CloudConnect - Accessing Internal Project Storage
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
There are many cases when being able to store data from graph run would simplify the transformation creation and will allow creating complex scheduling setup. For example, you might want to run several differently scheduled graphs in one project and search for an option how to share their execution states. There are of course several ways how to do this, but there is a storage which very well serves the purpose of storing small amount of data directly within GoodData project - the internal project storage.
In terms of functionality, the internal project storage is a collection of key / value pairs, something which is usually referred to as a map or an associative array. An example of such stored pairs could look like this:
{
"Today": "Monday",
"Tomorrow": "Tuesday",
"Weather": "Overcast",
}
However, practically any value that can be stored as a string is permitted, with the limitation you can only search by key.
In GoodData services team, we utilise this storage to keep various processing information, such as number of loaded records or the last downloaded timestamp. However, it could also be used to filter the input data if there’re for example different projects using the same graph for download.
Important Facts
When considering whether your use case fits the internal storage purpose, it’s good to keep the following facts in mind:
- The storage is bound to the particular project and is identified by its PID
- Only users with admin rights can access the storage and its content
- The throughput and capacity is limited (i.e. you should not use it to replace general lookups)
- There’s no need to initialize the storage, it’s created with the project itself automatically
Using Internal Storage in a Graph
To be able to reach the content of the storage from within CloudConnect graph, you need to create the lookup table first. Please read more on lookups and their usage here:
Populating the storage
Depending on the use-case, you can pick one of the following possibilities:
Entering the data manually via CloudConnect Wizard
Manual entry is useful in case there’s limited number of key/value pairs and it’s unlikely the data will change in the future. Downloading data from generic API and entering the filtering condition is a good example.
Loading the data via LookupTableReaderWriter

As the storage can be represented as a special type of Lookup inside CloudConnect graph, components such as LookupTableReaderWriter or LookupJoin can be used to access it.
Loading the data via API call Call to GoodData API will also do the trick of storing one or more key/value pairs, although there’re friendlier methods to do so using CloudConnect:
curl -X POST https://user%40company.com:password@secure.gooddata.com/gdc/projects/pid/dataload/metadata --insecure --header 'Content-Type: application/json' -d '{"metadataItem":{"key":"key1","value":"value1"}}'
Getting the data out
There are also several methods to access the data that are already in the storage:
LookupTableReaderWriter Component The LookupTableReaderWriter component is probably the most convenient way of getting all the available Key / Values at once. You simply configure it to use the right GD Lookup and create metadata with two string fields (named Key and Value).

LookupJoin Component When directly joining / filtering other dataflow, you might want to use the LookupJoin component and define the behaviour in its transform() function. Lookup is listed as another data source on “virtual” port, again using the Key / Value metadata.

CTL Function As with other Lookup Tables, it’s also possible to use the CTL functions to access the lookup contents from components that allow it (usually Joiners or Transformers):

#Example call: lookup(lookupname).get(key).value; string myString = lookup(myLookup).get(myKey).value;Using API get It’s also possible to use GET request to query for particular key.
curl -X GET https://user%40company.com:password@secure.gooddata.com/gdc/projects/pid/dataload/metadata/key1 --insecure --header 'Content-Type: application/json'
Example
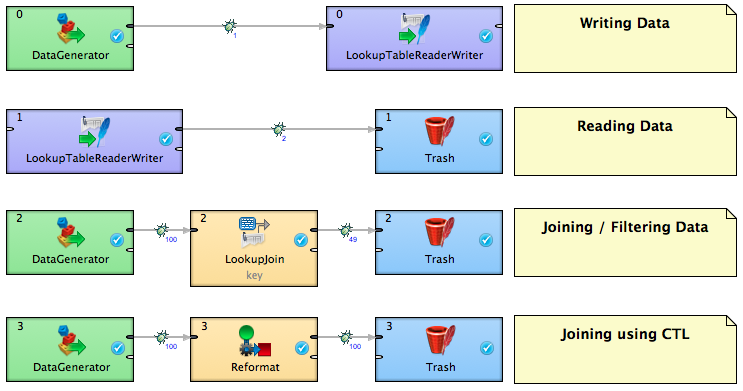
I have created a simple example transformation to illustrate possible use cases from this article. Please keep in mind that you have to let the graph know which of the projects on platform to use by setting the “working project”, otherwise the storage will not be accessible and the graph will fail. Feel free to download the example here.