updated while the rest of the information was not.
When you use the users brick to update a workspace, the source data shows how the workspace will look like after the update (declarative mode).
- Users that are in the workspace but not in the source data will be removed from the workspace.
- Users that are in the source data but not in the workspace will be added to the workspace.
- Existing users are updated according to the source data.
Let’s look at the example. Imagine your source data looks like this:
| login | first_name | last_name | role |
|---|---|---|---|
| john@example.com | John | Doe | adminRole |
| jane@example.com | Jane | Doe | editorRole |
| todd@example.com | Todd | Man | adminRole |
The current data in the workspace looks like this:
| login | role |
|---|---|
| john@example.com | adminRole |
| jane@example.com | adminRole |
| seth@example.com | readOnlyUserRole |
After you run the users brick, the data in the workspace will look like the following:
| login | first_name | last_name | role |
|---|---|---|---|
| john@example.com | John | Doe | adminRole |
| jane@example.com | Jane | Doe | editorRole |
| todd@example.com | Todd | Man | adminRole |
Notice the following:
- The user “todd@example.com” was added to the workspace because they were in the source data but not in the workspace.
- The user “seth@example.com” was removed from the workspace because although they were in the workspace, they were not in the source data.
- The role of the user “jane@example.com” was updated to what was in the source data because this user existed in both the source data and the workspace but the role was different.
- The user “john@example.com” remained the same as they were identical in both the source data and the workspace.
Input
The users brick expects to receive the data about users: a list of users and their properties (login, first name, last name, and so on).
At most, you can provide the following information for a user:
| client_id* | login* | first_name | last_name | role* | password | authentication_modes | sso_provider | user_groups* | language* | |
|---|---|---|---|---|---|---|---|---|---|---|
| client_1 | john@example.com | John | Doe | adminRole | john@example.com | password | group_admin | fr-FR | ||
| client_2 | jane@example.com | Jane | Doe | editorRole | jane@example.com | sso | saml-example.com |
The properties marked with an asterisk have special rules:
- client_id Use the name
client_idfor this column only if you have LCM. If you do not have LCM, this column must be namedproject_idand contain the IDs of your workspaces. If you storeclient_id’s values in a database, store them with theVARCHARdata type. - login The login must be a string in the format of an email address but does not have to be an actual working email address. You can generate logins from unique user IDs used on your site (for example,
123456@gd.example.com,234567@gd.example.com, and so on). For receiving emails sent by GoodData (such as notifications or scheduled emails), you set the email for each user via theemailproperty. A user’s email can (but does not have to) be the same as the login. The email does not have to be unique within the domain. The values in the “login” column are case-sensitive and must be written in lowercase.- Correct: john.doe@example.com
- Incorrect:
John.Doe@example.com
- role To review the values that the “role” column can contain (that is, user roles that users can have), see User Roles. Use the role identifiers, not the role names. You can also define custom roles for your workspaces (see Create a Custom User Role).
- Correct:
adminRole - Incorrect:
Administrator
- Correct:
- user_groups The following rules apply to this column:
- You can add a user to an existing user group by specifying the group name as the value.
- If the user group does not exist, the user group is created, and the user is assigned to the group as a member.
- You can remove a user from a user group by setting the value of
user_groupsfor the user to empty ornull. - If the
user_groupscolumn is omitted, then the users brick ignores user groups.
- language Setting the language works only in the
add_to_organizationsynchronization mode (see sync_mode) and thesync_domain_and_projectsynchronization mode (see Advanced Settings). If not set, the language defaults to English.
Set the language as an IETF language tag:
de-DEfor Germanen-AUfor English (Australian)en-GBfor English (British)en-USfor English (American)es-419for Spanish (Latin American)es-ESfor Spanishfi-FIfor Finnishfr-CAfor French (Canadian)fr-FRfor Frenchit-ITfor Italianja-JPfor Japanesenl-NLfor Dutchpt-BRfor Portuguese (Brazilian)pt-PTfor Portuguesezh-HKfor Chinese (Cantonese)zh-Hansfor Chinese (Simplified)zh-Hantfor Chinese (Traditional)
In addition to the data about the users, you have to add the parameters when scheduling the brick process.
Minimum Required Input Data
Depending on how you set up the users brick (whether you add users to the domain or to a workspace and what parameters you configured), the users brick requires different sets of input data about the users. For example, when you add users to the domain, the brick requires at least login information to be present in the input data. That is, the input data must contain at least a column named “login” with user logins:
| login |
|---|
| john.doe@example.com |
anna.doe@example.com |
All the other missing information will be auto-populated, such as:
- A missing first name will be set to “FirstName”.
- A missing second name will be set to “LastName”.
- A missing email will be set to be equal to the login.
- Passwords will be auto-generated.
The minimum required input data depends on the synchronization mode that you choose for the brick, which is set by the sync_mode parameter.
Parameters
When scheduling the deployed brick (see How to Use a Brick and Schedule a Data Loading Process), add parameters to the schedule.
General Parameters
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
organization | string | yes | n/a | The name of the domain where the brick is executed |
input_source | JSON | yes | n/a | The source to take input data from. For more information on input data JSON structures, see Types of Input Data Sources. You must encode this parameter using the Example: |
| sync_mode | string | yes | n/a | See sync_mode. |
| whitelists | array | no | n/a | The Typically, in your workspace you have users that are there for business reasons. However, sometimes you would also have technical users (users deploying the ETL processes), users from vendors, and so on. When updating the workspace, these non-business users will be deleted from the workspace unless explicitly specified in the input data. To avoid this, you can whitelist users or classes of users who should be excluded from the process of adding and deleting users. The user logins are case-sensitive and must be written in lowercase. You must encode these parameters using the Examples: NOTE: Avoid using these parameters or use them as little as possible. If you decide to exclude some users, you have to always remember what users are excluded in what workspaces and act accordingly when you update users in these workspaces. Having too many users excluded from processing may cause data inconsistency in your workspaces. |
| regexp_whitelists | array | no | n/a | |
| skip_actions | array | no | n/a | The actions or steps that you want the brick to skip while executing (for example, collecting data products) The specified actions and steps will be excluded from the processing and will not be performed. NOTE: Using this parameter in a wrong way may generate unexpected side effects. If you want to use it, contact the GoodData specialist who was involved in implementing LCM at your site. |
sync_mode
The sync_mode parameter specifies the synchronization mode for the brick; that is, how the users' data will be synchronized in the domain and/or workspaces.
(LCM and non-LCM) add_to_organization: Synchronizes the users in the domain. All the users that you provided in the source data are added to the domain.
- (LCM only) Brick deployment: service workspace (see How to Use a Brick)
- (LCM and non-LCM) Minimum required input data: user logins (the “login” column is filled in). Missing information will be auto-populated. For more information, see Minimum Required Input Data. The input CSV file is de-duplicated by login, which may be duplicated because of the “project_id” or “client_id” column, to allow you to use the same input CSV file for the other modes.
- Users existing in the domain but not present in the source data will not be deleted from the domain. To delete users from the domain, use the
remove_from_organizationsynchronization mode (see Advanced Settings).
(LCM only) sync_domain_client_workspaces: Synchronizes the whole domain or the specified segments. This mode is fully declarative: any users or user filters that exist in the client workspaces but do not exist in the input data will be deleted from the workspaces. In other words, what is in the input data will be in the client workspaces, anything extra will be deleted.
- Brick deployment: segment’s master workspace (see How to Use a Brick)
- Minimum required input data: user logins, user roles, and workspace IDs (the “login”, “role”, and “client_id” columns are filled in). That is, the input data should define what user should go to what workspace and what user role should be assigned.
- To limit the synchronization scope to only specific segments, use the
segments_filterparameter (see Parameters). Any client workspaces outside the specified segments will not be touched. - To keep in the workspaces the users and user filters that are not explicitly specified in input data, set the
do_not_touch_users_that_are_not_mentionedparameter totrue(see Mode-Specific Parameters).
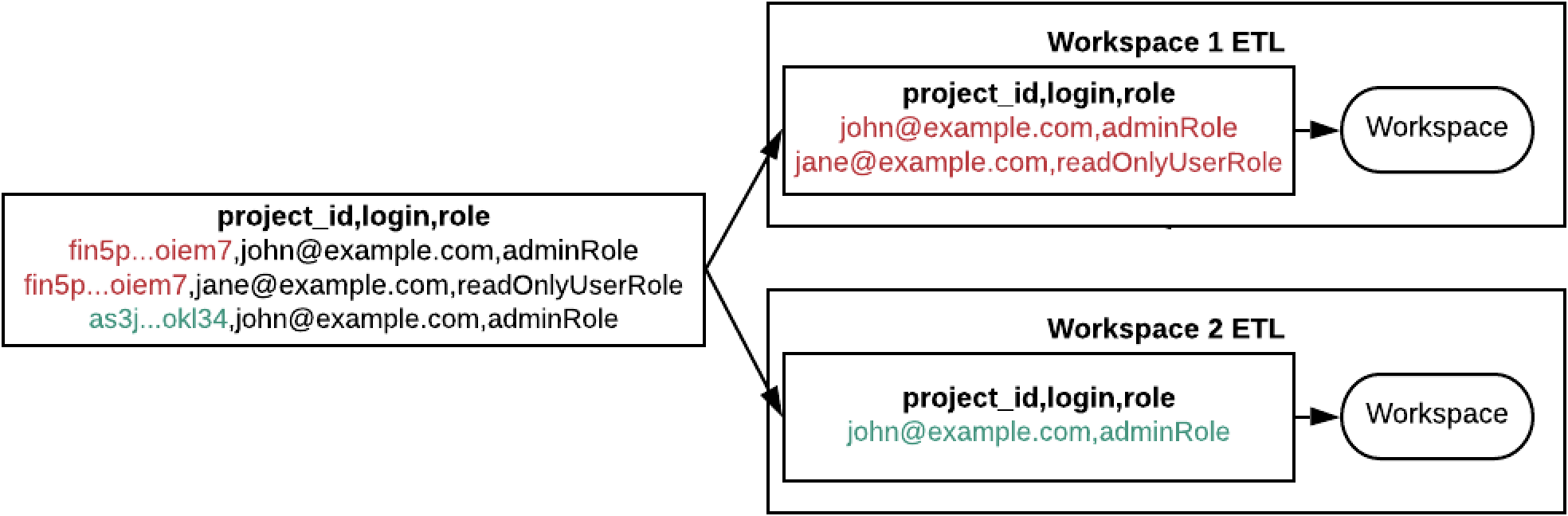
(Non-LCM only) sync_multiple_projects_based_on_pid: Synchronizes multiple workspaces from the same source data using a single process. Distributing users among workspaces is done based on workspace IDs (project IDs). Use this mode when you have several workspaces, and synchronizing them one by one is time-consuming.
- Minimum required input data: user logins, user roles, and workspace IDs (the “login”, “role”, and “project_id” columns are filled in). That is, the input data should define what user should go to what workspace and what user role should be assigned.

These three modes are the most commonly used and cover the majority of the use cases. There are advanced synchronization modes that can be used in very specific cases. Before using an advance synchronization mode, contact GoodData specialist who is working with you on setting up the bricks.
What synchronization modes to choose depends on whether you use LCM.
- If you have LCM:
- Use the
add_to_organizationsynchronization mode to add users to the domain. - Use the
sync_domain_client_workspacessynchronization mode to propagate the users from the domain to the client workspaces.
- Use the
- If you do not have LCM:
- Use the
add_to_organizationsynchronization mode to add users to the domain. - Use the
sync_multiple_projects_based_on_pidto propagate the users from the domain to your workspaces.
- Use the
Each synchronization mode has its own unique set of mode-specific parameters in addition to the general parameters. Once you decide what synchronization mode you want to use, review the mode-specific parameters and provide them in the brick schedule.
Mode-Specific Parameters
Depending on the synchronization mode, provide the corresponding mode-specific parameters (see Configuring Schedule Parameters).
| Synchronization Mode | Parameter Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|---|
| add_to_organization | authentication_modes | string or array | no | n/a | See authentication_modes. |
sso_provider | string | see "Description" column | n/a | (Use only when the The | |
sync_domain_ client_workspaces | do_not_touch_users_ that_are_not_mentioned | Boolean | no | false | Defines how to manage the users that are not explicitly specified in the input data during the synchronization of the domain and workspaces.
Set this parameter to Do not use this parameter if you want to delete some users from the workspace. With this parameter set to NOTE: You can further narrow down the sub-set of users to process. For example, the following query will instruct the brick to process only the users modified in the last seven days: |
| data_product | string | no | default | The data product that contains the segments that you want to release If the specified data product does not exist, it is created. | |
| segments_filter | array | no | n/a | The segments that you want to synchronize You must encode this parameter using the We recommend that you use this parameter to prevent all users from different segments from being deleted. Example: | |
sync_multiple_projects_ based_on_pid | No mode-specific parameters exist for this mode. | ||||
authentication_modes
The authentication_modes parameter specifies how users can access the GoodData platform. You can choose from the following authentication modes (or use both of them):
password: Users access the GoodData platform using their credentials.sso: Users access the GoodData platform via SSO.
You can set up the authorization in the following ways:
Globally for all synchronized users: All users receive the same setting (password or/and SSO). This way, you do not have to specify authentication mode for each user; you just set it globally for everybody in your brick parameters. When the
authentication_modesparameter is set, any user-specific authentication mode settings that are set in the “authentication_modes” column will be ignored. You can specify one or several values. If you setauthentication_modestosso, you must also provide the value for thesso_providerparameter (see Mode-Specific Parameters). Thesso_providerparameter overrides any user-specific SSO provider settings that are set in the “sso_provider” column."authentication_modes": "password" "authentication_modes": ["password", "sso"]If you set theauthentication_modesparameter to an array of values ("authentication_modes": ["password", "sso"]), encode it using thegd_encoded_paramsparameter (see Specifying Complex Parameters).Set up individually per user: Each user has their own specific authentication mode. Your input data would look similar to this:
login first_name last_name authentication_modes anna.doe@example.com Anna
Doe
password
john.doe@example.com
John
Doe
password, sso
Do not provide the
authentication_modesparameter in the brick schedule if you want to set authentication mode per user in the source data. The brick will look into the schedule parameters first, will not find the globally set authentication mode, and will proceed looking for it in the source data.If you do set the
authentication_modesparameter, the brick will take it as the first choice and will ignore any user-specific authentication mode settings.If you specify the authentication mode in neither brick schedule nor source data, users will inherit its setting from the domain configuration.
Example - Brick Configuration
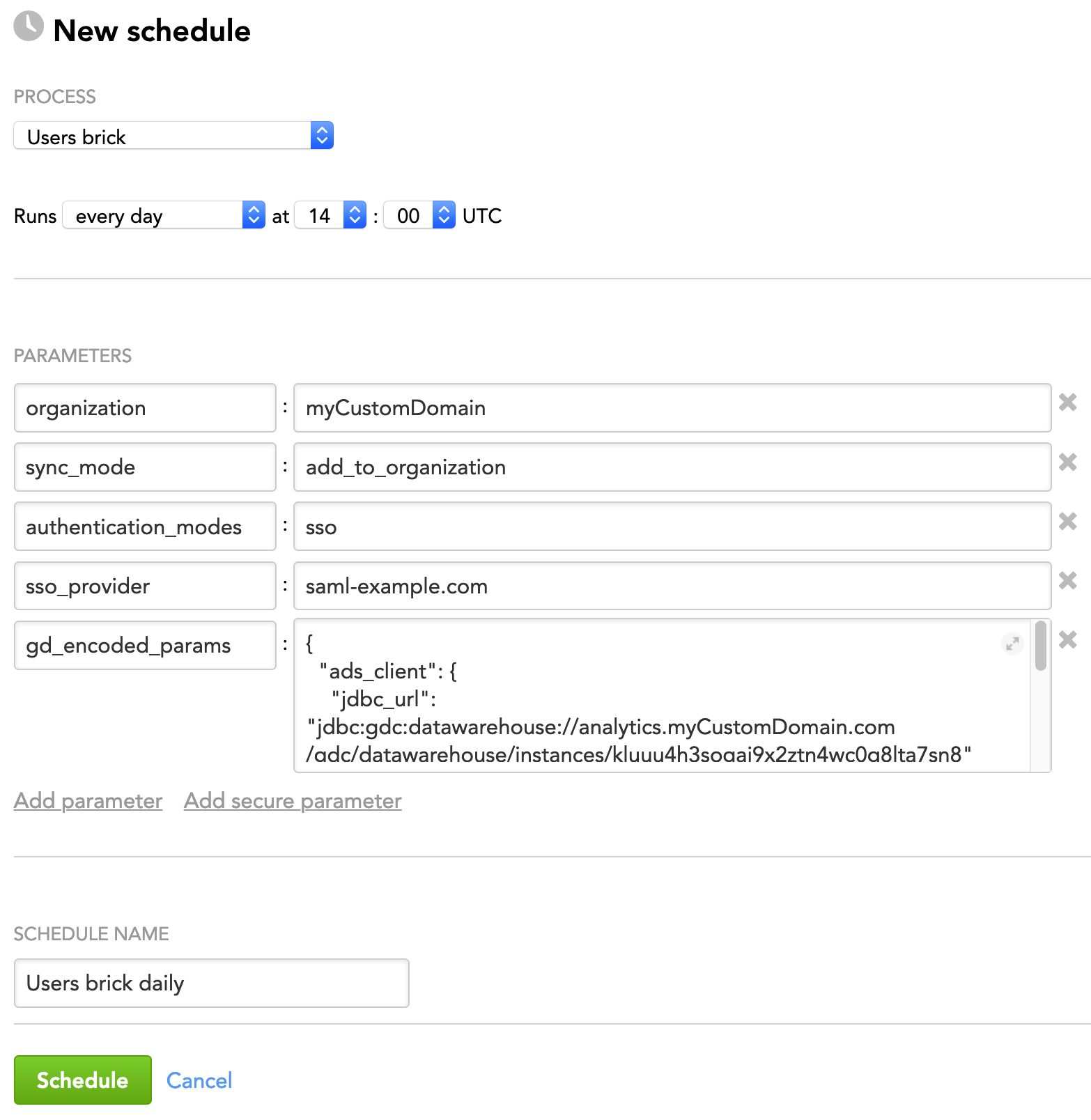
The following is an example of configuring the brick parameters in the JSON format:
{
"organization": "myCustomDomain",
"sync_mode": "add_to_organization",
"authentication_modes": "sso",
"sso_provider": "saml-example.com",
"gd_encoded_params": {
"ads_client": {
"jdbc_url": "jdbc:gdc:datawarehouse://analytics.myCustomDomain.com/gdc/datawarehouse/instances/kluuu4h3sogai9x2ztn4wc0g8lta7sn8"
},
"input_source": {
"type": "ads",
"query": "SELECT * FROM domain_users"
},
"whitelists": ["etl_admin@myCustomDomain.com", "etl_tester@myCustomDomain.com"]
}
}
Advanced Settings
This section describes advanced synchronization modes of the users brick.
Whenever possible, use the synchronization modes that are the most commonly used and cover the majority of the use cases (see sync_mode). The advanced modes should be used in very specific cases only. Before using an advanced synchronization mode, contact the GoodData specialist who is working with you on setting up the bricks.
- (LCM and non-LCM) remove_from_organization: Synchronizes the users in the domain. All the users that you provided in the source data are deleted to the domain.
- (LCM only) Brick deployment: service workspace (see How to Use a Brick)
- (LCM and non-LCM) Minimum required input data: user logins (the “login” column is filled in)
- Use this mode when data protection and privacy laws (for example, General Data Protection Regulation (EU GDPR)) require you to delete users and their information from the GoodData platform.
- (LCM only) sync_one_project_based_on_custom_id: Synchronizes one workspace from a single input source that may have input data for other workspaces, too. The brick will filter out the users for this particular workspace based on its client ID (CID), and will ignore the rest of the data. However, you may not know the workspace ID (PID). Instead of the unknown PID, you are going to use an internal ID (called “custom workspace ID”). Generate an internal ID for the workspace. When the workspace is created, this custom ID is stored in this workspace’s metadata. This way, the PID (that you do not know) is mapped to the custom ID (that you have generated). By the custom ID, the brick will be able to identify the workspace and obtain its PID.
Brick deployment: synchronized workspace (see How to Use a Brick)
Minimum required input data: user logins, user roles, and the client ID (the “login” and “role” columns are filled in; the “client_id” column contains the custom IDs (internal ID that you generated) or client IDs (CIDs)). Missing information will be auto-populated. For more information, see Minimum Required Input Data.
Notice that there are three groups of processes differentiated by color. The advantage is that these processes do not have to be synchronized and can run at their own pace.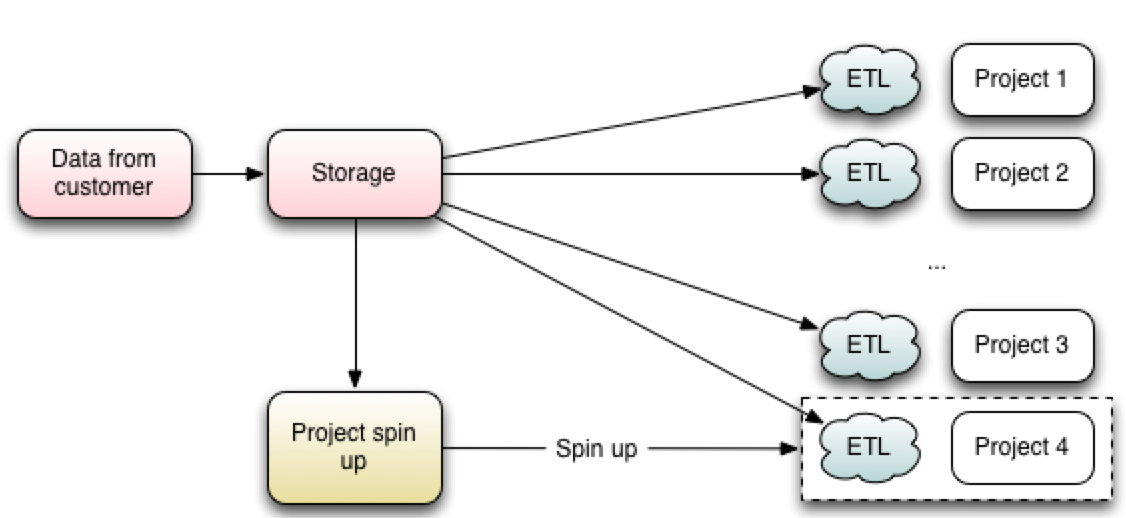
- Red: You load the data. At some point, the data is picked up and put into storage. This data contains the custom ID that would allow for sorting the data without knowing in which workspace they would end up.
- Yellow: At some point, the process responsible for maintaining workspaces and deploying them starts. The process identifies that a new workspace (Project 4) has to be spun up, so it spins it up. A part of this is deploying an ETL process and marking the deployed workspace with the custom ID.
- Gray: At some point, the ETL starts and processes the data. If it runs, it means that the data for this workspace is already in the storage.
Let’s look at how the ETL will run:
On the top, you can see datasets with data. There are two workspaces referenced there by custom IDs. All the other datasets use the custom IDs as a reference to the workspaces. Once the ETL starts, it accesses the data and processes it. One of the output objects will be a file that provides data about users in a particular workspace (bottom left).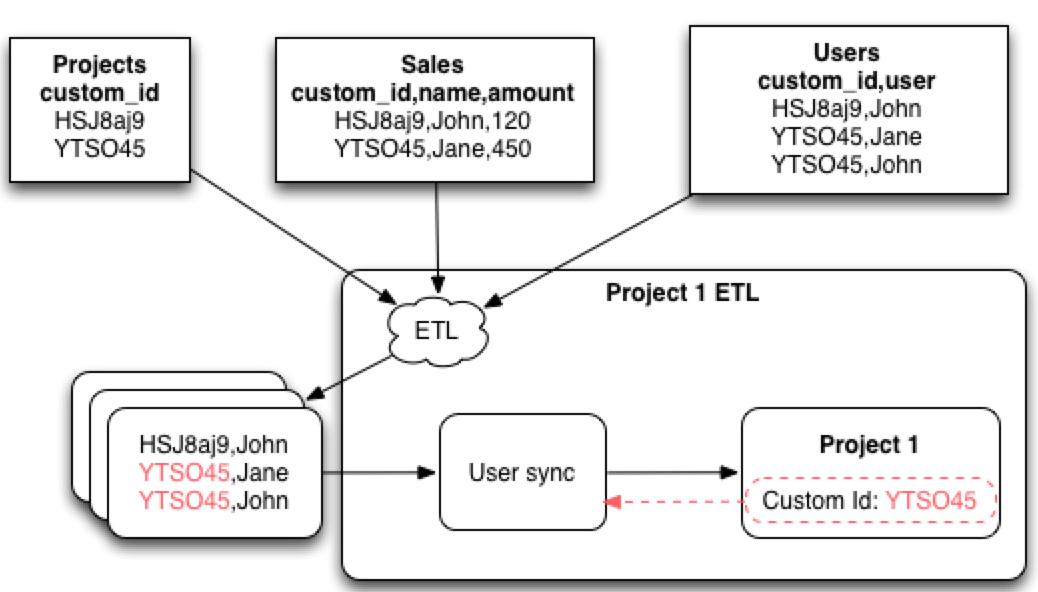
- (LCM only) sync_multiple_projects_based_on_custom_id: This mode is similar to the
sync_multiple_projects_based_on_pidmode (see sync_mode). The only difference is that the “project_id” column in the source data contains the client IDs instead of workspace IDs. - (Non-LCM only) sync_project: Synchronizes one workspace. The users have to exist in the domain. If they do not, the brick will fail.
- Brick deployment: synchronized workspace (see How to Use a Brick)
- Minimum required input data: user logins and roles (the “login” and “role” columns are filled in). Missing information will be auto-populated. For more information, see Minimum Required Input Data.
- (Non-LCM only) sync_domain_and_project: Synchronizes the domain and then the workspace. Use this mode when you have only one workspace, and splitting the domain and workspace synchronization into two tasks (synchronizing the domain and synchronizing the workspace) is not time-efficient.
- Brick deployment: synchronized workspace (see How to Use a Brick)
- Minimum required input data: user logins and roles (the “login” and “role” columns are filled in). Missing information will be auto-populated. For more information, see Minimum Required Input Data.
- (Non-LCM only) sync_one_project_based_on_pid: Synchronizes one workspace from a single input source that may have input data for other workspaces, too. The brick will filter out the users for this particular workspace based on its ID (PID), and will ignore the rest of the data. To use this mode, you have to know the workspace ID.
- Brick deployment: synchronized workspace (see How to Use a Brick)
- Minimum required input data: user logins, user roles, and the workspace ID (the “login”, “role”, and “project_id” columns are filled in). Missing information will be auto-populated. For more information, see Minimum Required Input Data.