Custom Field Creator
Creating custom fields in the logical data model (LDM) as a feature and Custom Field Creator in particular are supported only for workspaces where data is loaded from the GoodData Data Warehouse (ADS) using Automated Data Distribution (ADD; see Data Preparation and Distribution Pipeline). You cannot use custom fields in workspaces that load data from any other data warehouse or object storage service.
Custom Field Creator is a utility that supports the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). Custom Field Creator creates additional fields (facts, attributes, or dates) in the logical data model (LDM) of one or more workspaces based on the criteria that you have defined (what fields to create and in what workspaces to do so).
This is a reference article for Custom Field Creator. For the article with a complete process of adding custom fields, see Add Custom Fields to the LDMs in Client Workspaces within the Same Segment.
How Custom Field Creator Works
When Custom Field Creator runs, it creates custom fields in the workspaces according to the criteria that you have defined in queries:
- The types of the custom fields to create (fact, attribute, or date)
- The properties of the custom fields (name, datatype, and so on)
- The workspace where to create the fields in
- The dataset in the LDM where each field should be created
Custom Field Creator does not modify or delete any fields from the LDM.
If you use Schedule Executor to run schedules, use it with the dataload_parameters_query parameter to run schedules for the workspaces where the LDM contains datasets with custom fields. For more information, see Schedule Executor and Add Custom Fields to the LDMs in Client Workspaces within the Same Segment.
Configuration File
Custom Field Creator does not require any parameters in the configuration file.
Schedule Parameters
When scheduling Custom Field Creator (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
| Name | Type | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| create_mode | string | yes | no | n/a | The identifier of the workspaces where custom fields to create belong to Possible values:
The value of this parameter defines what you provide in the |
| domain_name | string | see "Description" | no | n/a | The name of the domain where the workspaces belong to This parameter is mandatory only when |
| gd_encoded_params | JSON | yes | no | n/a | The parameters coding the queries |
| dry_run | Boolean | no | no | false | Specifies whether Custom Field Creator should only generate a log with the custom fields that will be created instead of actual creating of the custom fields.
|
| dont_fail_on_error | Boolean | no | no | false | Specifies whether Custom Field Creator fails when an error occurs.
Regardless of what this parameter is set to, all errors are recorded to the log where you can review it later. |
| number_of_threads | integer | no | no | 4 | The number of threads that will be used for creating the custom fields |
Queries
The queries define the criteria for processing the custom fields: what fields to create and in what workspaces to do so.
Query Structure
You can specify the queries in a GoodData Data Warehouse (ADS) table with the following columns:
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| source_identifier | string | yes | n/a | The identifier of the workspace where custom fields to create belong to What you provide in this column depends on the value of the
|
| dataset | string | yes | n/a | The identifier of the dataset where the custom fields should be created Example: |
| cf_identifier | string | yes | n/a | The identifier of the custom field Example: NOTE: We recommend that you use the |
| cf_type | string | yes | n/a | The type of the custom field Possible values:
|
| cf_title | string | yes | n/a | The title of the custom field as it will be visible to the end user Example: |
| cf_datatype | string | no |
| The datatype of the custom field NOTE: Do not specify the datatype for date custom fields. |
| cf_folder_title | string | no | n/a | The title of the folder where the custom field should be created If the folder does not exist, it will be created. You can see the folders on the Manage page, under the Data tab, for attributes and facts correspondingly. By default, if the folder is not specified, the custom field is created outside of any folder. NOTE: Do not specify the folder for date custom fields. |
| data_product | string | no | default | (Only when you use client IDs in source_identifier) The data product that each workspace belongs to |
| x__timestamp | timestamp | no | n/a | (For incremental processing only) The timestamp when the last successful incremental load completed When Custom Field Creator runs successfully, it stores to the workspace's metadata the greatest value in the The incremental processing works similarly to the incremental load mode with the TIP: Consider using the |
Here is an example of the query table where workspace IDs are used to identify the workspaces:
| source_identifier | dataset | cf_identifier | cf_type | cf_datatype | cf_title | cf_folder_title | x__timestamp |
|---|---|---|---|---|---|---|---|
| e863ii0azrnng2zt4fuu81ifgqtyeoj21 | dataset.employee | attr.employee.cf_address | attribute | VARCHAR(128) | Address | Employee | 2021-01-22 10:22:34 |
| e863ii0azrnng2zt4fuu81ifgqtyeoj21 | dataset.employee | fact.sale.cf_sum | fact | DECIMAL(12,2) | Sales Sum | Sales | 2021-01-22 3:15:40 |
| fuu81ifgqtyeoj21e863ii0azrnng2zt4 | dataset.employee | employeebirthday.dataset.dt | date | Employee Birthday | 2021-01-22 6:26:41 |
Here is an example of the query file where client IDs are used to identify the workspaces and the data product is specified for each workspace:
| source_identifier | dataset | cf_identifier | cf_type | cf_datatype | cf_title | cf_folder_title | data_product | x__timestamp |
|---|---|---|---|---|---|---|---|---|
| p3489 | dataset.employee | attr.employee.cf_address | attribute | VARCHAR(128) | Address | Employee | default | 2021-01-22 10:22:34 |
| a9800 | dataset.employee | fact.sale.cf_sum | fact | DECIMAL(12,2) | Sales Sum | Sales | testing | 2021-01-22 3:15:40 |
| m4801 | dataset.employee | employeebirthday.dataset.dt | date | Employee Birthday | default | 2021-01-22 6:26:41 |
Query Source
Custom Field Creator reads the queries from ADS. Specify the query as an SQL query to ADS.
{
"ads_client": {
"username": "john.doe@example.com",
"password": "secret",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"input_source": {
"type": "ads",
"query": "SELECT source_identifier, dataset, cf_identifier, cf_type, cf_datatype, cf_title, cf_folder_title, x__timestamp FROM custom_fields_input"
}
}
Queries as Schedule Parameters
When providing the queries as schedule parameters, you have to code them using the gd_encoded_params parameter (see General Parameters).
To code the queries, follow the instructions in Specifying Complex Parameters. Once done, you should have the gd_encoded_params parameter coding the queries and reference parameters encoding sensitive information that you will be adding as secure parameters.
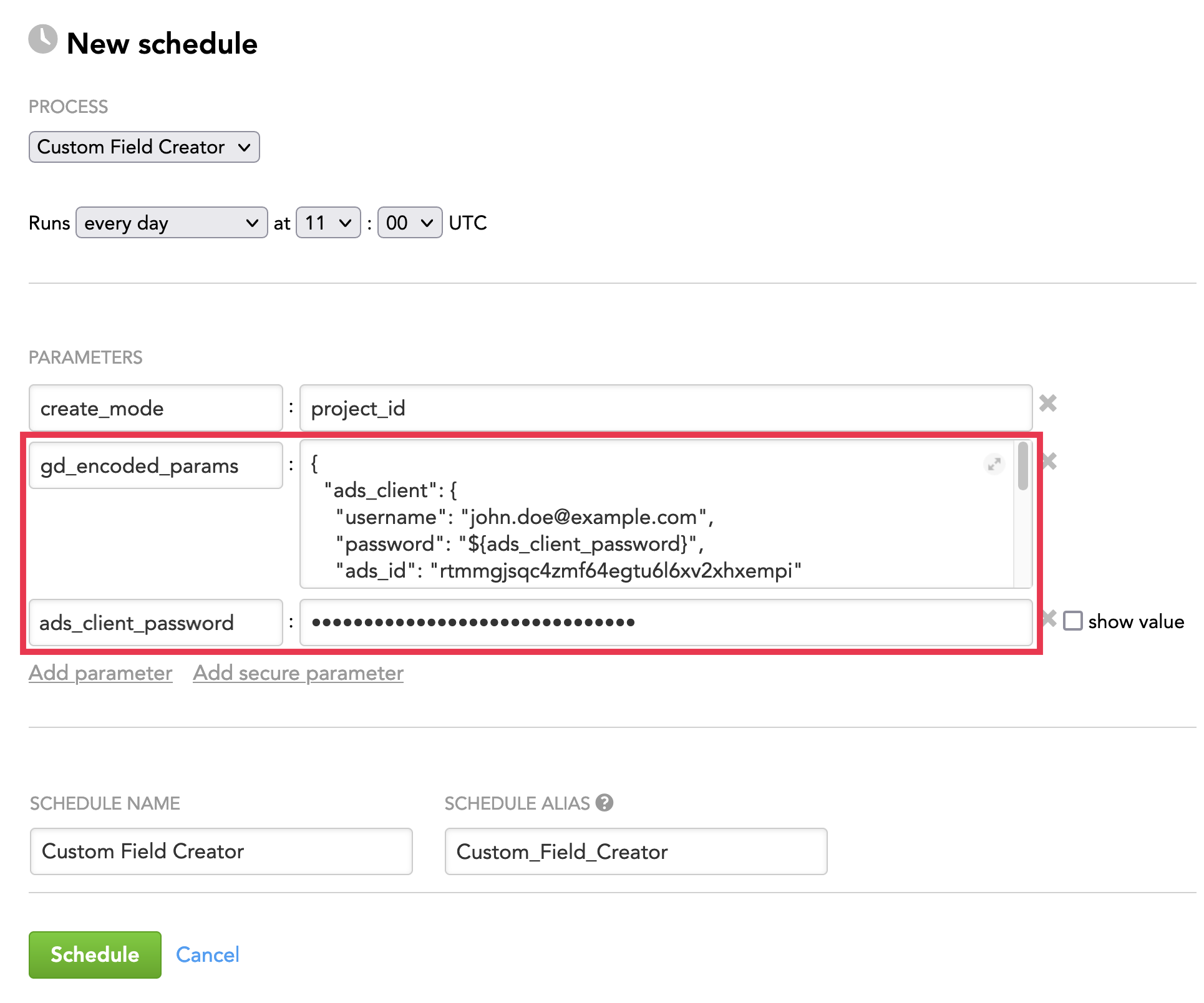
Example: The queries obtained from ADS (sensitive information present: ADS password) to be coded by the gd_encoded_params and a reference parameter encoding the ADS password
The following will become the value of the gd_encoded_params parameter:
{
"ads_client": {
"username": "john.doe@example.com",
"password": "${ads_client_password}",
"ads_id": "rtmmgjsqc4zmf64egtu6l6xv2xhxempi"
},
"input_source": {
"type": "ads",
"query": "SELECT source_identifier, dataset, cf_identifier, cf_type, cf_datatype, cf_title, cf_folder_title, x__timestamp FROM custom_fields_input"
}
}
In addition, you have to add the reference parameter ads_client_password as a secure parameter.
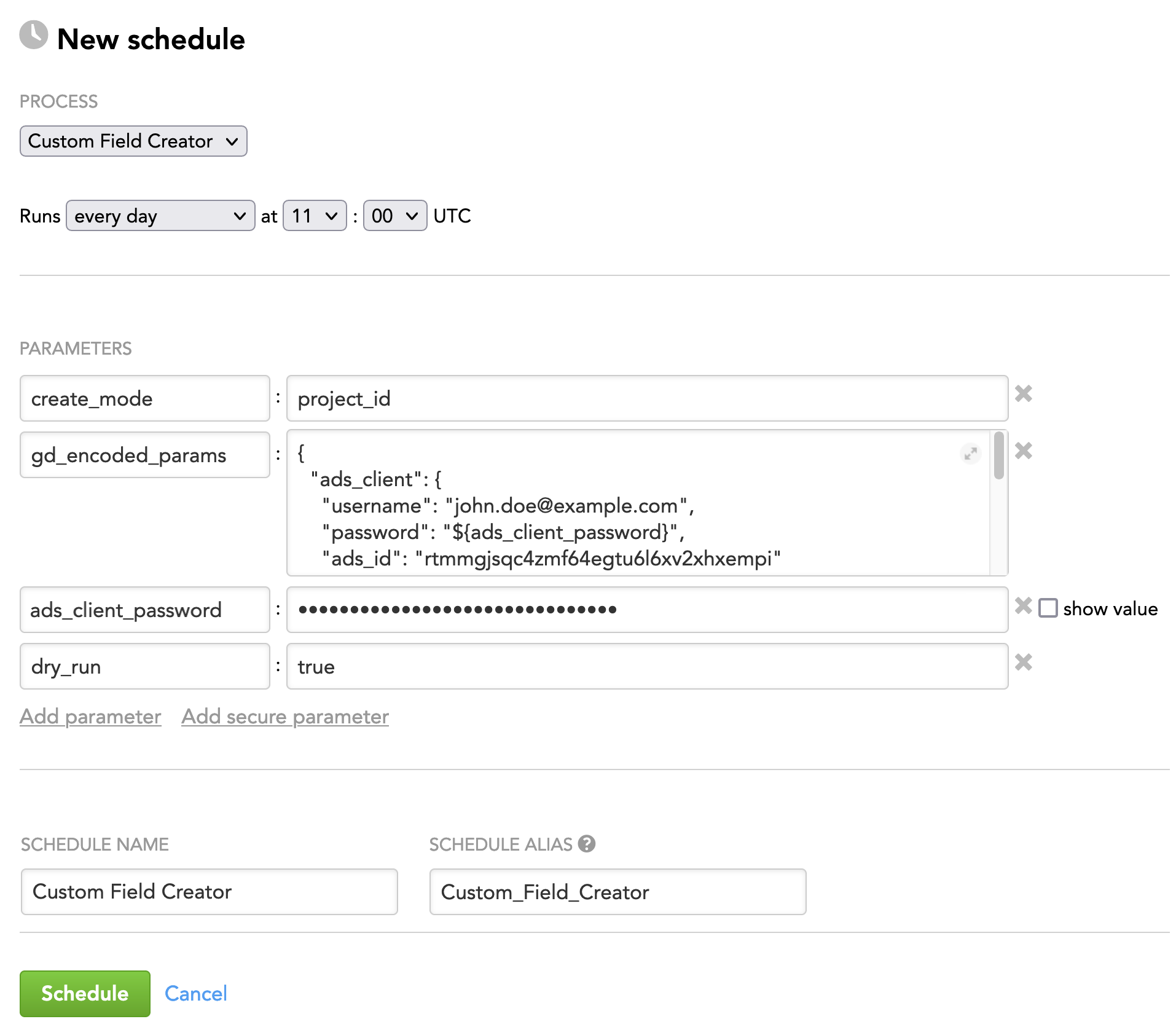
Schedule Example
The following is an example of how you can specify schedule parameters:
Logs and Error Handling
Custom Field Creator generates a log with all the changes made and errors occurred.
- If processing for one workspace fails, Custom Field Creator logs an error and continues the execution as usual.
- An execution with some workspaces processed and some failed finishes with a state of “Warning”.
- An execution with all workspaces failed finishes with a state of “Failed”.
By default, Custom Field Creator fails when an error occurs. You can change this behavior by setting the dont_fail_on_error parameter to true (see General Parameters).
Best Practices
- If you have a lot of client workspaces, consider using the
x__timestampcolumn (see Query Structure), and run Custom Field Creator in incremental processing mode to reduce its run time during repeated executions. - Run Custom Field Creator in the following cases:
- After you have defined new custom fields to make sure that they will be added to the existing client workspaces.
- After you have created new client workspaces (see Provisioning Brick) to make sure that the custom fields are added to those newly created workspaces.