CloudConnect - Reformat, Denormalizer, and Normalizer
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
After trying the simplest examples on how to load data into GoodData project, at some point (probably sooner than later) you will encounter situation that your data are not in the format required for the load. Luckily, there’s a large number of different transformer components for various scenarios. However, without knowledge which is the right one to choose for the task you need to deliver, you increase the overall complexity of your transformation or even fail altogether. And as transformations over single dataset are probably the most frequent, it’s essential to make the right choice here. In this article we will have a look at three components - Reformat, Denormalizer, and Normalizer.
What Is the Same
All the components we are covering in this article belong into the Transformers section, which apart from other facts means that one input port and at least one output port has to be connected. However, it’s not necessary for the input and output ports to share the same metadata. Moreover, each of these components has to implement the transform() CTL function, defining the input to output mapping. This can be either achieved by setting the mapping in graphical wizard or by directly editing the source.
For details on mapping functions please see the documentation ###here###.
function integer transform() {
$out.0.text = $in.0.text
return OK;
}
What Is the Difference
Probably the best way to describe the differences lies in the fact how each of those components trigger the transform() function related to the number of records they are processing.
| Component name | Description |
|---|---|
| Reformat | Transform function is triggered exactly once per every input record |
| Denormalizer | Transform function is triggered once per one or more input records |
| Normalizer | Transform function is triggered at least once per input record |
Reformat
If you look at the description above carefully, it is probably clear that both Denormalizer and Normalizer can be used to simulate Reformat if set accordingly. However, I recommend to avoid doing this as it makes the graph more difficult to read.

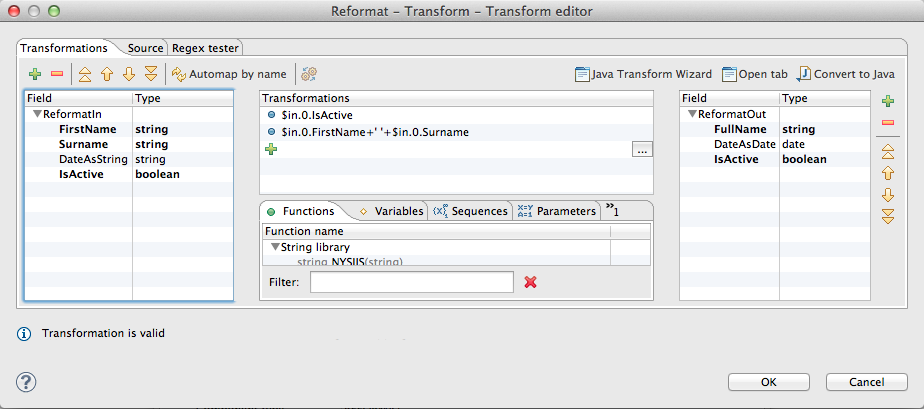
The Reformat component is arguably the most popular among transformers. It allows using wide range of CTL functions inside the transform() function as well as emulating various other transformers (ExtFilter and SimpleCopy to name a few). Traditional usage includes string manipulation, data type conversion etc. However, Reformat won’t help you in case you want to split or merge the input records.
function integer transform() {
//Let's join the names and create a fullname field
$out.0.FullName = $in.0.FirstName + ' ' + $in.0.Surname;
$out.0.DateAsDate = str2date($in.0.DateAsString,"dd-MM-yyyy");
//We want to track only the active users and filter the inactive out
if ($in.0.IsActive) { return OK; } else { return SKIP; }
}
Denormalizer

Using Denormalizer, you’re basically lowering the number of records on input in favor of making the dataset wider, usually with intention to merge rows belonging to the same entity. Apart from the transform() function, each instance of Denormalizer also has to implement function append(), which defines the way the input records are merged.
| Parameter name | Description |
|---|---|
| Key Rows | sharing the same key are merged (in our example it’s the Person field) |
| Group Size | An alternative to Key parameter, used when the number of rows per output row is constant |
| Denormalize | Defines the transform() and append() functions |
A simple example input data for Denormalizer could look like this:
| Person | Attribute | Value |
|---|---|---|
| John Doe | Age | 31 |
| John Doe | City | Anytown |
| John Doe | Sex | M |
This situation is common when your source is not a relational database with a fixed set of fields, or if the source allows complex data types. As a result there’s a collection of attributes for every entity (person in our case) and for some entities there might be more rows than for others. Imagine that a following couple of rows in our example dataset would look like this:
| Person | Attribute | Value |
|---|---|---|
| Jane Doe | Age | 46 |
| Jane Doe | City | Notown |
| Jane Doe | Sex | F |
| Jane Doe | Occupation | GoodWorker |
However, no matter how many different records there are for each entity you process, the dataset you will be eventually loading your data into has to have some fixed structure. You can decide to go for all the attributes you can find in your data source and fill the missing with nulls or “N/A” strings, or pick just the attributes that are common for all the records, but the final structure has to be fixed, such as:
| Person | Age | City | Sex | Occupation |
|---|---|---|---|---|
| John Doe | 31 | Anytown | M | N/A |
| Jane Doe | 46 | Notown | F | GoodWorker |
Using Denormalizer is the way to go if the attributes for entity you’re interested in is spread over several records.
DenormalizedMeta1 myRecord;
function integer append() {
setStringValue(myRecord,$in.0.Attribute,$in.0.Value);
myRecord.Name = $in.0.Person;
return 1;
}
function integer transform() {
$out.0.* = myRecord;
return 1;
}
Normalizer
In the Excel world, it’s quite common to see datasets formatted like this:
| Name | Salary_2011 | Salary_2012 | Salary_2013 |
|---|---|---|---|
| John Doe | 10000 | 11000 | 12000 |

Now, this is perfectly correct to use in a spreadsheet. However, for the future data analysis it’s a bit unfortunate, as the Salary_XX is in reality the very same fact, only preaggregated for a certain year. With dataset like this, some questions become difficult to answer (“What’s the sum of salaries over the years”). Moreover, what if 2014 is added, which can be expected? In case ETL is poorly designed, it might be necessary to change the LDM because of such a small updates.
In similar case, it’s probably worth converting the data into something like this:
| Name | Year | Salary |
|---|---|---|
| John Doe | 2011 | 10000 |
| John Doe | 2012 | 11000 |
| John Doe | 2013 | 12000 |
In this case, we’re perfectly fine with adding new records. Also, it’s a lot easier for us if some records are missing.
Apart from transform(), we also need to define function count() which defines how many records will be produced per one input record. Based on the use case, the number might be fixed or computed dynamically (one field containing a list of strings would be a good example for this). Let’s use the length of our input metadata in case of our dataset:
function integer count() {
//Get the number of fields in the input
return (length($in.0.*)-1);
}
function integer transform(integer idx) {
$out.0.Name = $in.0.Name;
$out.0.Year = num2str(2011 + idx);
//Access the input record by index
$out.0.Salary = getStringValue($in.0.*,idx+1);
return OK;
}
Example
I have created a simple example transformation to illustrate the use cases from this article. Feel free to download the example here.