CloudConnect - Working with Databases
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
When it comes to datasources that users of CloudConnect need to work with to process their data, relational databases are definitely among the most popular (other being flat or structured files and APIs which we’re covering in other articles). Therefore, being able to query database resources is one of the essential skills for CloudConnect user.
Using database as a source system brings several pros and cons when compared to other sources:
Pros
- Referential integrity is usually enforced
- Simple editing/updating of SQL queries
- Allows taking part of the logic out of the graph and using SQL
Cons
- Possible connection / rights issues
Our longtime experience shows that it is often better to avoid the initial advantage given by ability to quickly write SQL queries and go with API or flat file exports instead. If neither is possible, my recommendation is to at least prepare a set of VIEW statements as the datasource - they’re a friendly reminder of specific usage to particular tables when updates to DB are done. Anyway, you need to be always prepared that a datatype might be changed or a column might be dropped and your ETL process will suddenly fail if you’re running it against a database owned and administered by someone else. I’m in no way trying to convince you to avoid databases entirely, but I believe some of the possible issues mentioned above should be considered when designing the ETL process. However, if you are the unlimited ruler of the datasource (the database in our case), you’re probably fine to go.
Connections
Since your data is already in the database, you can utilise the performance of the DB server to perform part of the transformation for you. However, certain operations such as joins or complex subqueries might impose a significant load on the server and decrease its performance - keep that in mind when working with the productional system.
To be able to connect to external DB source, it’s necessary to create a so-called connection in the graph you’re working with. It’s one of the graph elements available in the outline, which is located in the lower left corner of screen if you stick with default working perspective.
CloudConnect Designer does not support the use of custom JDBC drivers. Please use one of the provided drivers.
CloudConnect Designer does not support the use of custom JDBC drivers. Please use one of the provided drivers.
For more information, see CloudConnect documentation on DB Connections.
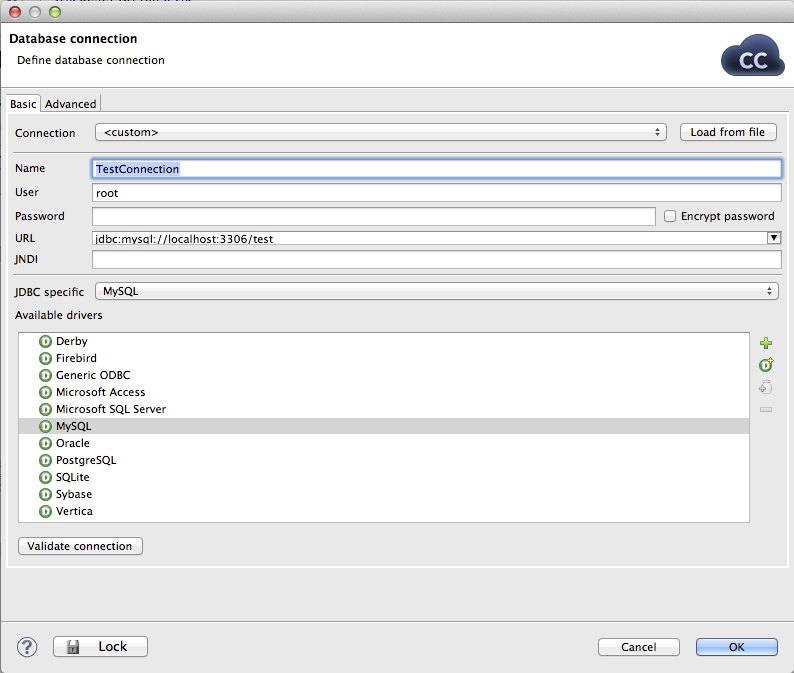
| Parameter name | Description |
|---|---|
| Name | Connection name |
| User | DB Username |
| Password | DB Password |
| URL | JDBC driver compatible URL |
CloudConnect contains JDBC drivers for many popular DB systems, including:
- Derby
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
- Vertica
Metadata Extraction
You might add specific JDBC driver by clicking the plus sign in the Connection Wizard. However, such driver will work only when your process is run locally. Please contact us if you feel some driver is missing from the default list.
ExtractMDThe moment when you can congratulate yourself for having your data in DB is when it comes to creating metadata. As it’s possible to map the DB metadata to metadata definition in CloudConnect, you can save yourself quite a lot of work (imagine your dataset is 50+ columns wide). To access this feature, simply pick New metadata -> Extract from the database (this can be done both on any edge as well as in the Outline).
Creating DB Table
The opposite of above is also possible - if you have your data created manually or extracted from a flat file, you can use them to create a new table in your DB. To do so, you need to right-click the metadata record you want to use and click Create database table. The following wizard is then displayed where you can finalise the CREATE TABLE query.
SSH Tunnelling
In many situations, the direct DB connection is not possible, usually for security reasons (DB port would have to accept external connections, which is generally considered risky). As a workaround, you might want to create SSH tunnel to connect to your DB server and forward one of your local ports. An example of MySQL connection would look like this:
ssh -N -f -L 3306:127.0.0.1:3306 user@servername.com
After the tunnel is set, you should be able to create connection against localhost:3306 and it will be forwarded to the DB server.
DB Related Components
There’re several components that allow using the database connection that we’ve defined in the previous steps. For a detailed description of them please see the CloudConnect Component Reference.
DBInputTable
CreateTableDBInputTable component allows sending resulting records of SQL query to output port in a similar manner to other readers. Some of the useful tricks are:
- Receiving SQL queries on input port
- Using multiple URLs with different queries to run more queries one after the other
- Using explicit metadata mapping
| Parameter name | Description |
|---|---|
| DB Connection | Reference to previously created connection |
| Query URL | URL to remote source file with the SQL query. Multiple URLs are allowed |
| SQL query | Directly inserted SQL query created manually or using SQL wizard |
| Data policy | Specifies component behaviour in case of an error, allowed values are: Strict / Controlled / Lenient |
DBJoin
DBJoinDBJoin component allows joining records directly to results of SQL queries. Records sent to the input port are considered master, output records from DB query are considered slave. Its parameters are mostly a combination of those found in other components, such as DBInputTable and ExtHashJoin.
DBExecute

DBExecuteDBExecute is generally useful when executing stored procedures or calling general DML / DDL queries, often before calling SELECT queries. It shouldn’t be used for SELECTs or INSERTs.
Example
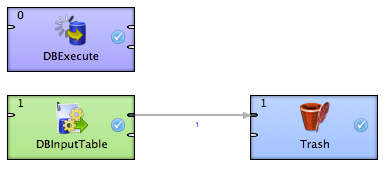
ExampleThe example transformation is a very simple one in this case - it consists of just one DBExecute component, one DBInputTable component, and one Trash component. The example transformation attempts to connect to MySQL DB called test on localhost:3306 and run a SELECT from table called test. The DBExecute attempts to create the table before the SELECT is executed.
The example project can be found in Gooddata CloudConnect examples repository on GitHub here.