Incremental Data Loading
GoodData now supports incremental load via the Automated Data Distribution (ADD) feature. Using ADD, you can choose between full and incremental load modes.
Ideally, each execution of an ETL process would result in a full load of a dataset with data that has been gathered and processed from the source system. In this ideal structure, the data in your GoodData project corresponds to the data in the source system, factoring in any transformations applied to it by the ETL process. If oddities or bad data are detected in the project, you simply re-run your full data load ETL process to renew the contents of your project.
However, full data loads may not always be possible for the following reasons:
- For very large datasets, a full load may not be 1) possible to query from the source system or 2) loadable within a reasonable timeframe into the GoodData project.
- Since the full data load removes all content from the project, the period of available data in the GoodData project cannot differ from the date ranges available in the source system.
By default, ETL graphs are designed to use the full data loading method of refreshing the target dataset in your GoodData project. However, in situations such as the above, you can modify the ETL graph to perform incremental data loads. An incremental data load is a method of updating the dataset in which only new or modified records are uploaded to the project. If the target record is modified in the incoming data or if there is no target record, the incoming data is written to the project.
Records cannot be removed through incremental data loading methods. If you perform a full data load, any records that were in the dataset and are absent in the new data no longer appear in the updated dataset. For more information on methods of removing data from your datasets, see Deleting Data from Project.
Overview
In an incremental data loading scenario, the incoming data is compared to the existing data in the dataset via a connection point. In GoodData, a connection point is a column in the dataset that has been identified as containing unique values for each record in the dataset. It functions similarly to a primary key in a database table.
So, using the defined connection point in the dataset to match incoming records to existing records, the loading processes within the GoodData platform can determine if the incoming records need to 1) modify existing records or 2) append new records to the dataset. For modified records, any updated values are written into the specific fields of the record.
Each value in the connection point field must be unique within the dataset records. When you have three rows with the same connection point value, only the record that was uploaded last is in your data, replacing the other two rows with the same value that was uploaded before the last record.
Additional Considerations
Change How Data Is Queried
Keep in mind that if you are changing to an incremental data loading method, then you may be required to change how you acquire data from your source system. For example, if the source system is pulling data for full loads, you may need to change either 1) how data is queried from the source system in your ETL graph or 2) how the data is provided from the source system to your ETL staging area.
As part of any change to an incremental data loading method, you should review the entire ETL graph to verify that all steps of the process support an incremental loading method. The way in which data is read is particularly important, as you may create duplicated data if your ETL graph is set to incremental and you forget to change the extract step to grab only incremental data.
Multiple ETL Graphs
In some scenarios, you may find it useful to maintain multiple ETL graphs. For example, you may decide that it is most efficient to perform regular incremental data loads to refresh the data and to periodically do a full data load during off-peak hours to completely refresh the dataset.
In these scenarios, you may decide that the easiest method is to maintain separate ETL graphs and publish to separate processes.
Connection Points
In order to implement incremental data loading, you must define a connection point in your logical data model.
Configuration through CloudConnect
Setting up the Connection Point through LDM Modeler
Through the LDM Modeler in CloudConnect Designer, you can define a connection point for a dataset very easily.
Steps:
Open CloudConnect Designer.
Open the project containing the dataset you wish to configure for incremental data loading.
Select the dataset.
Click the Edit link. The Attributes and Facts window opens.
In the above example, the Payments dataset does not contain a connection point.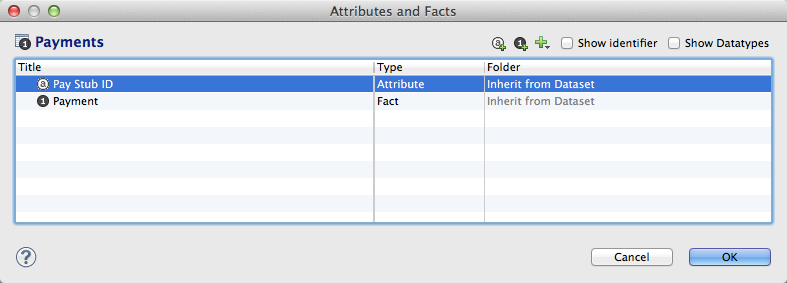
To add a connection point, click the Type column of the field that you wish to make a connection point.
In most cases, the connection point is defined on an attribute.Click the Browse… button. In the Select Type window, click the Connection Point radio button.
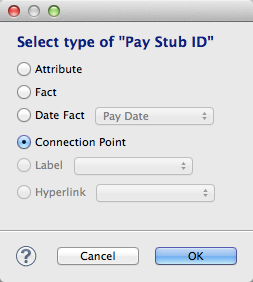
Click OK. The field is now defined as a connection point.
Click OK again. Save the file.
Publish the model to the server.
Define Mode in GD Dataset Writer
You must also configure the mode in the GD Dataset Writer component of your ETL graph to write incremental data. This component writes data into the GoodData project that you designate.
Steps:
- In CloudConnect Designer, open the ETL graph you wish to configure for incremental data loading.
- Double-click the GD Dataset Writer component. The GD Dataset Writer configuration is displayed.
- Click the Mode setting:
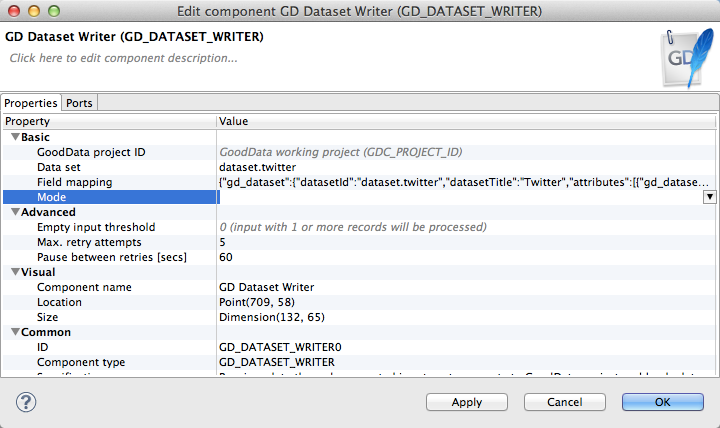
- From the drop-down, select Incremental (append data from input).
- Click OK.
- Save the graph file.
Change the Input
Before you test the graph, you should verify that the input to the graph is set to query the source for incremental data, instead of full data loads.
Testing
This configuration should be tested. You may wish to test by using a dummy data file. During testing, you should test the following:
- Append - adding new records
- Update - modifying existing records
You might create a test set of records in a flat file, change the ETL to read from this file, and then upload them. Then, you could make modifications to fields in the records, except for the connection point field. When you re-execute the graph using this test file, the existing test records should be modified accordingly.
Incremental Data Loading Example: Loading Data for the Last Three Days
Suppose you need to upload data from three days back until today, and you must execute this load every day. So, every day you use incremental data loading to include the last three days.
If some data already exists (has the same connection point value), the incoming data replaces it with the new values. If the records you are uploading are completely new, the script appends them.
If the data load fails on any given day, the records are added the next day. However, if data load fails three days in a row, then the data is missing from the application.