Data Model Object Types in CloudConnect Modeler
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
You can create different objects within your datasets. You can also review the corresponding object type that appears in the GoodData Portal in your projects.
To change the type of data model object, select it in the Attributes and Facts window. Then, click the Browse button in the Type column. See Attributes and Facts Window in CloudConnect.
Within the Attributes and Facts window, you can configure the datatype for the selected type of field. See LDM Object Datatypes in CloudConnect.
Attribute
An attribute is a text or discrete numerical data element that is used for segmenting numerical facts or the metrics that aggregate fact values.
Attributes may contain one or more labels (also known as displayForms), which are display values for the attribute.
When configuring an attribute or a connection point in the Select Type window, you can specify the default label of the attribute that contain values to display in a report for the attribute. You can also specify the attribute label used to sort values, and its sorting order.
In the GoodData Portal, attributes are used to slice reports by specific attribute values. In a report definition, you define the attribute or attributes to use in slicing the report. You can also apply attributes to specific metric definitions.
Label
A label provides a different means of representing an attribute. For related data, you can use labels in your logical data model to represent part or all of the attribute. For example, the Name attribute might have labels for Firstname and Lastname.
When selecting an attribute to include in a report, you can choose from any available labels for the attribute.
In the GoodData Portal, you can use labels as the display name for the related attribute.
For more information, also see Discover Attribute Labels and Drill Paths.
Hyperlink
Hyperlink is translated automatically as an HTML link.
In the GoodData Portal, inside a report that references a hyperlinked attribute, click the attribute value in the report to visit the specified destination of the link.
By default, string datatypes are configured with a limit of 128 characters. For hyperlinks, consider expanding this limit. See LDM Object Datatypes in CloudConnect.
Fact
A fact is a numerical element of data. Facts can be integer, float, or double values.
Aggregations involved in floating point values can generate rounding errors if a significant number of values are being aggregated. Avoid using floating point types, if possible.
In the GoodData Portal, facts are used as the source data for building aggregating metrics.
Connection Point
A connection point is an attribute in your data model that does the following:
- It is a primary key of the dataset, which enables the system to distinguish individual records.
- It is an attribute that enables connecting this dataset to another one using its values to make a relation. See Building Relations between Objects in CloudConnect Modeler.
To connect two datasets together, define a connection point (primary key) in the first dataset, and a reference (foreign key) in the second dataset. Together, they form a relation.
Connection points do not appear in the GoodData Portal. However, they are important identifiers of uniqueness within a dataset. For example, you must define a connecting point in each dataset that is loaded using incremental data loads.
Follow these rules for connection points:
- Each value of the connection point must be unique. If the data contains multiple rows with identical connection point values, only one row is loaded into the project, and all other rows are dropped.
- Each value of the connection point must have a corresponding value in the reference attribute of the other dataset.
- The values for the reference attribute are not necessarily unique.
- You can have only one connection point per dataset, but there can be many references to that connection point in other datasets.
- Via the connection point, a dataset can be connected to many other datasets, where there are references to the connection point. However, any single reference in a dataset can point back to only one connection point.
- When connected, two datasets form a hierarchical relationship, with the referenced dataset being on a higher level in the hierarchy.
When building reports, you can build your reporting relationships from the transaction data, containing the references to the unique identifiers contained in the other dataset.
Connection point example
To better understand the concept, let’s review the following example:
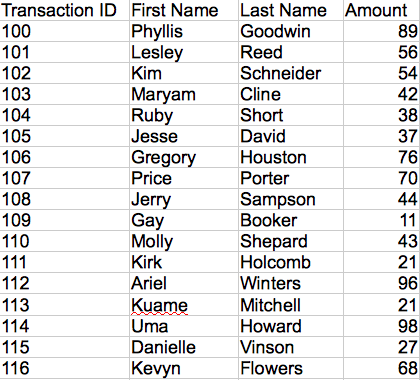
This table illustrates payment transactions made by individual customers. Each transaction has a Transaction ID to serve as a unique identifier. This field is an ideal candidate for a connection point.
A customer may not necessarily make just one purchase, so this transaction ID may show up multiple times in the record of payments if a customer makes multiple purchases.
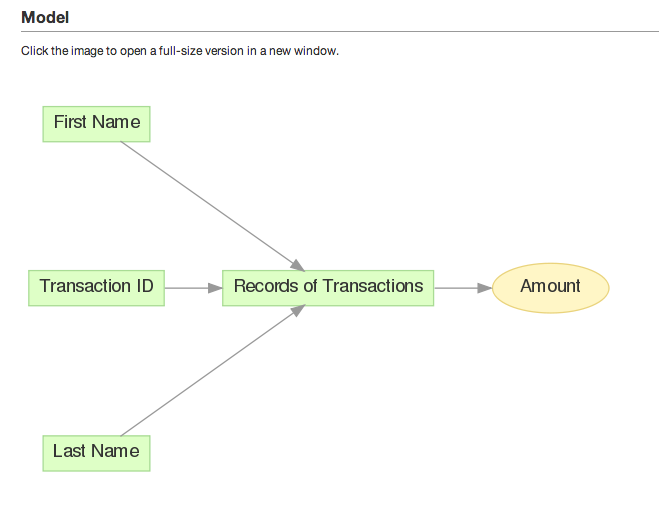
In CloudConnect, the data model looks like the following:

When the data model is published, here is how it looks like in the Portal:
Now, let’s normalize the transaction data into two tables: one for transactions and the other for customers. Here are the customers with unique Customer ID values:
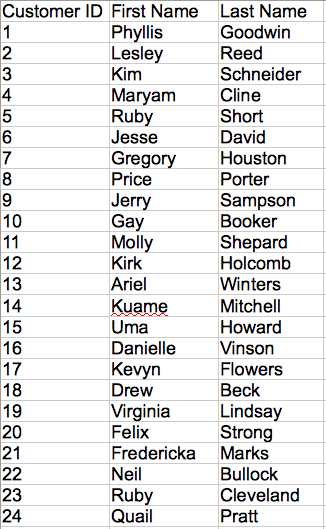
Note the new Customer ID column, which contains a unique value for each customer. Each row in the table represents a unique customer.
Now, referencing the Customer ID values, the transaction data looks like the following:
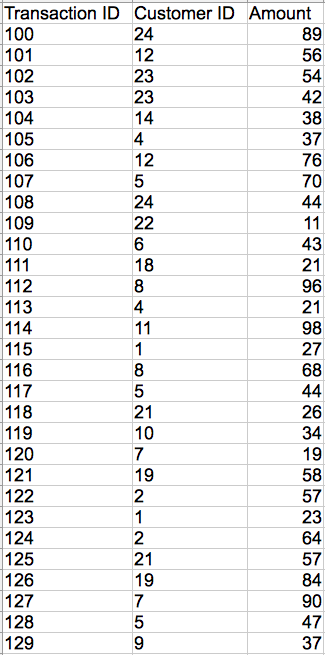
Customer names are no longer referenced in the transactional data. Instead, their IDs are used to refer to the other dataset, where unique values are maintained. These are the references to the connection point data.
In this example, an entire field has been removed from the transaction data.
In CloudConnect, the data model now looks like the following:
This is how this model appears in the Portal:
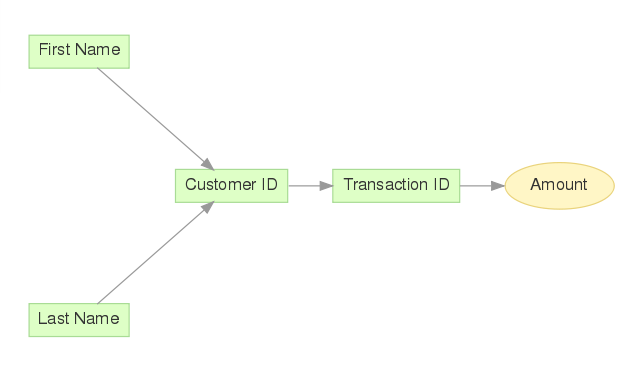
In the above example, you can see how for each transaction (Amount), there is a referenced transaction ID, each of which references a customer ID. From the customer ID, you can derive the First Name and Last Name values in the attribute table.