Schedule a Data Loading Process
Create a schedule to automatically execute an existing data loading process. You can configure a process schedule to run at a specified time or after another schedule, or to allow the schedule to be run only manually. Only one data loading process can be executed at a time.
You do not need to specify login credentials or be logged into the GoodData platform at the time of execution for a scheduled process to be initiated.
Data loading during business hours may negatively impact system performance. Frequent updates may also impact the performance of your workspaces. For more information, see Time a Scheduled Data Loading Process.
Schedule a Data Loading Process
Steps:
From the Data Integration Console (see Accessing Data Integration Console), click Workspaces.
Click the name of the workspace where you want to create the schedule, and click New schedule.
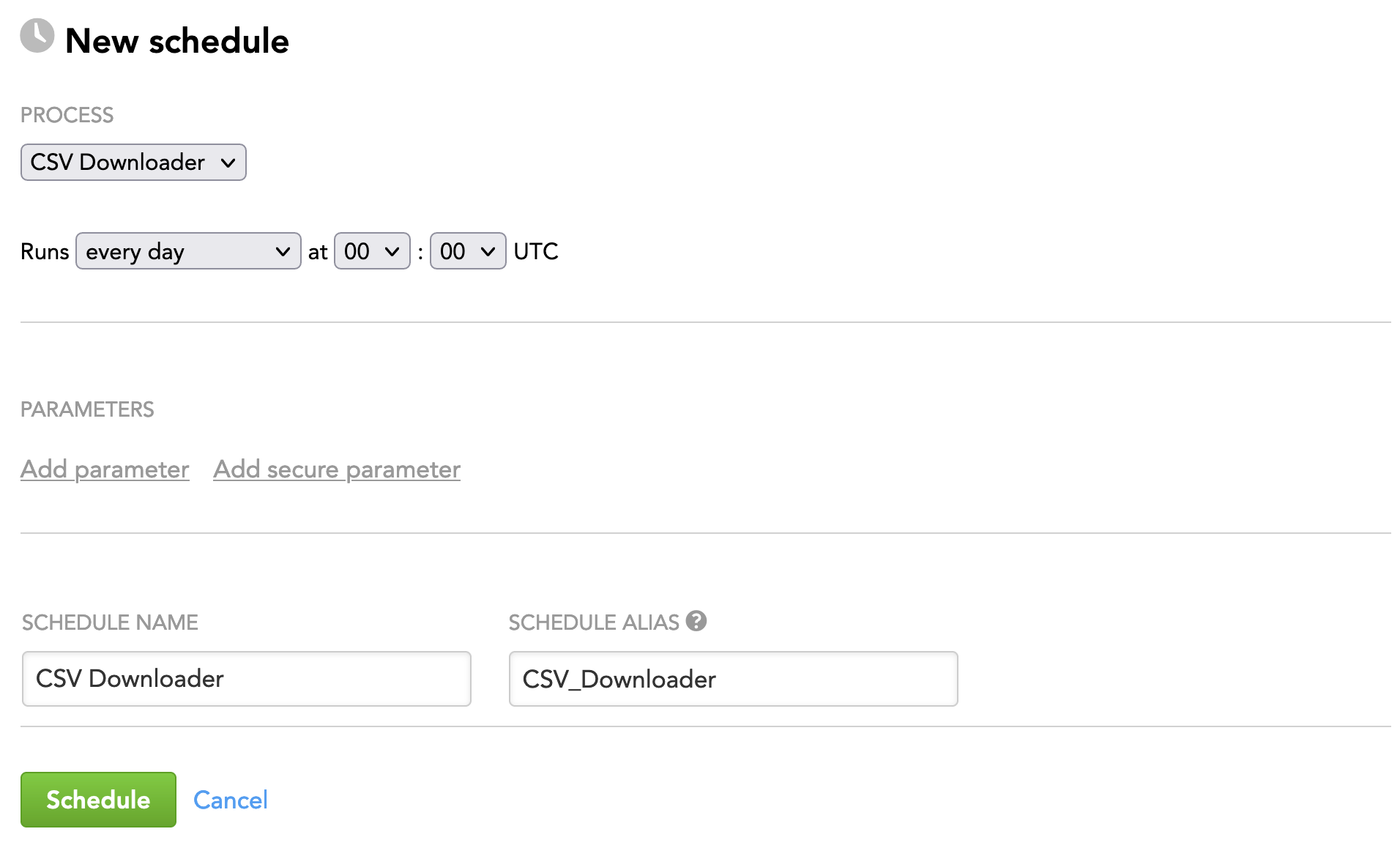
Select the process to execute.
Select the frequency of execution:
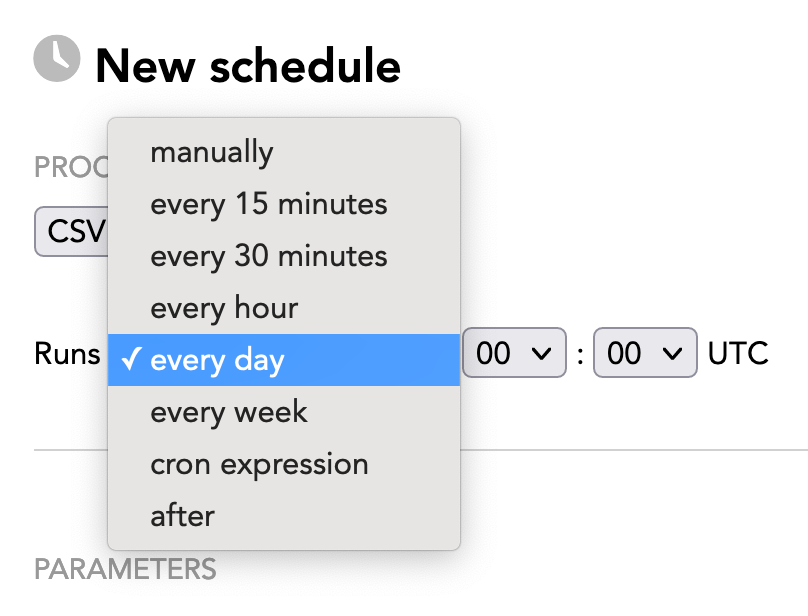
- Manually: The process will run only when manually triggered via the Data Integration Console or API; no time interval is set (for more information, see Schedule a Data Loading Process for Manual Execution Only)
- Time intervals between 15 minutes and a week (for more information, see Time a Scheduled Data Loading Process)
- Cron expression (for more information, see Time a Scheduled Data Loading Process)
- After: Specify another schedule in the current workspace after which your schedule should be executed (for more information, see Configure Schedule Sequences)
(Optional) Add additional parameters to your schedule. A parameter is a name-value pair that can be passed to the process before execution begins. If the process is designed to consume it, the parameter can be used to define variables specific to the execution. For example, you can define parameters for customer-specific login credentials for an external data source. For more information, see Configure Schedule Parameters.
If you are scheduling a process with Data Sources connected to it, you can reference the parameters from those Data Sources instead of entering explicit values. For more information, see Reuse Parameters in Multiple Data Loading Processes.(Optional) Specify a new schedule name. The alias will be automatically generated from the name. You can update it, if needed.
The alias is a reference to the schedule, unique within the workspace. The alias is used when exporting and importing the data pipeline (see Export and Import the Data Pipeline).Click Schedule. The schedule is saved and opens for your preview. The GoodData platform will execute the process as scheduled.
(Optional) Click Add retry delay to set up a retry delay period for your schedule. When a retry delay is specified, the platform automatically re-runs the process if it fails, after the period specified in the delay has elapsed. For more information, see Configure Automatic Retry of a Failed Data Loading Process.
If a schedule repeatedly fails, it is automatically disabled, and your workspace data is no longer refreshed until you fix the issue causing failure and re-enable the schedule. For more information on debugging failing schedules, see Schedule Issues.
Schedule Owner vs. Process Owner
In the schedule details dialog, the listed user name identifies the user under which the schedule executes. This user currently owns the schedule.
Because processes can be downloaded and redeployed at any time, the owner of the schedule can differ from the owner of the process. For example, if a process created by User A is redeployed by User B, all schedules associated with the process are now owned by User B, who will be the user under which all schedules for the process are henceforth executed.