Schedule a Data Loading Process for Manual Execution Only
You can schedule a data loading process that can be executed only manually: via the Data Integration Console (see Run a Scheduled Data Loading Process on Demand) or the API for executing schedules.
Such processes do not run at any specified time and do not allow you to set any time interval or condition for execution. You run them manually for specific use cases, for example:
Your data is delivered at irregular intervals, therefore you need to run a data loading process only when the next data batch is available. For example, you have a schedule that should run after an external process completes successfully, and you cannot predict how long this external process will take to complete.
You want to have a schedule that you run manually only in specific situations, for example, running full data load for all your workspaces; reloading data in case of inconsistency; restoring particular data from backup; performing one-time corrective actions, and so on.
However, be aware that depending on the process and the current state of the data in the target workspace, you may be inserting duplicate data in the workspace.
Steps:
Start creating a schedule as described in Schedule a Data Loading Process.
When selecting the frequency of execution, select manually.
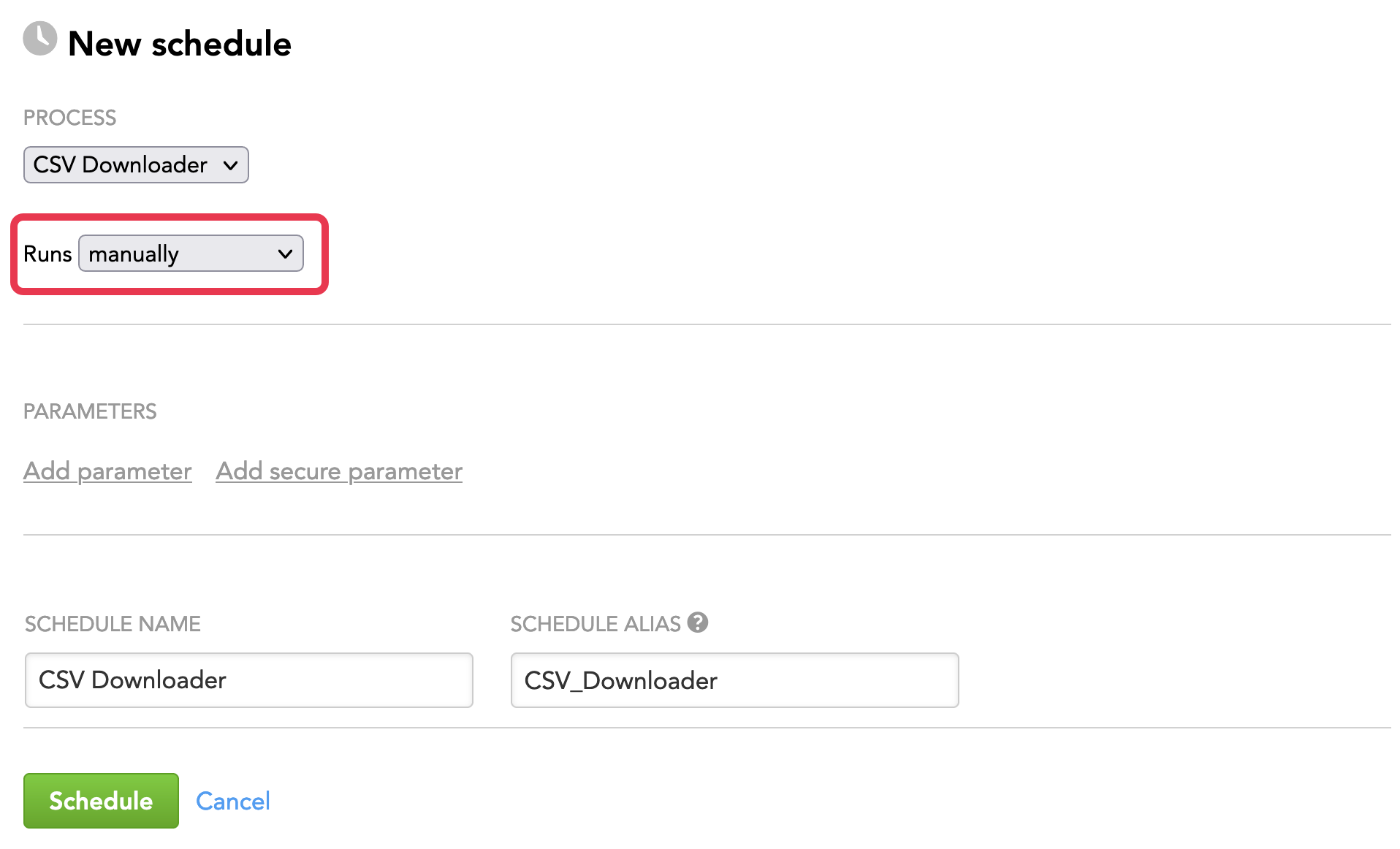
(Optional) Add additional parameters to your schedule. A parameter is a name-value pair that can be passed to the process before execution begins. If the process is designed to consume it, the parameter can be used to define variables specific to the execution. For example, you can define parameters for customer-specific login credentials for an external data source. For more information, see Configure Schedule Parameters.
(Optional) Specify a new schedule name.
Click Schedule. The schedule is saved and opens for your preview.
(Optional) Click Add retry delay to set up a retry delay period for your schedule. When a retry delay is specified, the platform automatically re-runs the process if it fails, after the period of time specified in the delay has elapsed. For more information, see Configuring Automatic Retry of Failed Processes.
To run the schedule, use the Data Integration Console (see Run a Scheduled Data Loading Process on Demand) or the API for executing schedules.