Date Dimension Loader
Date Dimension Loader is a utility that supports the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). Date Dimension Loader loads date dimension data to date datasets in one or more workspaces based on the criteria that you have defined (where the date dimension data is stored and what workspaces to load it to).
For more information about date dimensions, see Manage Custom Date Dimensions.
How Date Dimension Loader Works
When Data Dimension Loader runs, it reads date dimension data and loads it to the workspaces according to the criteria that you have defined in queries:
- The date dimension data to read
- The location where the date dimension data is stored (a data warehouse or an S3 bucket)
- The workspaces to load the date dimensions to
Configuration File
Date Dimension Loader does not require any parameters in the configuration file.
Schedule Parameters
When scheduling Date Dimension Loader (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| gd_encoded_params | JSON | yes | no | n/a | The parameters coding the queries and date dimension data |
| process_mode | string | no | no | client_id | The identifier of the workspaces to load the date dimensions to Possible values:
The value of this parameter defines what columns you provide in your queries. |
| domain | string | see "Description" | no | n/a | The name of the domain where the workspaces belong to This parameter is mandatory only when |
| columns_to_delete | string | no | no | identifier | The columns that will be deleted from the table with date dimension data before the data is loaded to the date datasets If you want to provide more than one column name, separate them with a comma. If this parameter is not specified, only the Example: |
Data Warehouse-Specific Parameters
If your date dimension data is stored in the same data warehouse as the queries (such as Snowflake, Redshift, or BigQuery), provide the following parameters as schedule parameters (see Configure Schedule Parameters) to point to the table in the data warehouse where the date dimension data is stored.
Do not specify these parameters if the date dimension data is stored in an S3 bucket.
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| dd_table_name | string | yes | no | n/a | The name of the table in the data warehouse that holds the date dimension data |
| dd_filter_columns | string | no | no | n/a | The columns in the table that holds the date dimension data (see the If you want to provide more than one column name, separate them with a comma. Example: |
| dd_order_column | string | no | no | date.day.yyyy_mm_dd | The columns in the table that holds the date dimension data (see the dd_table_name parameter earlier in this table) by which the data in the table should be sorted |
Queries
The queries define the criteria for processing the date dimension data: where to read the date dimension data from and what workspaces to load it to.
Query Structure
You can specify the queries as a CSV file or a database table with the following columns:
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| dd_id | string | yes | n/a | The title of the date dataset in the workspace where the date dimension data will be loaded to |
| data_product_id | string | see "Description" | n/a | (Only when process_mode is set to
NOTE: If you use |
| client_id | string | see "Description" | n/a | |
| project_id | string | see "Description" | n/a | (Only when process_mode is set to NOTE: If you use |
| identifier | string | see "Description" | n/a | (Only when the date dimension data is stored in a table in a data warehouse) The identifier of the date dataset where the date dimension data will be loaded to NOTE: Specify the Do not specify both |
| file | string | see "Description" | n/a | (Only when the date dimension data is stored as a CSV file in an S3 bucket) The name of the CSV file in the S3 bucket that holds data to load to the date dataset One CSV file must contain data for one date dataset. NOTE: Specify the Do not specify both |
| x__timestamp | timestamp | no | n/a | (For incremental processing only) The timestamp when the last successful incremental load completed When Date Dimension Loader runs successfully, it stores to the workspace's metadata the greatest value in the The incremental processing works similarly to the incremental load mode with the |
Here is an example of the query that points to date dimension data stored in a table in a data warehouse (notice the identifier column) and use the combination of data product IDs and client IDs to specify the workspaces to load the date dimensions to (notice the data_product_id and client_id columns):
| dd_id | data_product_id | client_id | identifier | x__timestamp |
|---|---|---|---|---|
| createdate.dataset.dt | default | p3489 | createdate | 2021-11-03 10:22:34 |
| expiredate.dataset.dt | default | a9800 | expiredate | 2021-12-07 10:22:34 |
| updatedate.dataset.dt | testing | updatedate | 2021-12-07 10:22:34 |
Here is an example of the query that points to date dimension data stored as CSV files in an S3 bucket (notice the file column) and use workspace IDs to specify the workspaces to load the date dimensions to (notice the project_id column):
| dd_id | project_id | file | x__timestamp |
|---|---|---|---|
| createdate.dataset.dt | op8swkuuh6ccmh9paaynje4zdfu39u63 | createdate_data.csv | 2021-11-03 10:22:34 |
| expiredate.dataset.dt | op8swkuuh6ccmh9paaynje4zdfu39u63 | expiredate_data.csv | 2021-12-07 10:22:34 |
| updatedate.dataset.dt | ebyg33vqnls7kp13f1u0nkov2pxf8dbt | updatedate_data.csv | 2021-12-07 10:22:34 |
Query Source
Date Dimension Loader can read the queries from any supported data warehouse or an S3 bucket (see Types of Input Data Sources).
- If you want to store the queries in an S3 bucket, specify the queries in a CSV file.
- If you want to store the queries in a data warehouse, specify the queries as an SQL query to this data warehouse.
Example: The queries stored in an S3 bucket
{
"s3_client": {
"bucket": "date_dimensions",
"accessKey": "123456789",
"secretKey": "secret",
"region": "us-east-1",
"serverSideEncryption": "true"
},
"input_source": {
"type": "s3",
"file": "dd_query.csv”,
}
}
Example: The queries stored in ADS
{
"ads_client": {
"username": "john.doe@address.com",
"password": "secret",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"input_source": {
"type": "ads",
"query": "SELECT dd_id, data_product_id, client_id, identifier FROM dd_query_table"
}
}
In this example, the SQL query points to the ADS table that contains the data_product_id and client_id columns, which means that the combination of data product IDs and client IDs is used to specify the workspaces to load the date dimensions to (see Query Structure):
SELECT dd_id, data_product_id, client_id, identifier FROM dd_query_table
If you use workspace IDs to specify the workspaces, use the following SQL query instead (replace data_product_id and client_id with project_id):
SELECT dd_id, project_id, identifier FROM dd_query_table
Date Dimension Data
The date dimension data contains date-related calendar data. For more information about the date dimensions and their structure, see Manage Custom Date Dimensions.
Date Dimension Data Structure
You can specify the date dimension data as a CSV file or a database table. This file or table must have the mandatory date-related columns (for more information, see “Prepare a CSV File with Calendar Requirements” in Manage Custom Date Dimensions) and one additional column, identifier, that contains the identifier of the date dataset in the workspace where the data will be loaded to. The records with the same identifier in the identifier column are treated as belonging to the same date dataset.
The file or table can have more columns, if needed (for example, a column with notes).
The identifier column is automatically deleted before the date dimension data is loaded to the specified date datasets. If the file or table has other extra columns besides the identifier column (for example, a column with notes), use the columns_to_delete parameter (see General Parameters) and set it to delete the identifier column and all those extra column before loading the date dimension data.
Here is an example of the date dimension data:
| identifier | date.day.yyyy_mm_dd | date.day.uk.dd_mm_yyyy | date.day.us.mm_dd_yyyy | date.day.eu.dd_mm_yyyy | <other date related columns> |
|---|---|---|---|---|---|
| createdate | 1900-01-01 | 01/01/1900 | 01/01/1900 | 01-01-1900 | ... |
| createdate | 1900-01-02 | 02/01/1900 | 01/02/1900 | 02-01-1900 | ... |
| createdate | 1900-01-03 | 03/01/1900 | 01/03/1900 | 03-01-1900 | ... |
| expiredate | 1900-01-01 | 01/01/1900 | 01/01/1900 | 01-01-1900 | ... |
| expiredate | 1900-01-02 | 02/01/1900 | 01/02/1900 | 02-01-1900 | ... |
| expiredate | 1900-01-03 | 03/01/1900 | 01/03/1900 | 03-01-1900 | ... |
| updatedate | 1900-01-01 | 01/01/1900 | 01/01/1900 | 01-01-1900 | ... |
| updatedate | 1900-01-02 | 02/01/1900 | 01/02/1900 | 02-01-1900 | ... |
| updatedate | 1900-01-03 | 03/01/1900 | 01/03/1900 | 03-01-1900 | ... |
Date Dimension Data Source
Date Dimension Loader can read the date dimension data from any supported data warehouse or an S3 bucket (see Types of Input Data Sources).
- If you want to store the date dimension data in an S3 bucket, specify the date dimension data in a CSV file.
- If you want to store the date dimension data in a data warehouse, specify the date dimension data as an SQL query to this data warehouse.
How you specify the source of the date dimension data depends on the following:
- Whether the queries and the data dimension data are stored in the same source or two different sources
- Whether the source is a data warehouse or an object storage system
Not all combinations of the query source and data dimension data source are supported.
The following combinations of the sources are supported:
- The data dimension data and the queries are stored in the same data warehouse (for example, ADS or Snowflake).
- The data dimension data and the queries are stored in the same S3 bucket.
- The data dimension data is stored in an S3 bucket, and the queries are stored in a data warehouse (for example, ADS or Snowflake).
All the other combinations (for example, when the data dimension data and the queries are stored in two different data warehouses) are not supported.
The following are possible scenarios of how you can set up the source of the date dimension data:
The data dimension data and the queries are stored in the [same data warehouse]{.ul}. In this case, the source of the date dimension data is a table in the same data warehouse where the queries are stored. To point to this table, use the data warehouse-specific parameters in the Date Dimension Loader schedule. Date Dimension Loader will obtain the other necessary information about the data warehouse from the query source.
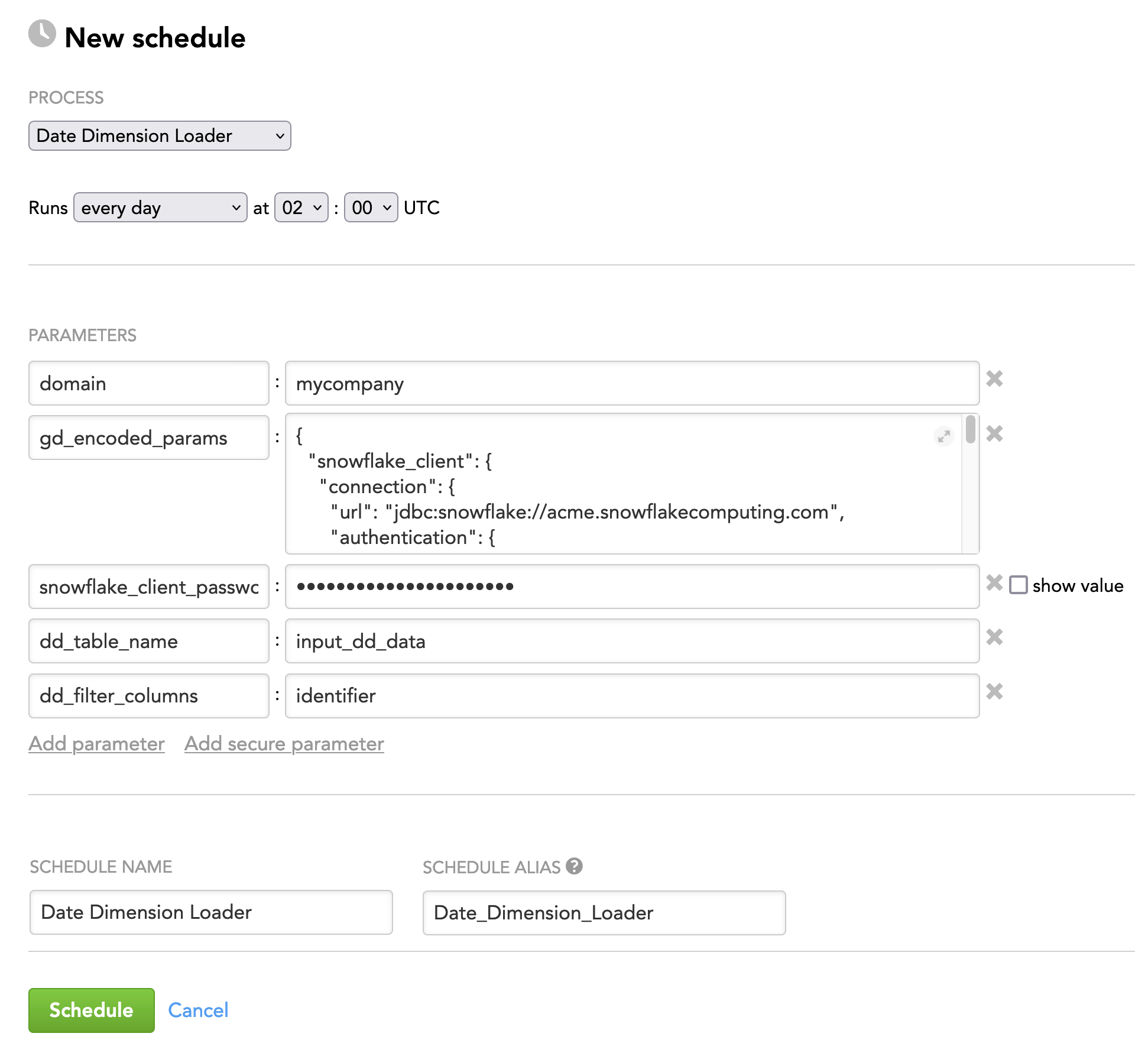
Example: The data dimension data and the queries are stored in ADS The source of the queries is specified by the following:
{ "ads_client": { "username": "john.doe@address.com", "password": "secret", "ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi" }, "input_source": { "type": "ads", "query": "SELECT dd_id, data_product_id, client_id, identifier FROM dd_query_table" } }The source of the date dimension data is specified by the following parameters in the schedule (see also Schedule Examples):
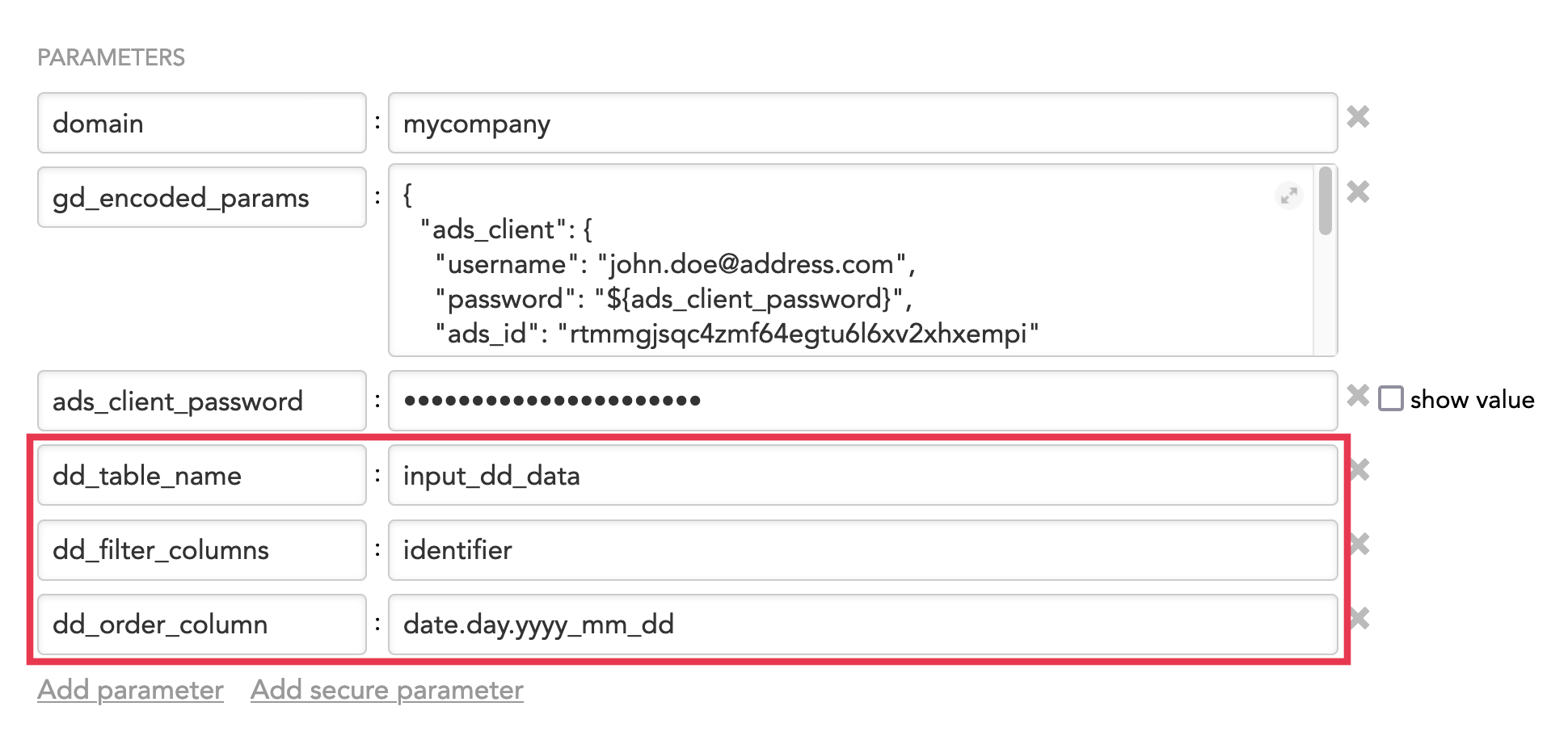
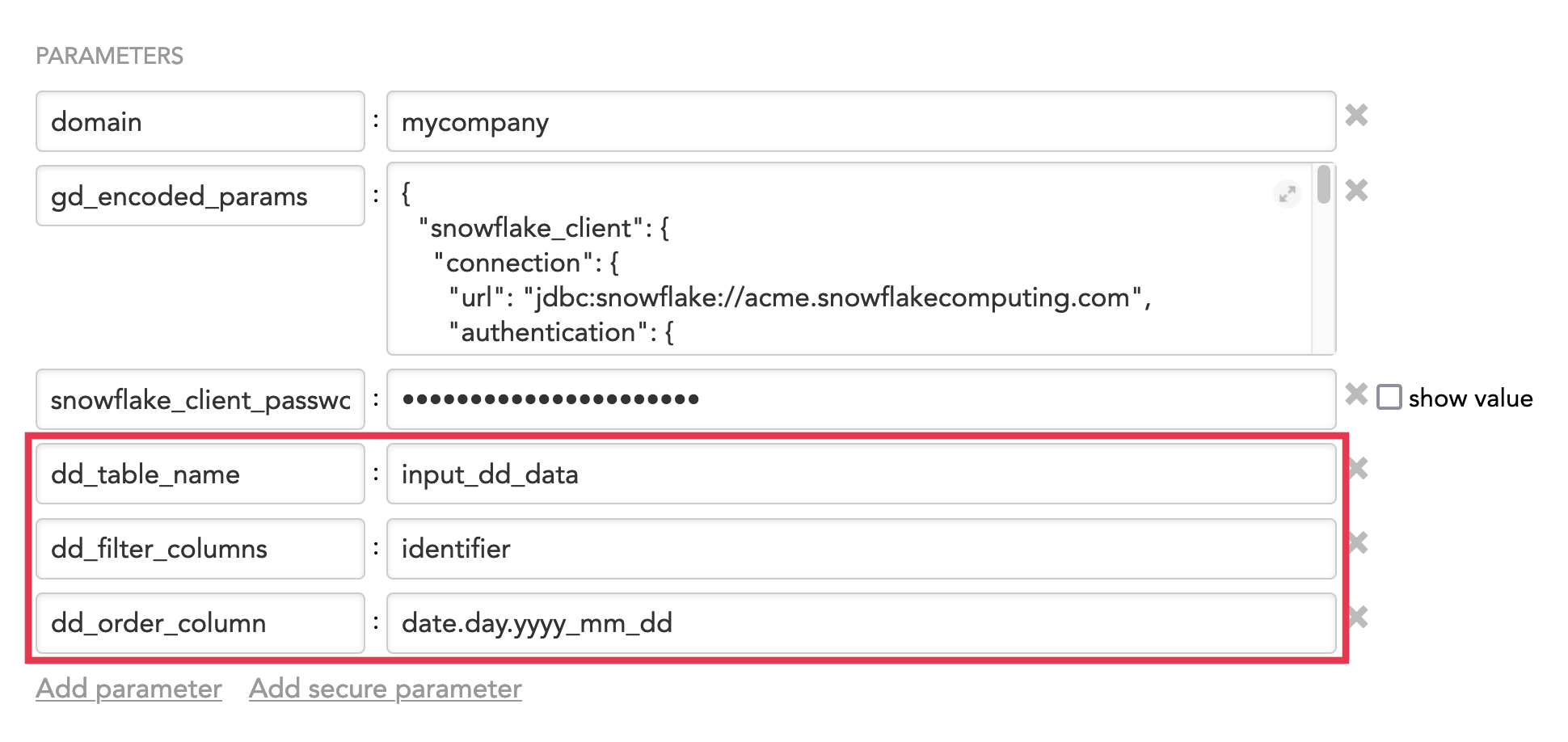
Example: The data dimension data and the queries are stored in Snowflake The source of the queries is specified by the following:
{ "snowflake_client": { "connection": { "url": "jdbc:snowflake://acme.snowflakecomputing.com", "authentication": { "basic": { "userName": "GOODDATA_INTEGRATION", "password": "secret" } }, "database": "ACME", "schema": "ANALYTICS", "warehouse": "GOODDATA_INTEGRATION" } }, "input_source": { "type": "snowflake", "query": "SELECT dd_id, data_product_id, client_id, identifier FROM dd_query_table" } }The source of the date dimension data is specified by the following parameters in the schedule (see also Schedule Examples):
The data dimension data and the queries are stored in the [same S3 bucket]{.ul}. In this case, the source of the date dimension data is a folder with one or more CSV files in the same S3 bucket where the queries are stored. To point to this folder, add the
folderparameter underinput_sourcein the query source, and set it to the path to the folder with the CSV files. Date Dimension Loader will obtain the other necessary information about the S3 bucket from the query source.{ "s3_client": { "bucket": "date_dimensions", "accessKey": "123456789", "secretKey": "${s3_secret_key}", "region": "us-east-1", "serverSideEncryption": "true" }, "input_source": { "type": "s3", "file": "input_dd_data/date_dimension_Params.csv”, "folder": "input_dd_data" } }The data dimension data is stored in an [S3 bucket]{.ul}, and the queries are stored in a [data warehouse]{.ul}. In this case, the date dimension data is stored in a folder with one or more CSV files in an S3 bucket, and the queries are stored in a table in a data warehouse. To point to the folder where the date dimension data is stored, add the input data source for the S3 bucket (see Types of Input Data Sources). In this source, replace
input_sourcewith thedata_input_source, then replace thefileparameter underdata_input_sourcewith thefolderparameter, and set it to the path to the folder with the CSV files.Example: The data dimension data is stored in an S3 bucket, and the queries are stored in ADS
{ "ads_client": { "username": "john.doe@address.com", "password": "secret", "ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi" }, "input_source": { "type": "ads", "query": "SELECT dd_id, data_product_id, client_id, file FROM dd_query_table" }, "s3_client": { "bucket": "date_dimensions", "accessKey": "123456789", "secretKey": "secret", "region": "us-east-1", "serverSideEncryption": "true" }, "data_input_source": { "type": "s3", "folder": "/input_dd_data/" } }Example: The data dimension data is stored in an S3 bucket, and the queries are stored in Snowflake
{ "snowflake_client": { "connection": { "url": "jdbc:snowflake://acme.snowflakecomputing.com", "authentication": { "basic": { "userName": "GOODDATA_INTEGRATION", "password": "secret" } }, "database": "ACME", "schema": "ANALYTICS", "warehouse": "GOODDATA_INTEGRATION" } }, "input_source": { "type": "snowflake", "query": "SELECT dd_id, data_product_id, client_id, file FROM dd_query_table" }, "s3_client": { "bucket": "date_dimensions", "accessKey": "123456789", "secretKey": "secret", "region": "us-east-1", "serverSideEncryption": "true" }, "data_input_source": { "type": "s3", "folder": "/input_dd_data/" } }
Queries and Data Dimension Data as Schedule Parameters
When providing the queries and date dimension data as schedule parameters, you have to code them using the gd_encoded_params parameter (see General Parameters).
To code the queries and date dimension data, follow the instructions in Specifying Complex Parameters. Once done, you should have the gd_encoded_params parameter coding the queries and reference parameters encoding sensitive information that you will be adding as secure parameters.
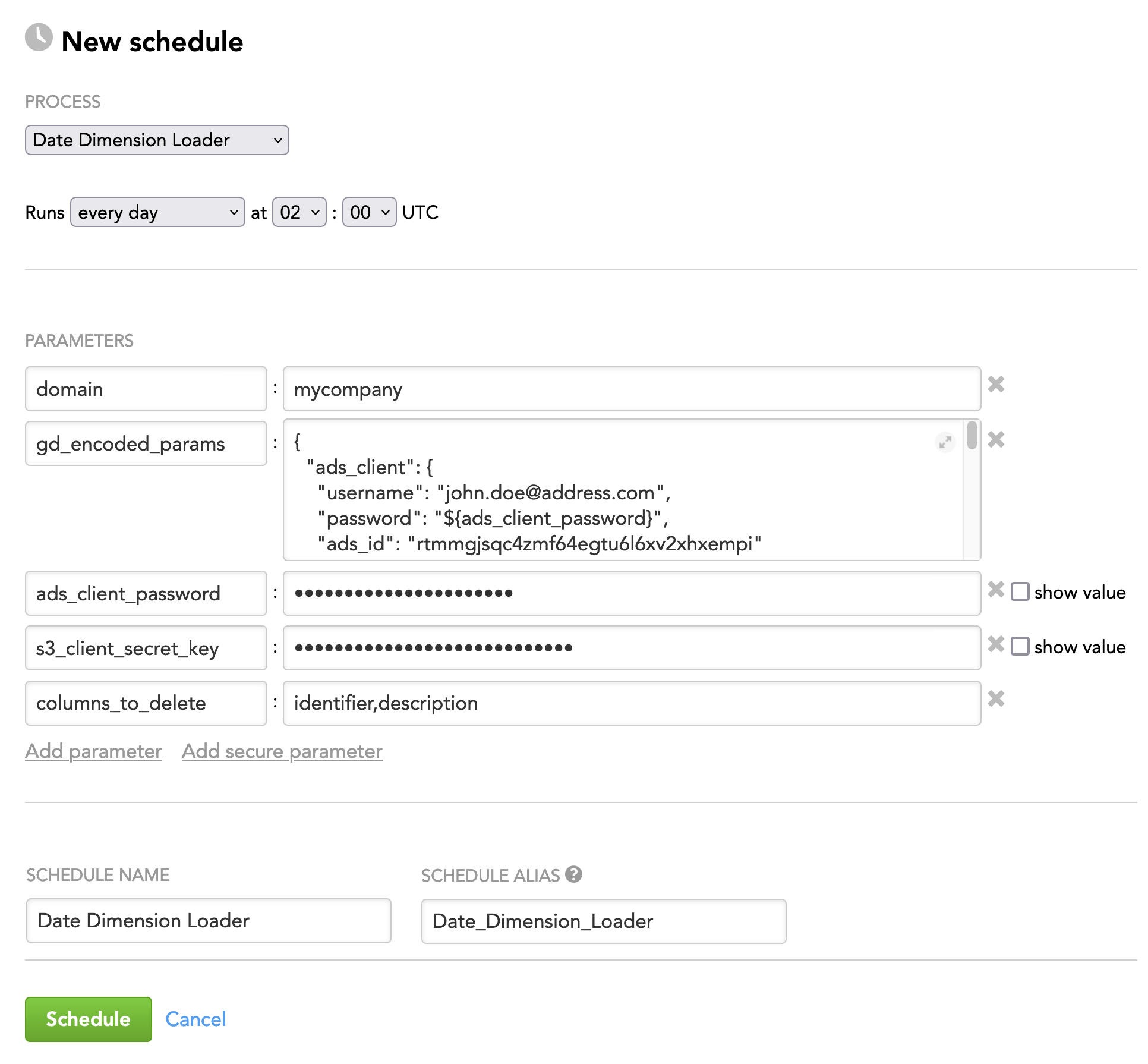
Example: The data dimension data is stored in an S3 bucket (sensitive information present: secret key), and the queries are stored in ADS (sensitive information present: ADS password) to be coded by the gd_encoded_params and reference parameters encoding the secret key and ADS password
The following will become the value of the gd_encoded_params parameter:
{
"ads_client": {
"username": "john.doe@address.com",
"password": "${ads_client_password}",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"input_source": {
"type": "ads",
"query": "SELECT dd_id, data_product_id, client_id, file FROM dd_query_table"
},
"s3_client": {
"bucket": "date_dimensions",
"accessKey": "123456789",
"secretKey": "${s3_client_secret_key}",
"region": "us-east-1",
"serverSideEncryption": "true"
},
"data_input_source": {
"type": "s3",
"folder": "/input_dd_data/"
}
}
In addition, you have to add the reference parameters ads_client_password and s3_client_secret_key as secure parameters.
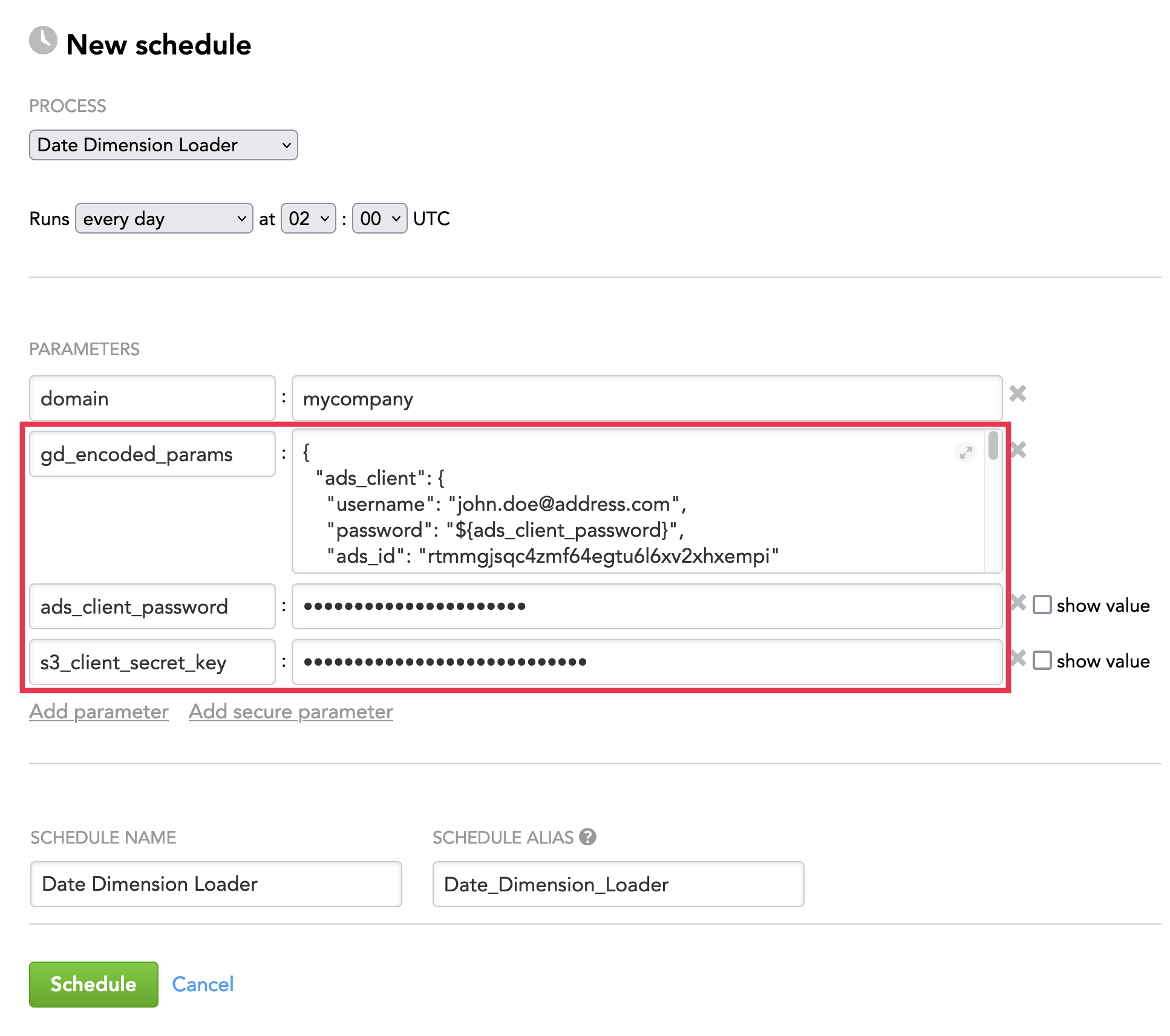
Schedule Examples
Example 1: The data dimension data is stored in an S3 bucket, and the queries are stored in ADS.
Example 2: The data dimension data and the queries are stored in Snowflake.