Many-to-Many in Logical Data Models
A many-to-many relationship, also known as M:N, is similar to a one-to-many relationship in that tables are joined together but the relationship is more complex. For example, a marketing automation system allows you to assign one or more predefined ‘tags’ to each marketing campaign. With these tags, you can organize campaigns in any way you want.
| Campaign | Channel | Tags | Total Cost | MQL |
|---|---|---|---|---|
| CIO Retail Summit | Tradeshow | Event, DigOut2018, Salestream, | 172,350.36 | 148 |
| Game Time Savings | Digital | LinkedIn, Spring16 | 17,439.82 | 33 |
| Quarterly Trends Campaign | ThoughtLeadership, Spring16, Developers, | 5,991.37 | 16 | |
| Apparel Nurture Campaign | Nurture, Spring16, | 4,522.91 | 27 | |
| Why E-Commerce Data | Content | Developers, | 9.023.11 | 17 |
Every campaign can have multiple tags and every defined tag can be attached to multiple campaigns. It is an example of a many-to-many relationship, a very useful structure that allows you to ask questions such as:
- What is the overall spend per channel for ‘Nurture’ campaigns?
- What has been the total cost of our ‘Spring16’ marketing program?
- For each program, how many Marketing Qualified Leads (MQL) did we generate, and what was the cost per MQL?
The following article explains how to model many-to-many relationships on the GoodData platform.
To learn more about many-to-many relationships, see Analytics for the Modern World.
To use the Many-to-Many feature described in this section, you must ensure your workspace uses XAE version 3 (default for all users since October 2018). Although it is possible to deploy Many-to-Many with a lower XAE version, this feature will not work as intended. For instructions on how to upgrade, see Upgrading XAE to Version 3.
Supported operations
Modeling Many-to-Many Relations You can create a model with a multi valued dimension/attribute that (indirectly) connects to a fact table via a bridge table. The XAE engine understands this is an intentional many-to-many relation in the data model.
Use of Multi-Valued Attributes for Creation of Insights and Reports Use a fact and multi-valued attribute (or attribute from multi-valued dimension) in Analytical Designer to create an insight so that multi-valued attribute slices data (in view by) and/or filter data (in filters).
Visibility of Many-to-Many Relation in the model View the data model via the manage page to see multi-valued attribute is usable via many-to-many relation. The relation is clearly differentiated from other M:N relations between fact tables that are not directly usable for slicing and filtering.
Filtering over M:N Filter facts over M:N relation without impacting the result by double counting so that you can use filters (e.g. in Mandatory User Filters (MUFs) or as dashboard filters) without worry about the impact on the accuracy of existing reports.
Restrictions to M:N
Allowing many-to-many relationships in your logical data model requires careful planning to avoid introducing ambiguity into how the GoodData engine interprets the relationship and approaches calculations.
Logical Data Model Limitations
The following data model schemes show invalid and not-recommended modeling structures among datasets. Attempting to save a model with such structures may fail. See Data Modeling in GoodData.
Example 1
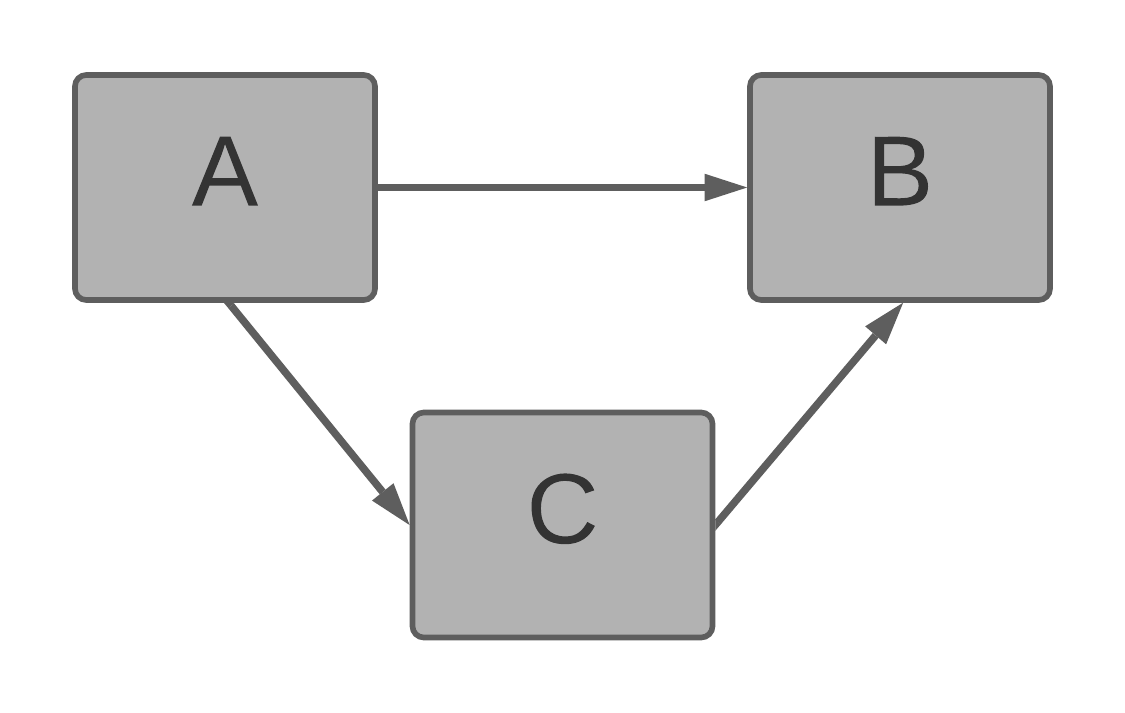
The following model is valid but not recommended.
It introduces alternative one-to-many paths. As a result, the analytical engine randomly selects between the available paths in any computation (A → B or A → C → B) which produces non-deterministic results.
Example 2
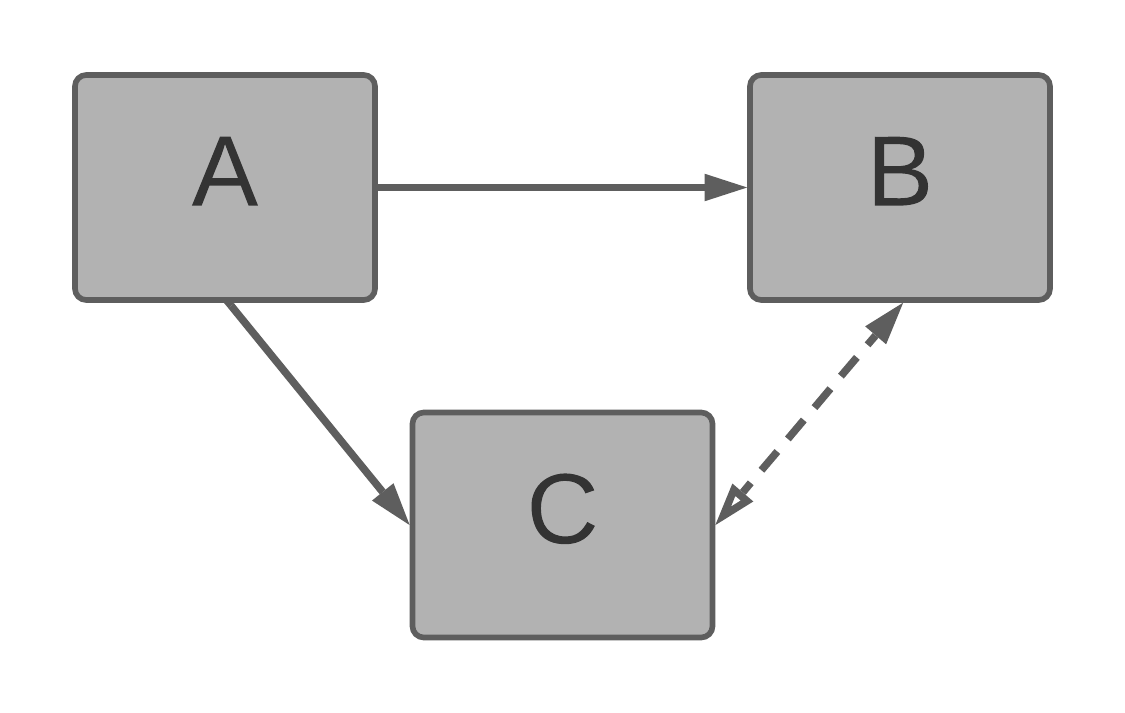
The following model is invalid. Not only it features alternative one-to-many paths (A → B or A → C → B) but one of them contains a many-to-many edge in the C → B direction.
Example 3a
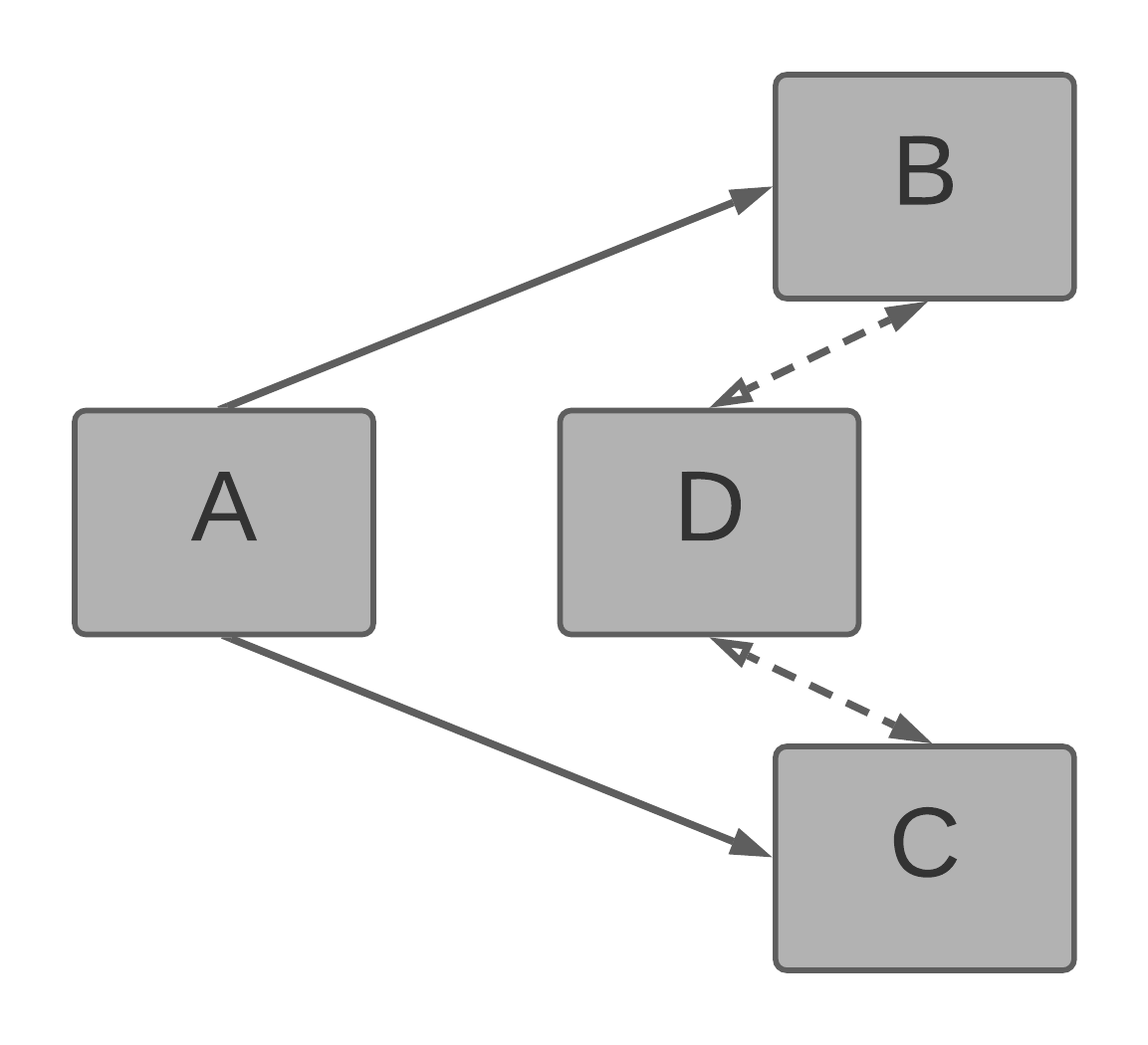
The following model is invalid. In this case, the analytical engine encounters dual ambiguity and does not know which path to choose: A → B → D or A → C → D. This because both paths introduce a many-to-many relationship between A and D.
Example 3b
The following model is valid. While it features alternative paths (C → B and C → D → A → B), the analytical engine will select C → B because it is a one-to-many path.
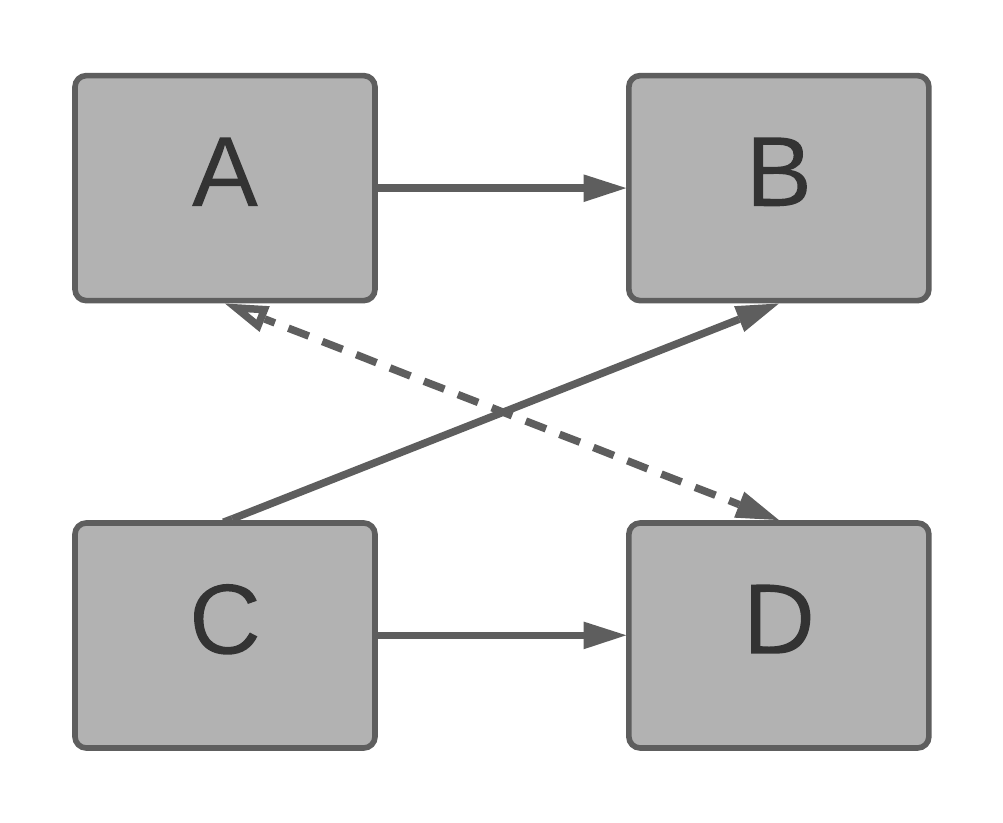
Example 4
The following model is invalid. Bridge dataset C is referenced by dataset D, however, bridge datasets cannot be referenced.
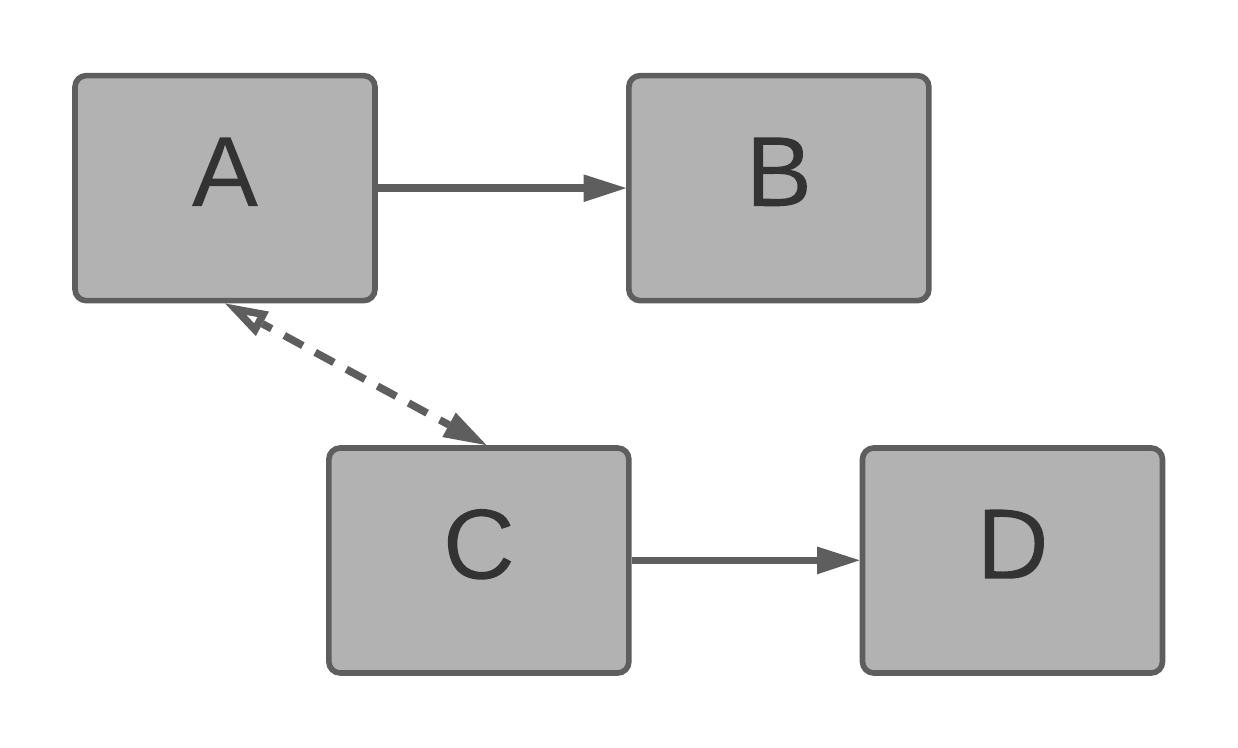
Bridge Dataset Limitations
- Native filtering by bridge dataset is not supported.
- A workaround is possible using the BY statement to filter multi-value attribute by bridge dataset and filter the fact by the result.
- Using a fact in a bridge table to calculate a weight of a relation is not supported. Example: Different commissions for Sales reps and various products.
Negative filters results when used in M:N model
The syntax WHERE Attribute NOT IN (values) returns records, where the result include at least one different value from the filtered value. The syntax WHERE NOT Attribute IN (values) returns records, where the result include at least one different value from the filtered value. Analytical designer generates NOT ( [attribute] IN ( [element1, element2, …] )) for negative filters.
Records: Ticket ID: 123, Tags: (xxx, abc, orange) Ticket ID: 222, Tags: (xxx) Ticket ID: 666, Tags: (abc) Ticket ID: 999, Tags: NULL
Queries and Results: HOW TICKETS WHERE Tag IN (“xxx”) >>> 123, 222
WHERE TAG = (“xxx”) >>> 123, 222
WHERE Tag NOT IN (“xxx) >>> 123, 666
WHERE TAG != (“xxx”) >>> 123, 666
WHERE NOT Tag IN (“xxx”) >>> 123, 666
WHERE NOT Tag = (“xxx”) > 123, 666
WHERE Tag NOT IN ( xxx, abc, orange ) >>> No result
WHERE NOT Tag IN ( xxx, abc, orange ) >>> No result
Similar behavior for: Tag NOT LIKE vs. NOT Tag LIKE Date NOT BETWEEN vs. NOT Date BETWEEN
Performance Recommendations
Computing an aggregated metric over datasets in an M:N relation may bring performance problems in case the LDM is not designed properly, as the bridge table scales according to size of the connected datasets.
Behavior of AND Filters in M:N Model
Filtering by multiple attributes returns a result where all conditions that are logically related to each other are applied together on the result. (Instead of application of particular conditions for each dimension before consolidating the final result).
Consider the following model and data:
TICKET DATASET
"Ticket_id","status","MN_Date","Resolution_time"
"support01","new",2018-04-13,20
"support02","backlog",2017-09-09,50
"support03","hacking",2016-02-14,3 0
BRIDGE TICKETTAG DATASET
"MN_tickettag_id","stage","Ticket_id","Tag_ID","date_2"
"tickettag01","user created","support01","tag01",2018-04-12
"tickettag02","system created","support03","tag03",2017-11-15"
"tickettag03","system created","support02","tag05",2018-10-22"
"tickettag07","system created","support01","tag02",2018-04-12"
"tickettag08","system created","support02","tag02",2018-06-01"
"tickettag10","system created","support01","tag04",2018-05-22"
"tickettag12","system created","support01","tag07",2018-04-13"
TAG DATASET
"Tag_ID","Tag Name" "Risk_level","Internal costs"
"tag01","Reporting","High",200
"tag02","Tier 1", "High",300
"tag03","Uploads","Medium",200
"tag04","Performance","High",300
"tag05","Exporters","Medium",200
"tag07","CloudConnect","Low",100
EMPLOYEE/TICKET ASSIGNMENT DATASET
"Assignment_ID","MN_Ticket_ID","MN_Employee_ID"
"AS1",support01","EMP1"
"AS2","support02","EMP2"
"AS3","support03","EMP3"
"AS10","support01","EMP2"
"AS11","support02","EMP3"
"AS12","support03","EMP4"
EMPLOYEE DATASET
"MN_Employee_ID", "MN_Employee_Name", "MN_Employee_City", "MN_Employee_Salary"
"EMP1", "Gerry Weber", "London", 1150
"EMP2", "Laura Sanchez", "Málaga", 950
"EMP3", "Conchita Martinez", "Marbella", 700
"EMP4", "Jon Olsson", "Puerto Banus", 2000
Results:
Filtering by Employees = All and MN_Stage = system created and MN_Tag_ID = tag01 will lead to zero result as there is no exact match on the resolution Time of tickets, which would have Tag01 and were created by the system and assigned to any employee.
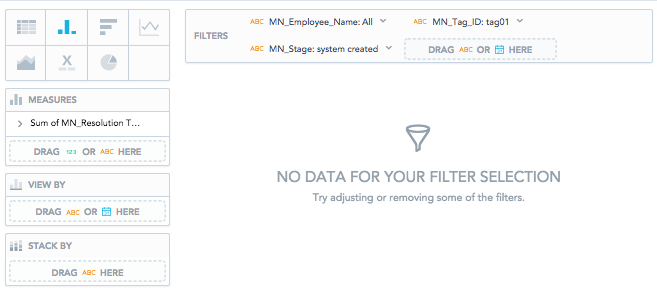
Double Counting in an M:N Model
Double counting occurs in report computation with an M:N model. It happens anytime when user slices by multi-valued attribute as the values are calculated for each multi-valued attribute (and the fact may be related to multiple multi-valued attributes).
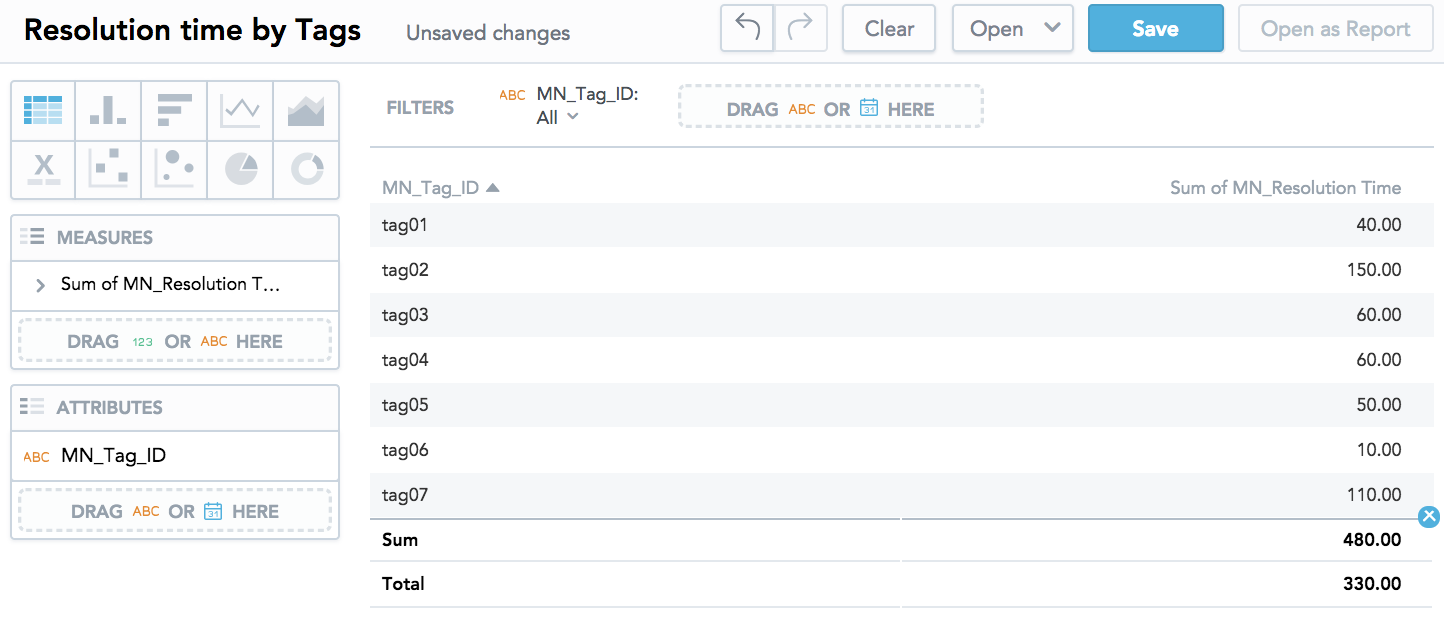
M:N and Data Modeling in CloudConnect
The CloudConnect data modeler is a part of the legacy CloudConnect application. For more information about its usage, see Data Modeling Using the CloudConnect Tool.
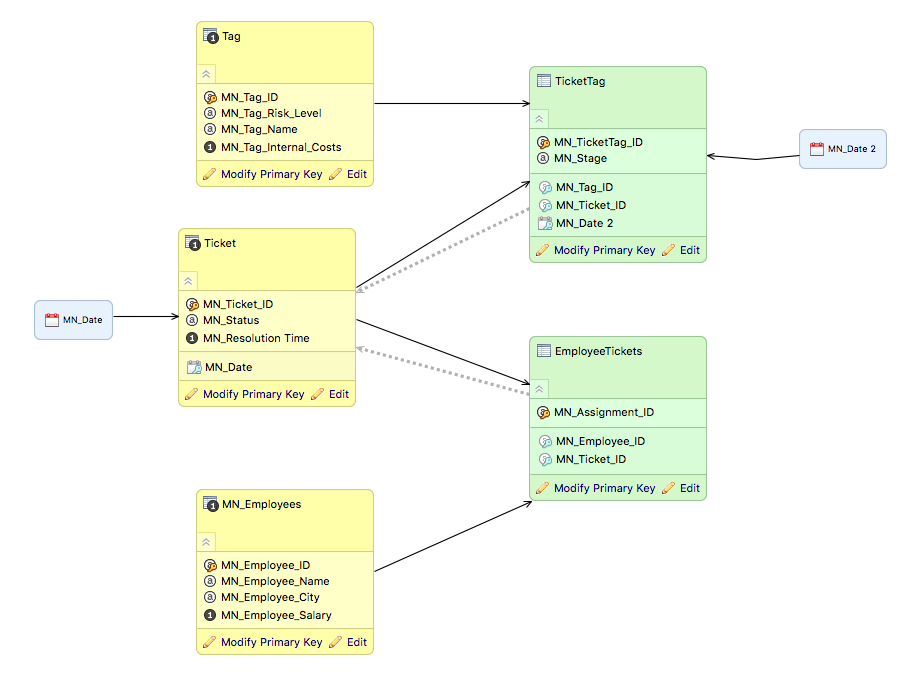
Review the following in the context of the data model scheme.
- Current 1:N model contains standard relation between Ticket and TicketTag (bridge dataset), where Tag is the multi-valued dataset.
- There is no need for a dummy fact nor a surrogate key in the bridge table. For a primary key, we recommend that you use the fact table grain.
- The goal of the designer is to allow slicing and filtering of Resolution Time by Tag ID.
- Click TicketTag dataset and drag the arrow in opposite direction than the standard relation.
- M:N edge represented by a dotted arrow and operations (filtering, slicing) by the Tag is enabled (after the model is published to the server).
Relation modeling behaves as usual in GoodData for 1:N
- aggregation of the fact is possible in the opposite direction of the arrows from the fact
- filtering of the fact is possible in the direction of the arrow from the filter to fact. To filter with a tag, you can aggregate the fact to that dimension level.