Optimizing Data Models for Better Performance
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
Project performance, meaning the time required to render reports and dashboards, hinges on the design of the logical data model and metric complexity. Following the best practices described in this article, you will be able avoid the pitfalls most often responsible for performance degradation. This article will also discuss how to use the new LDM Designer in CloudConnect to apply the necessary model changes.
Usual Suspects
Large tables Size is determined by both column and row count How to check: Create a simple metric counting rows in your data set [SELECT COUNT (connection point attribute)]. Use this metric in a report and apply random filters (this will prevent cache hits). If this trivial report exceeds reasonable runtimes, find a way to reduce the table size.
Table joins Joining one or more large data sets adds to query complexity How to check: Create a simple metric counting rows in your data set [Select Count (connection_point_attribute)]. Use this metric in a two reports, one sliced by an attribute from the same data set and one sliced by an attribute from the joined data set. If the runtime of the report that requires the join is significantly longer than the one without, investigate methods for eliminating the join.
Multi-query reports Reports that display metrics computed from independent data sets require multiple queries How to check: Create a report with two metrics based on facts in different data sets and slice by a shared attribute. Measure the report load time with both metrics and then rerun the report with only one of the metrics. If the report including both metrics requires a significantly longer run-time, try splitting metrics across multiple reports.
Rollups A unique subtotal type that requires re-computation of queries based on report attribute values How to check: Identify a report that utilizes Rollups as a subtotal type and requires excessive runtime. Run the report with no Rollup to determine if runtime is reduced.
Best Practices
Reduce Data Volume Change the table granularity by aggregating over time periods or over attributes. Table size is dependent on column and row count, so minimize size by excluding unnecessary fields or utilizing attribute labels, i.e. UserName for UserID. Volume reduction in fact tables is also possible by storing data for only a specific time period, i.e. the last 6 months or past year.
Minimize Joins by Denormalizing Queries suffer performance penalties as a result of table joins. Furthermore, these penalties correlate with table size so the larger the tables, the longer the queries take to run. Denormalize, meaning merge related fields into the same data set, to expedite query execution.
Simplify Reports Multiple Queries Reports designed to display multiple metrics calculated from different data sets will require multiple table scans. If report rendering times exceed desired times, troubleshoot by splitting the metrics into separate reports and running separately. Similarly, applying attribute filters to metrics calculated from different data sets will require multiple table scans.
Rollups Subtotal computations demand little with one exception, the Rollup. Other subtotal functions like average, sum, and minimum can be computed from a single query; however, rollups, which are typically used for non-additive facts, require recomputing metrics at the attribute level. This added complexity can require additional table scans and decrease rendering speeds.
Using the LDM Modeler
If you already use GoodData for your reporting needs and want to update your existing data model, Release 87 of CloudConnect provided this functionality. To perform edits, follow this protocol:
Enter project in CloudConnect
Create new logical data model
- Import data model from existing GoodData project
Click and drag attributes/facts to move between data sets Ex: Moving Fact 2 from Data Set 1 to Data Set 2
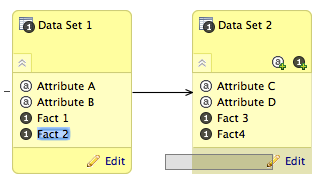
Add or remove facts, attributes, data sets or dates
Select Publish model to server Ex: Fact 2 Moved from Data Set 1 to Data Set 2 and Attribute E added to Data Set 2
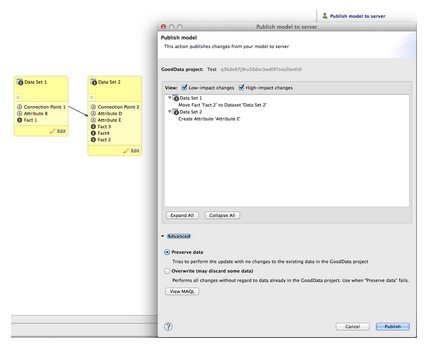
- Review changes Low Impact - Non-destructive changes, typically additions or name changes High Impact - Model alterations that affect referential integrity or are destructive
Advanced:
Preserve DataPerforms updates without changing the project’s existing data.
Overwrite Updates model without regarding data. Data discarded as needed.