Defining the Relationship between Datasets in CloudConnect
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
You have defined the two datasets, but there is currently no relationship between them. A relation creates a connection between two datasets.
At the field level, the connection is made between the primary key of one dataset and the foreign key of another dataset. When the connection is made, the foreign key field is created in the new dataset.
Steps:
- With nothing selected in the Model Editor pane, hover the mouse over the Employees dataset. Click and drag the arrow that appears to connect the dataset to the Payments dataset. The relation is created. The logical data model should now look like the following: Now, define a connection point. In the destination of the relation, the connection point defines the unique identifier for a row of data. In this model, the unique identifier of the relationship is the Employee ID field.
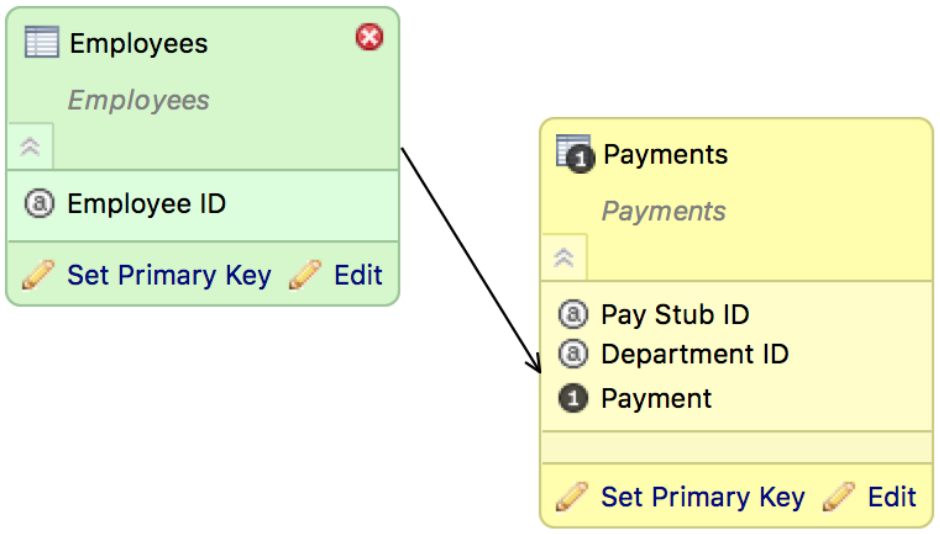
- In the Employees dataset, click Set Primary Key. The Primary key dialog appears.
- Click Connection Point, and select Employee ID from the drop-down.

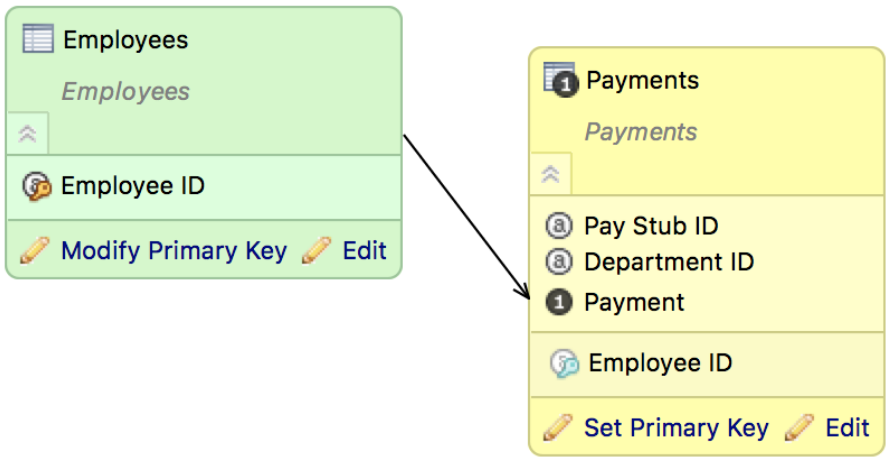
- Click OK. In the LDM Modeler, the connection point is now represented by a Yellow Key icon. Additionally, you can see that a reference to Employee ID has been added to the Payments dataset, identified by a Blue Key icon. This reference indicates that Employee ID is a foreign key in the dataset, with the Employee ID values in the Employees dataset as the key values.
Connection Points and Data Loading
The Payments dataset is not referenced from any other dataset; it is the base set of transactions. Since no other dataset references it, the dataset does not require a connection point to preserve the logical relationship. During incremental data loads, a connection point for Pay Stub ID becomes useful:
- If there is no connection point and two records have the same field values, the second record appends the first record. Both payments are stored in the data, and any metrics based off of these records are miscalculated.
- If a connection point is defined for Pay Stub ID, a second record with the same identifier replaces the original record. It is not appended, and the last record with the same connection point is the one that is stored. In this manner, uniqueness within the values for the identifier is preserved.
Define the Pay Stub ID field as the connection point for the Payments dataset.
Steps:
- Select the Payments dataset.
- Click Set Primary Key. The Primary key dialog appears.
- Click Connection Point, and select Pay Stub ID from the drop-down.

- Click OK.