Connection Points in Logical Data Models
A connection point is an attribute in your logical data model (LDM) that does the following:
- It is a primary key of the dataset, which enables the GoodData platform to distinguish individual records.
- It is an attribute that enables connecting this dataset to another one using its values to make a relationship.
Connection Points and Datasets
Connection points are important identifiers of uniqueness within a dataset. For example, you must define a connecting point in each dataset that is loaded using incremental data loads.
To connect two datasets, define a connection point (primary key) in the first dataset, and a reference (foreign key) in the second dataset. Together, they form a relationship - a one-directional mapping between a parent object and a child object that will reference the data in the parent object. Two connected datasets form a hierarchical relationship, with the referenced dataset being on a higher level in the hierarchy.
You can have only one connection point per dataset, but there can be many references to that connection point in other datasets.
Via the connection point, a dataset can be connected to many other datasets, where there are references to the connection point. However, any single reference in a dataset can point back to only one connection point.
When building reports, you can build your reporting relationships from the transaction data, containing the references to the unique identifiers contained in the other dataset.
The query engine uses the connections in the LDM to connect the underlying database table using inner joins unless an outer join is explicitly enforced using the IFNULL MAQL keyword.
The direction of the arrow determines which dataset’s data can be analyzed (sliced) by the data from the other dataset. For example, in the following LDM, the relationship between the Customers and Order Lines datasets allows you to slice Quantity by Customer Name.
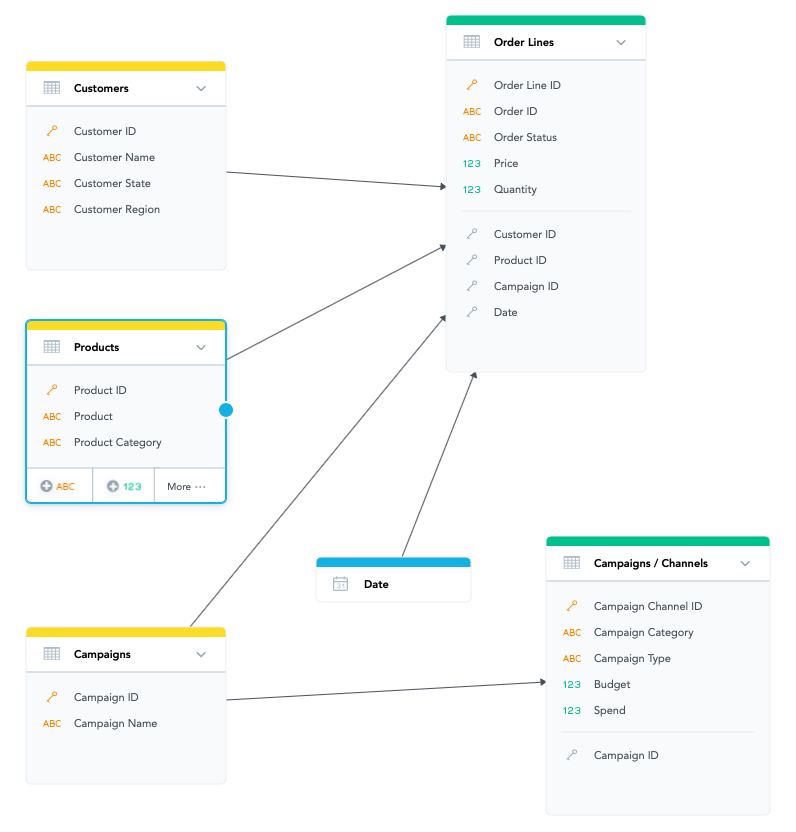
Recommended Practices
- Make sure that each value of the connection point is unique. If the data contains multiple rows with identical values of the connection point, only one row is loaded into the workspace, and all other rows are dropped.
- Make sure that each value in the reference attribute has a corresponding connection point of the other dataset. The values of the reference attribute does not have to be unique.