CloudConnect - Working with Data on S3 Storage
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
One of core features of CloudConnect is its ability to extract data from variety of sources, with Amazon S3 gaining prominence lately because of its durability and good price/performance ratio. In GoodData services, we often utilise Amazon S3 both as a source and as a data storage for backups. I would like to cover the most popular use cases for S3 data downloads and uploads in the following article.
Overview
In GoodData Services we follow one of these use cases (with CSV being the most popular datatype):
- Single CSV read
- Multiple CSV read
- CSV write
- Multiple CSV backup
A similar approach will work for other CloudConnect readers.
Downloading Single CSV from S3 Storage

In most cases, you want to download single CSV file only and work with it on your computer locally. CloudConnect provides simple CSV Reader component, which supports reading from S3 as well as other popular remote protocols.
Setting up CSV Reader for S3 data downloading is quite a simple task. The only things you need to configure are the access keys for S3 storage, S3 bucket, and filename.
This is example shows how the file URL settings in CSV reader will look like:
http://access_key:secret_key@your_bucket_name.s3.amazonaws.com/filename.csv
For easier maintenance we recommend to use CC parameters ${S3_ACCESS_KEY} ${S3_SECRET_KEY} and store them in external parameter file. The variables can be used in multiple CSV readers working with S3 and make configuration easier. Fully configured example will look like this:
Remember that the S3 Access Key must be url escaped.
http://${S3_ACCESS_KEY}:${S3_SECRET_KEY}@your_bucket_name.s3.amazonaws.com/filename.csv
Downloading Multiple CSVs from S3 Storage
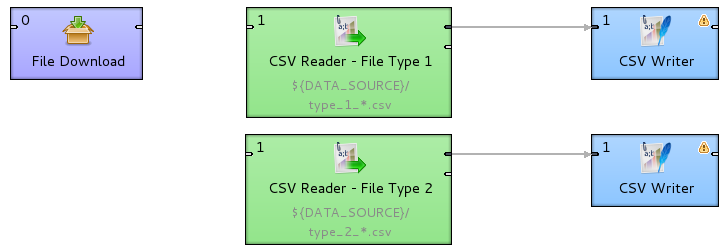
We have two possibilities how to handle this use case. First one is modifying previous example, but instead of providing file name, you can specify file name with wild-card (*). In this case all files must follow the same metadata structure. However, while working with this solution we encountered one issue - for really large numbers of files (100+), there is increased possibility of component time-out when reading data. As CSV reader does not implement any retry functionality, we had to develop another method for larger sets of files.
CloudConnect provides File Download component for reading larger sets of files. This component can be used for mirroring buckets / directories from S3 (or other remote storages) to local directories, as it also implements retry logic and is therefore better resistant against network problems. Using this component ensures large sets of files will be safely and reliably copied to local directory and can be easily accessed locally afterwards.
Another big advantage of this approach is that files don’t need to share metadata. You can simply download all files you need using only one component and work with them locally using multiple reader components.
Now let’s look at the parameters of the component. To set this component correctly you need to specify the following:
| Parameter name | Parameter description |
|---|---|
| URL to download | Path to your S3 files folder (bucket). It is very similar to the previous example. |
| Destination directory | Local path where the files will be copied to. |
Component settings can look like this:
| Parameter name | Parameter description |
|---|---|
| URL to download | http://${S3_ACCESS_KEY}:${S3_SECRET_KEY}@bucket_name.s3.amazonaws.com/daily*.csv |
| Destination directory | ${DATA_SOURCE} |
With this setting the component will copy data from S3. The names of copied files will start with daily text and will have .csv extension. Data will be copied to data/source/ directory (defined by default DATA_SOURCE variable).
Writing Simple CSV to S3 Storage

Writing single file to S3 storage is similar to reading it from S3, but we will be using CSV Writer component instead of CSV Reader. The most important parameter is File URL and this is same as for CSV Reader described above.
Backing up Multiple Files on S3

Because of its price and high availability, Amazon S3 provides ideal solution for data backuping. With this important use case in mind, File Backup component is provided. With the following options, several possible backuping scenarios can be easily prepared:
- Copy each file separately - each file will be copied to the remote location separately
- Compress each file separately - each file will be compressed as a separate archive
- Compress all files into a single archive - all files will be compressed as one archive
Now lets look at this component settings. To use this component correctly you need to specify following parameters:
| Parameter name | Parameter description |
|---|---|
| Files to backup | Path to files you want to backup. Wild-cards can be used here. |
| Mode | Explained above |
| Destination URL | Path to S3 bucket (folder) |
| Append timestamp (Optional) | Automatically append timestamp to each saved file |
| Timestamp format (Optional) | Format of appended timestamp |
Following example show how to set up the component to backup all files from data/source path to your S3 backup bucket. Name of saved file will be for example backup_2012-11-15.zip:
| Parameter name | Parameter description |
|---|---|
| Files to backup | ${SOURCE_PATH}/*.csv |
| Mode | Compress all files into a single archive |
| Destination URL | http://${S3_ACCESS_KEY}:${S3_SECRET_KEY}@bucket_name.s3.amazonaws.com/backup_.zip |
| Append timestamp (Optional) | true |
| Timestamp format (Optional) | yyyy-MM-dd |
Remember that ACCESS and SECRET key should be URL encoded!