Salesforce Downloader
Salesforce Downloader is a component of the data preparation and distribution pipeline (see Data Preparation and Distribution Pipeline). Salesforce Downloader downloads data from the Salesforce API.
Configuration File
Creating and setting up the brick’s configuration file is the third phase of building your data pipeline. For more information, see Phases of Building the Data Pipeline.
For more information about configuring a brick, see Configure a Brick.
Minimum Layout of the Configuration File
The following JSON sample is the minimum layout of the configuration file that Salesforce Downloader can use. If you are using more bricks, you can reuse some sections of this configuration file for other bricks. For example, the ‘downloaders’ section can list more downloaders, and the ‘integrators’ and ‘ads_storage’ sections can be reused by other downloaders and executors (see Configure a Brick).
This sample describes the use case of one instance of Salesforce Downloader that downloads two Salesforce entities.
Copy the sample and replace the placeholders with your values.
You can later enrich the sample with more parameters depending on your business and technical requirements (see Customize the Configuration File).
The salesforce Bulk API can’t access or query compound field types such as compound address or compound geolocation fields. If you specify a compound field type in your JSON, the request will fail.
{
"entities": {
"table_1_name": {
"global": {
"custom": {
"hub": ["column_1_name","column_2_name","column_3_name"],
"timestamp": "field_name"
}
}
},
"table_2_name": {
"global": {
"custom": {
"hub": ["column_1_name","column_2_name","column_3_name"],
"timestamp": "field_name"
}
}
}
},
"downloaders": {
"sf_downloader_id": {
"type": "sfdc",
"entities": ["table_1_name","table_2_name"]
}
},
"sfdc": {
"username": "salesforce_user_name",
"token": "salesforce_token",
"client_id": "salesforce_client_id"
},
"integrators": {
"ads_integrator_id": {
"type": "ads_storage"
}
},
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {}
}
}
The placeholders to replace with your values:
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| entities -> table_x_name | string | yes | n/a | The database tables into which Salesforce Downloader downloads the data |
| entities -> table_x_name -> global -> custom -> hub | array | yes | n/a | The table columns to generate a primary key |
| entities -> table_x_name -> global -> custom -> timestamp | string | yes | n/a | The name of the field that will be used as a timestamp for incremental downloads from the database NOTE: The referenced field must contain a date. |
| downloaders -> sf_downloader_id | string | yes | n/a | The ID of the Salesforce Downloader instance Example: sf_downloader_1 |
| downloaders -> sf_downloader_id -> entities | array | yes | n/a | The database tables into which Salesforce Downloader downloads the data Must be the same as the database table names in 'entities -> table_x_name' |
| sfdc -> username | string | yes | n/a | The username for the Salesforce account |
| sfdc -> token | string | yes | n/a | The token for the Salesforce account |
| sfdc -> client_id | string | yes | n/a | The client ID for the Salesforce connected app. For more information about creating a connected app, see https://help.salesforce.com/articleView?id=connected_app_create.htm&type=5. NOTE: The app must have access to the client's data. |
| integrators -> ads_integrator_id | string | yes | n/a | The ID of the ADS Integrator instance Example: ads_integrator_1 |
| ads_storage -> instance_id | string | yes | n/a | The ID of the Agile Data Warehousing Service (ADS) instance into which the data is uploaded |
ads_storage -> username | string | yes | n/a | The access username to the Agile Data Warehousing Service (ADS) instance into which the data is uploaded |
Customize the Configuration File
You can change default values of the parameters and set up additional parameters.
Specify additional load options for a Salesforce Downloader instance
You can set up additional load options for a Salesforce Downloader instance that would apply to all the entities that this instance processes.
"sfdc": {
"username": "salesforce_user_name",
"token": "salesforce_token",
"client_id": "salesforce_client_id",
"client_logger": true|false, // optional
"downcase_fields": true|false, // optional
"boolean_as_string": true|false, // optional
"default_start_date": "YYYY-MM-DD'T'HH:MM:SSS.SSS'Z", // optional
"full": true|false, // optional
"step_size": number_of_days // optional
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| client_logger | Boolean | no | false | Specifies whether additional logging is enabled
|
| downcase_fields | Boolean | no | false | Specifies whether to change the case of the field names
|
| boolean_as_string | Boolean | no | false | Specifies whether to convert Boolean values into strings
|
| default_start_date | string | no | 2015-01-01T00:00:00.000Z | The date that is used as follows depending on load mode:
|
| full | Boolean | no | false | Specifies load mode used for loading data to the database
The data is always downloaded starting from the date specified in the 'default_start_date' parameter. The 'timestamp' parameter in the 'entities' section is used for partitioning data downloaded via the Salesforce bulk API. |
| step_size | integer | no | n/a | The maximum number of days for which the data can be downloaded The next load will continue from where the last one ended. |
Specify additional load options for the entities
For each entity, you can set up additional load options.
"entities": {
"table_1_name": {
"global": {
"custom": {
"hub": ["column_1_name","column_2_name","column_3_name"],
"timestamp": "field_name",
"ignored_fields": ["field_1_name","field_2_name"], // optional
"deleted_records": true|false, // optional
"full": true|false, // optional
"fields_to_override": [ // optional
{
"name": "field_1_name",
"type": "field_1_type"
},
{
"name": "field_2_name",
"type": "field_2_type"
}
],
"fields_to_clean": ["field_1_name","field_2_name"], // optional
"functions": { // optional
"function_name": [
"field_1_name","field_2_name"
]
}
}
}
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| ignored_fields | array | no | [ ] (empty array, as in: | The fields that should be ignored when downloading data from the API |
| deleted_records | Boolean | no | false | Specifies how to handle the deleted records
|
| full | Boolean | no | false | Specifies load mode used for loading data to the database
|
| fields_to_override | array | no | [ ] (empty array, as in: | Changes the type of the listed fields to the type that you defined Example: |
| fields_to_clean | array | no | [ ] (empty array, as in: | The fields containing scientific notation that have to be converted to decimal notation to avoid potential processing issues Example: |
| functions | JSON | no | { } (empty hash, as in: | Custom functions to be applied to the listed fields after the download completes Example: |
Customize Salesforce-related settings
Depending on your business and technical requirements, you can set one or more optional parameters affecting Salesforce settings.
"sfdc": {
"username": "salesforce_user_name",
"token": "salesforce_token",
"client_id": "salesforce_client_id",
"host": "salesforce_endpoint", // optional
"api_version": "version_number", // optional
"bulk_query_options": { // optional
"option_1_name": "option_1_value",
"option_2_name": "option_2_value"
}
}
| Name | Type | Mandatory? | Default | Description |
|---|---|---|---|---|
| host | string | no | n/a | The Salesforce endpoint that Salesforce Downloader should access Example: test.salesforce.com |
| api_version | string | no | 53.0 | The version of the Salesforce API |
| bulk_query_options | JSON | no | { } (empty hash, as in: | The options to be propagated to the query via the Salesforce bulk Query gem that Salesforce Downloader is using. For more information about the Salesforce bulk Query gem, see https://github.com/gooddata/salesforce_bulk_query. Example: |
Add multiple instances of Salesforce Downloader
When you use only one instance of Salesforce Downloader, it reads its remote location parameters from the ‘sfdc’ section.
If you use multiple instances of Salesforce Downloader and each instance has a separate location to download data from, add several ‘sfdc’ sections and give each section a unique name (for example, ‘sfdc_users’ or ‘sfdc_sales’).
"sfdc_users": {
"username": "salesforce_user_1_name",
"token": "salesforce_token_1",
"client_id": "salesforce_client_1_id"
},
"sfdc_sales": {
"username": "salesforce_user_2_name",
"token": "salesforce_token_2",
"client_id": "salesforce_client_2_id"
}
For each instance of Salesforce Downloader in the ‘downloaders’ section, add the ‘settings’ parameter and set it to the name of the section that contains settings for this Salesforce Downloader instance.
"downloaders": {
"sf_downloader_1_id": {
"type": "sfdc",
"settings": "sfdc_users",
"entities": ["table_1_name","table_2_name"]
},
"sf_downloader_2_id": {
"type": "sfdc",
"settings": "sfdc_sales",
"entities": ["table_1_name","table_2_name"]
}
}
Customize integrators
The ‘integrators’ and ‘ads_storage’ sections define the behavior of integrators.
"integrators": {
"ads_integrator_id": {
"type": "ads_storage"
}
},
"ads_storage": {
"instance_id": "data_warehouse_instance_id",
"username": "dw_email@address.com",
"options": {}
}
If you want to add more parameters or change the defaults, see ADS Integrator.
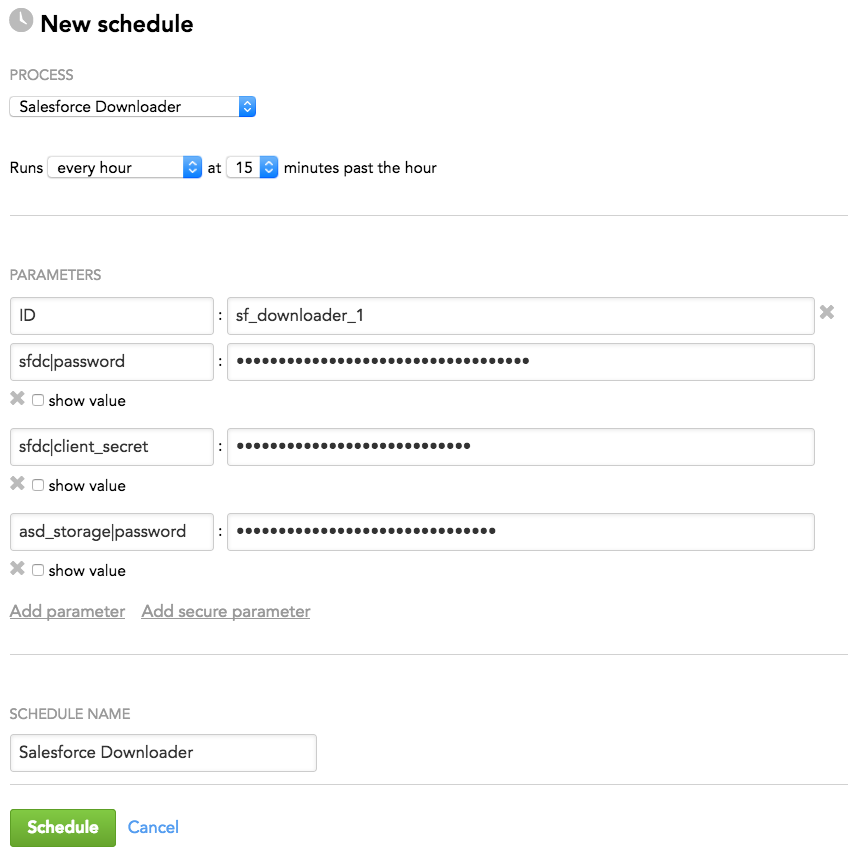
Schedule Parameters
When scheduling Salesforce Downloader (see Phases of Building the Data Pipeline -> Production Implementation), provide the parameters from this section in the schedule.
General Parameters
Some parameters must be entered as secure parameters (see Configure Schedule Parameters).
Some parameters contain the names of the nesting parameters, which specifies where they belong in the configuration hierarchy. For example, a parameter entered as sfdc|options|password is resolved as the following:
"sfdc": {
"options": {
"password": ""
}
}
Enter such parameters as is (see Schedule Example).
| Name | Typ | Mandatory? | Secure? | Default | Description |
|---|---|---|---|---|---|
| ID | string | yes | no | n/a | The ID of the Salesforce Downloader instance being scheduled Must be the same as the 'downloaders -> sf_downloader_id' parameter in the configuration file (see Minimum Layout of the Configuration File) Example: sf_downloader_1 |
| sfdc|password | string | yes | yes | n/a | The password for the Salesforce account |
| sfdc|client_secret | string | yes | yes | n/a | The client secret for the Salesforce connected app |
| ads_storage|password | string | yes | yes | n/a | The password to access the ADS instance to upload the data to |
Schedule Example
The following is an example of how you can specify schedule parameters: