Work with Fact Table Grain Using CloudConnect Modeler
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
This article shows you how to work with the Fact Table Grain using the CloudConnect LDM Modeler. It assumes prior knowledge of the Fact Table Grain concepts (see Set the Grain of a Fact Table to Avoid Duplicate Records).
Set the Fact Table Grain in an Existing Project
You can sen the grain for both a new fact table and an existing fact table that already has a connection point.
Steps:
- On the LDM modeler panel containing your LDM model, locate the fact table where you want to set the fact table grain.
- In the fact table, click the Set / Modify Primary Key link.
The Primary Key dialog opens.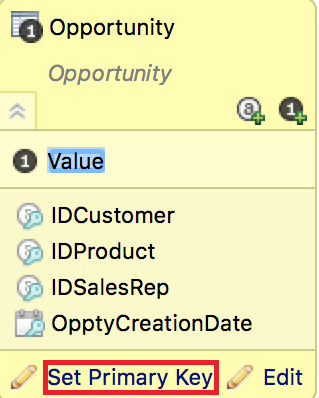
- Select Fact Table Grain (compound primary key).
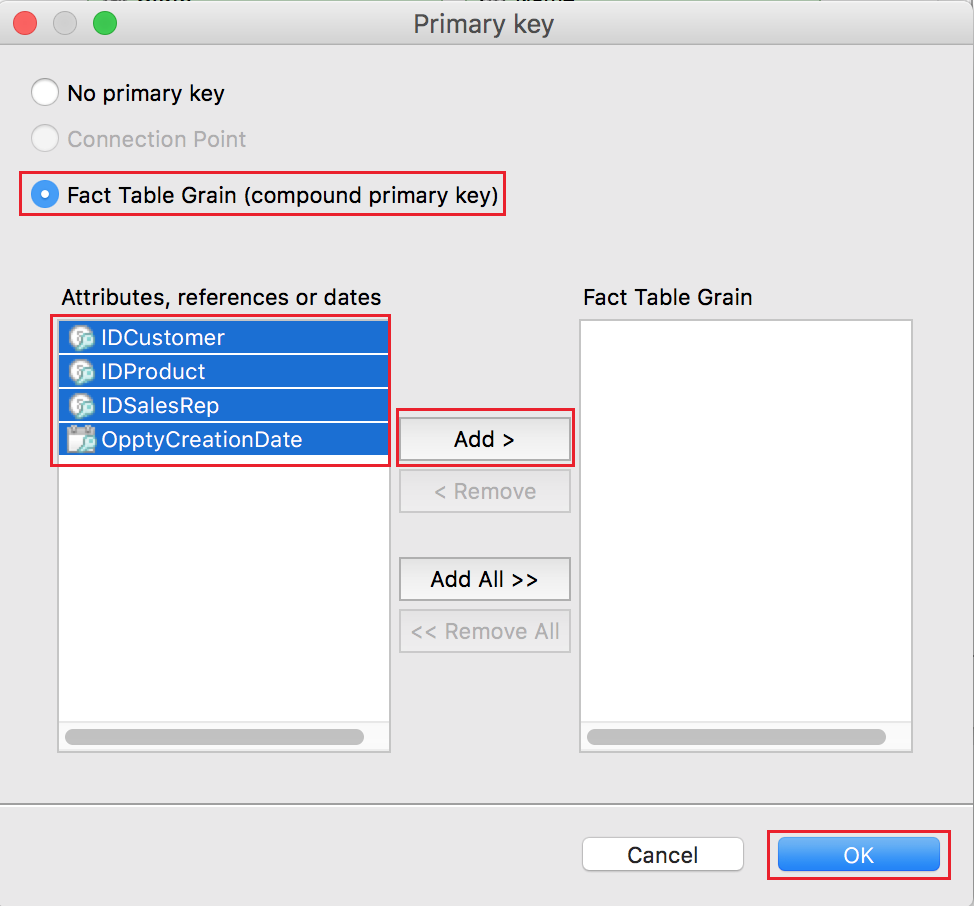
- Form the fact table grain: move items from the list of attributes, references or dates on the left to the list of items on the right.
- Click OK. The dialog closes. The fact table grain is set.
- In the fact table, click the Set / Modify Primary Key link.
- Adjust your ETL. You do not have to generate the connection point data anymore, so you may remove that code. Though this is optional, doing so will improve performance. If you do not remove the code, the ETL will keep working normally.
Types of the Keys in the LDM Modeler
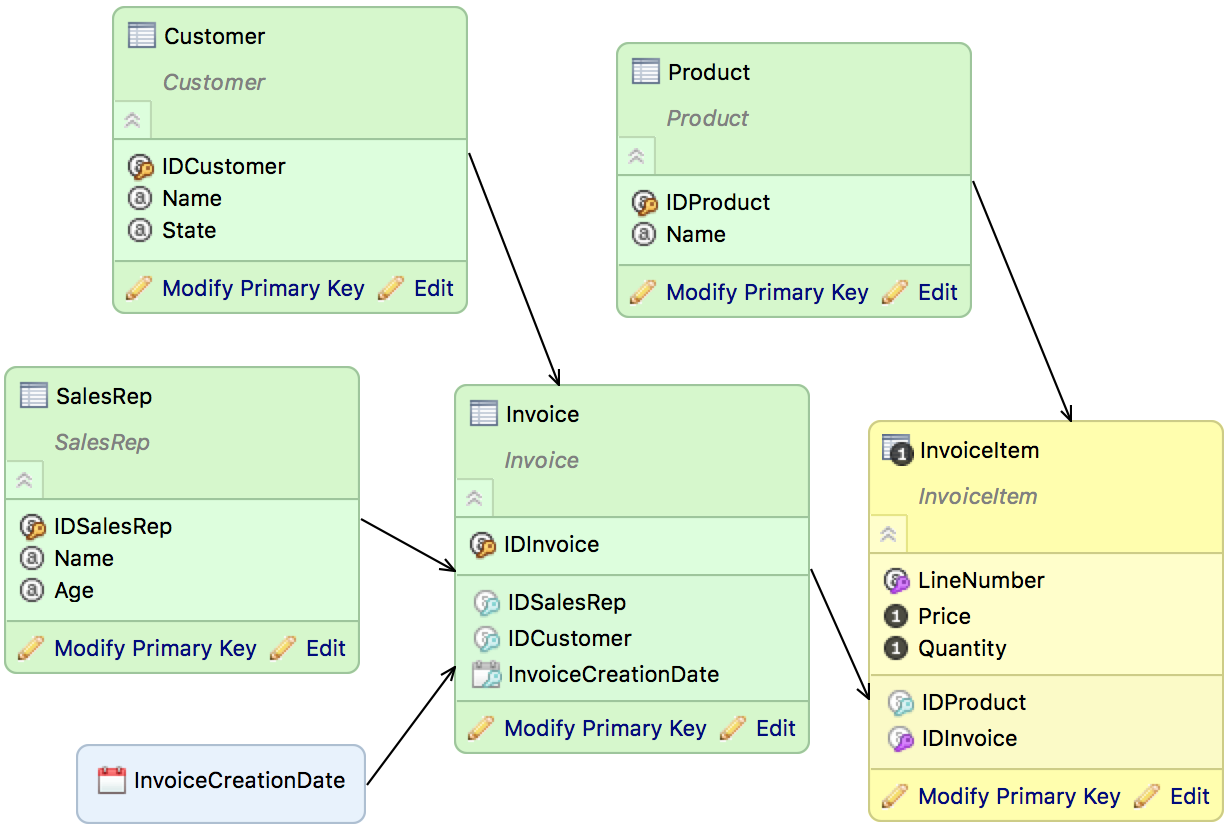
LDM Modeler uses the following types of the keys differentiated by color:
- Yellow: An attribute is a connection point.
- Blue: A reference to another dataset with a connection point.
- Purple: An attribute is a part of Fact Table Grain.
Alter an Existing Grain Definition
If you must change the grain definition (for example, due to changes in your internal processes), navigate to the Primary Key dialog and change the set of attributes / references / dates that define the grain.
Examples
Example 1. New LDM development: adding a grain to an attribute without a connection point
The following data model example includes the attributes InvoiceNumber, LineNumber, and IDProduct, and the facts Quantity and Price.
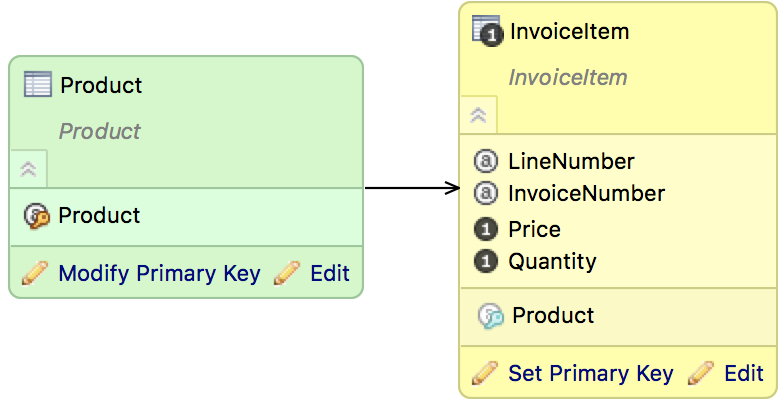
Each invoice line must have a unique combination of Invoice number and Line number, so these attributes always occur in a unique combination for the fact table. The dataset InvoiceItem might look like this:
| Invoice number | Line number | Item | Quantity | Price |
|---|---|---|---|---|
| 300 | 1 | plastic pumpkin | 7 | 72 |
| 300 | 2 | pirate costume | 1 | 50 |
| 300 | 3 | lollipops, 1 kg | 1 | 6 |
| 301 | 1 | glow sticks | 50 | 100 |
| 301 | 2 | pirate costume | 1 | 50 |
Imagine that you discovered that the price 72 set for the first record is wrong. If you upload correct data (300, 1, plastic pumpkin, 7, 70) without setting the grain, this record will be added as a new row, making your data incorrect.
To avoid this, set the grain for the InvoiceItem fact table using the Set Primary Key dialog. Set LineNumber and InvoiceNumber as attributes forming a Fact Table Grain. If you set it correctly, purple keys will appear next to the InvoiceItem and LineNumber attributes.
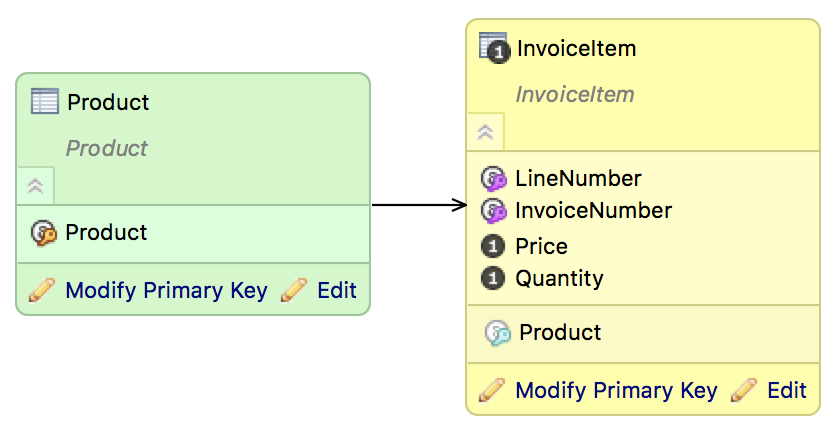
Now, if you upload correct data (300, 1, plastic pumpkin, 7, 70), the data in the first row will be replaced with the newly uploaded data, and no new row will be added.
Example 2. Existing LDM development: using a grain instead of a connection point
Snapshotting (see Analyzing Change with Historical Data (Snapshotting)) is a very common technique in data modeling.
The fact table Opportunity Snapshot contains the connection point Opportunity Snapshot ID fulfilled by some MD5-concatenation of Opp. ID and Snapshot Date. When you need to update a particular opportunity record in the fact table for some specific date in history, you can identify it by these two values.
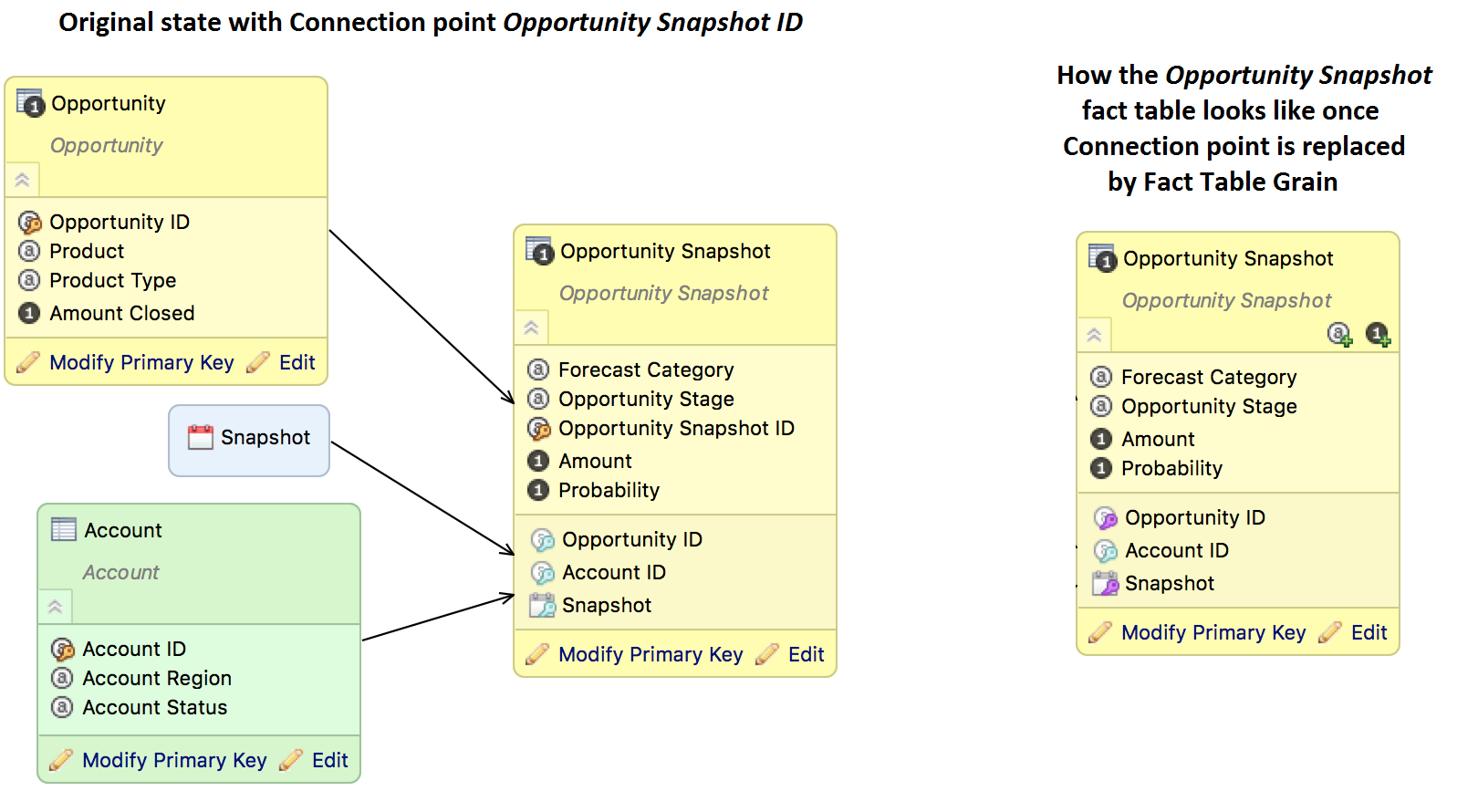
With the Fact Table Grain feature, you can move this logic behind Opportunity Snapshot ID to the GoodData platform: instead of Opportunity Snapshot ID, you would use two references - Snapshot and Opportunity ID - as components of Fact Table Grain.
By the next load, the fact table will be scanned for duplicates in the new compound primary key.