CloudConnect - Using Lookups
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
One of more advanced graph elements are so-called lookups. You can imagine lookups as another way for data to enter the graph, apart from readers and other components for data input. A lookup is simply another layer of abstraction between your graph and the data you work with, allowing you to always use the same set of components and CTL functions, no matter what the real datasource behind the lookup is. I would also like to point out that I will only be covering a couple of most examples in this article - you might want to read documentation to learn about lookups in a more detailed manner.
Creating Lookups
When is it the right time to use lookups in your graph? If the data edges in your transformation cross too often and you access the same data files more than once, you should definitely give it a try!
To access the lookup wizard, right click the Lookups in the graph Outline and continue to Lookup Tables -> Create Internal. There are currently seven types of lookups available, but I will only describe the creation of the first one, the Simple Lookup.
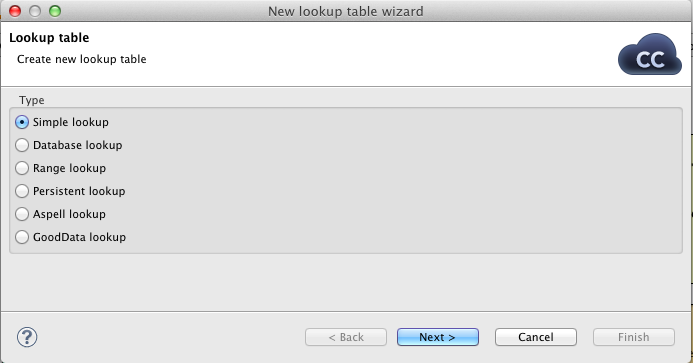
The wizard has two panels, one for parameters and one for source data.
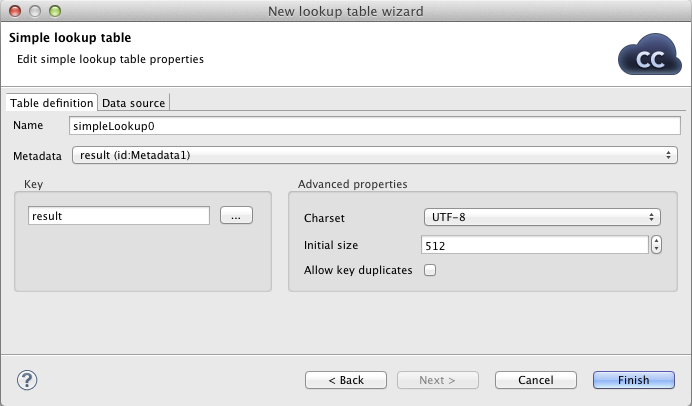
Table definition
| Parameter name | Parameter description |
|---|---|
| Name | Lookup identifier. |
| Metadata | Metadata describing the table structure. If your data are in a flat file, you might want to use metadata for the particular file. |
| Key | Primary key of the lookup. Records will be joined according to this key and also deduplicated by default. |
Data source
This panel allows to load data from file during graph initialization phase or even enter data manually if it fits your use case. It can be left blank in case you want to load the table during the graph run.
Components accessing lookups
Keeping large amounts of data within simple lookup may increase your graph memory requirements significantly! Keep this in mind if your transformation will be executed in a memory constrained environment.
LookupTableReaderWriter
As it name implies, this component can both write data to and read them from particular lookup (even at the same time if both input and output ports are connected). It can be also used to truncate the lookup.
LookupJoin
The LookupJoin component is where you actually merge the lookup content with the data flow. As with other joiners, you need to specify the key and the join type. However, you don’t have to care about which lookup type is being used, unless you hit memory limit or some other performance issue.
| Parameter name | Parameter description |
|---|---|
| Join key | Key according to which the incoming data flows are joined. |
| Left outer join | If set to true, also driver records without corresponding slave are parsed. Otherwise, inner join is performed. |
| Lookup table | ID of the lookup table to be used as the resource of slave records. Number of lookup key fields and their data types must be the same as those of Join key. These fields values are compared and matched records are joined. |
| Transform | Transformation in CTL or Java defined in the graph. |
Using Simple Lookup
Probably the most popular and also the easiest to set and use is the Simple lookup. Its core feature is the fact it is an in-memory table which is only persistent during the single graph run. The most popular usecases can be usually boiled down to one of the following:
1. Reusing data
If some local data are to be used more than once in the particular graph, loading it into simple lookup can decrease the number of components as well as save I/O, thus speeding execution.
2. Appending data
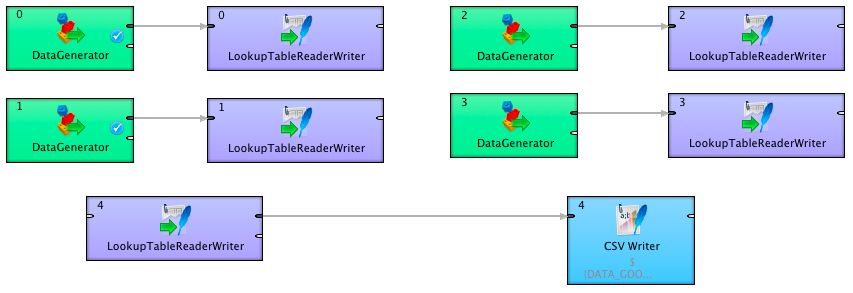
If you are creating a dataset that is appended from several sources during the graph run, you might save a lot of time by appending it into in-memory lookup and only outputting it when the processing is finalized.
3. Referential integrity assurance
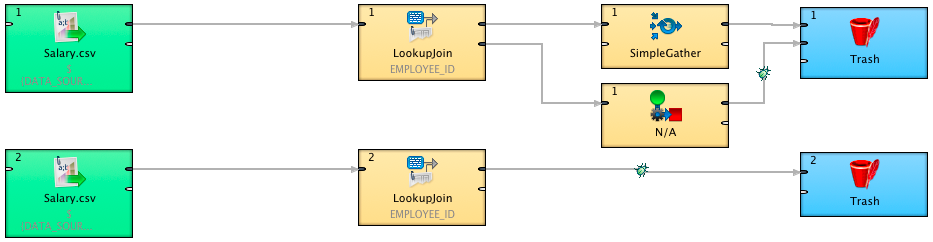
As the LookupJoin allows outputting unmatched records from an input port onto a slave output port, it can be well used to trap the unreferenced rows.
4. Data deduplication
One of the side-effects of the simple lookup is the fact it automatically deduplicates its content by key by default. This means it can also serve as a quick replacement for Ext/FastSort and Dedup component pair.
Using Lookups in CTL
Apart from accessing the data stored in lookups using the components mentioned above, it is also possible to access the stored records from within CTL scripts. The get() function example below will search the lookup for specified key and return the whole record or the specified field.
recordName1 testRecord;
string testField;
testRecord = lookup(simpleLookup0).get($0.ID);
testField = lookup(simpleLookup0).get($0.ID).text;
Example Project
Feel free to download the example project with practical examples on use cases mentioned!