You are viewing our older product's guide. Click here for the documentation of GoodData Cloud, our latest and most advanced product.
Choosing a Primary Attribute Identifier in Your ETL Graph
In CloudConnect Designer, when you perform field mappings from the metadata of your GD Dataset Writer component, you may be required to select the primary identifier of some attributes. This identifier is a label of the attribute.
CloudConnect is a legacy tool and will be discontinued. We recommend that to prepare your data you use the GoodData data pipeline as described in Data Preparation and Distribution. For data modeling, see Data Modeling in GoodData to learn how to work with Logical Data Modeler.
This article describes how to manage these changes through the Choose a primary identifier of the following attributes dialog in the GD Dataset Writer for the following cases:
- You have one dataset
- You have two more datasets connected through a connection point.
Before you begin, please check your data for the primary and foreign keys. These keys must be used as the primary identification, which functions like a primary key; it stores only unique values. More information is provided below.
Case 1: One Dataset
Example Model
Here is a simple example, which contains a single dataset.
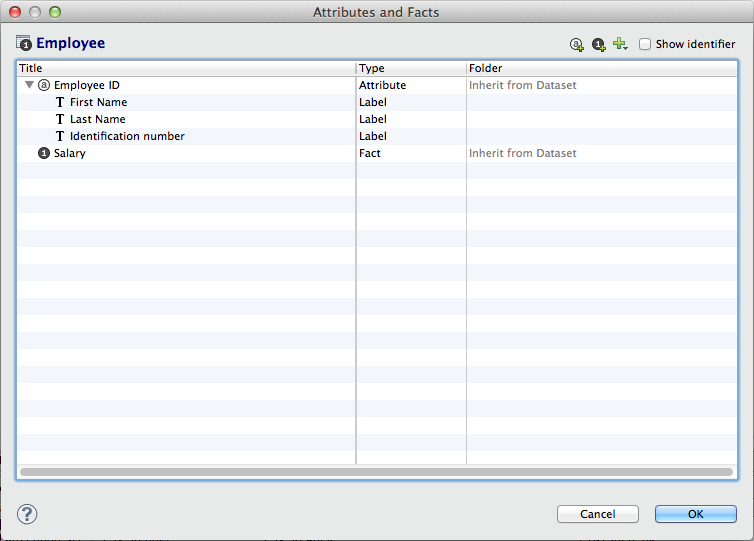
This dataset contains the following fields. Note that the Employee ID attribute contains three attribute labels:
- First Name
- Last Name
- Identification number.
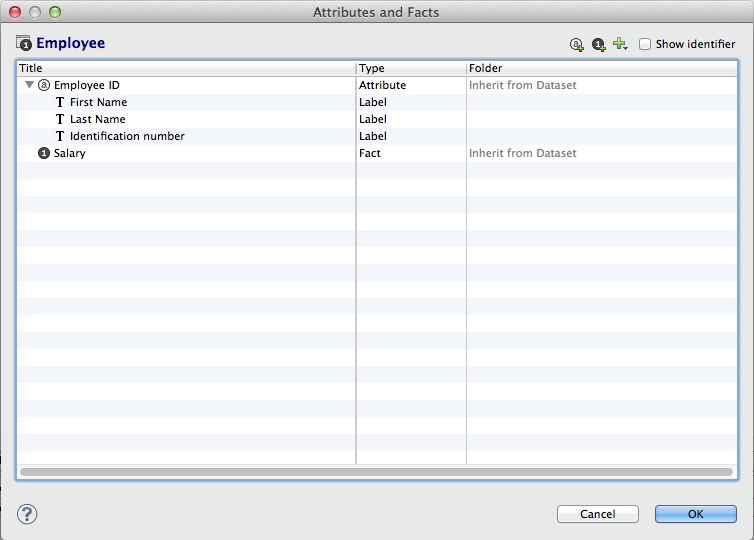
Here is some sample data in a CSV file:
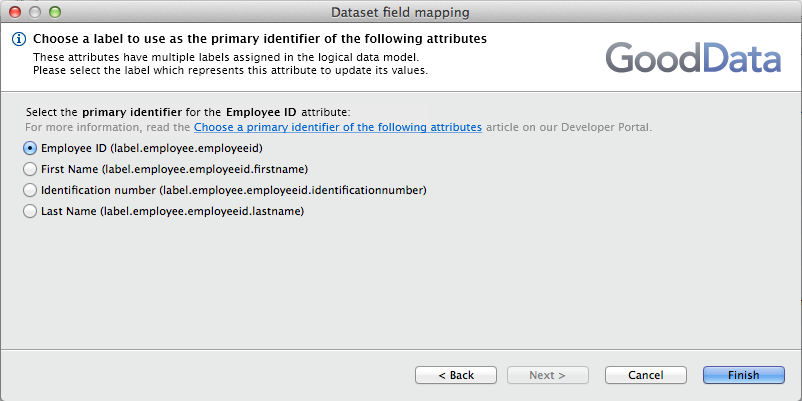
ETL Designer - mapping fields in GD Dataset Writer
When you are mapping fields in GD Dataset Writer, the following dialog appears. Select the primary attribute label, which describes the Employee ID attribute.
Behavior variations
Depending on the field that you select, the behavior varies. In the following examples, a simple report was created to sum salary values for the Employee ID attribute, the label of which was changed in each of the following reports.
1. Select Employee ID (label.employee.employeeid) as the primary identifier
Secondary-click the Employee ID column to change the attribute label.
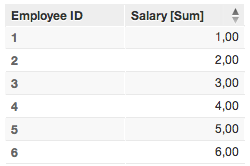
Primary identifier = Employee ID*
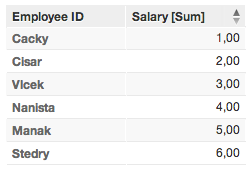
Primary identifier = Last Name
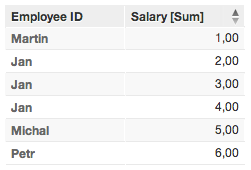
Primary identifier = First Name
2. Select First name (label.employee.employeeid.firstname) as the primary identifier
Secondary-click the Employee ID column to change the attribute label.
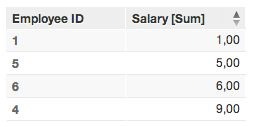
Primary identifier = Employee ID
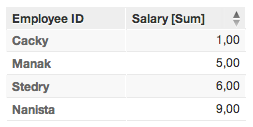
Primary identifier = First Name
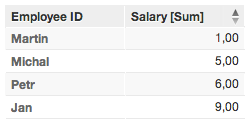
Primary identifier = Last Name
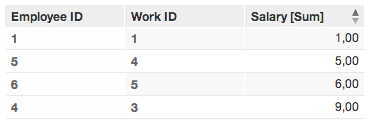
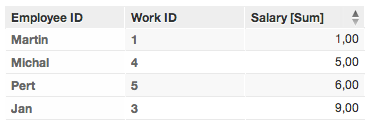
In Example 2, only four rows are displayed. The primary identifier is retrieving only the unique values, storing only the last data associated with each value. These facts are summed together in the displayed metric.
The primary identifier behaves like a primary key; it stores only the unique values and store only the last one.
For example, in the source data, there are three rows in which the value for First Name is “Jan”. In the generated report, their salaries are summed together and displayed in a single row as a unique value.
This behavior is consistent whenever you select the primary identifier and have repetitive values in multiple rows.
Case 2: Two Datasets
Example Model
In this example, two datasets are connected through a connection point:
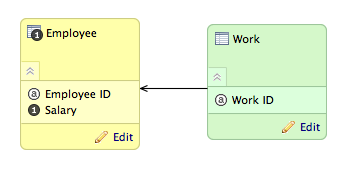
In this example, you must map the fields for both datasets. Since they are connected through a connection point, you must specify in the Employee dataset the foreign key-like reference in the Work dataset.
The field-level information on these datasets is displayed below.
Field mapping for Employee dataset
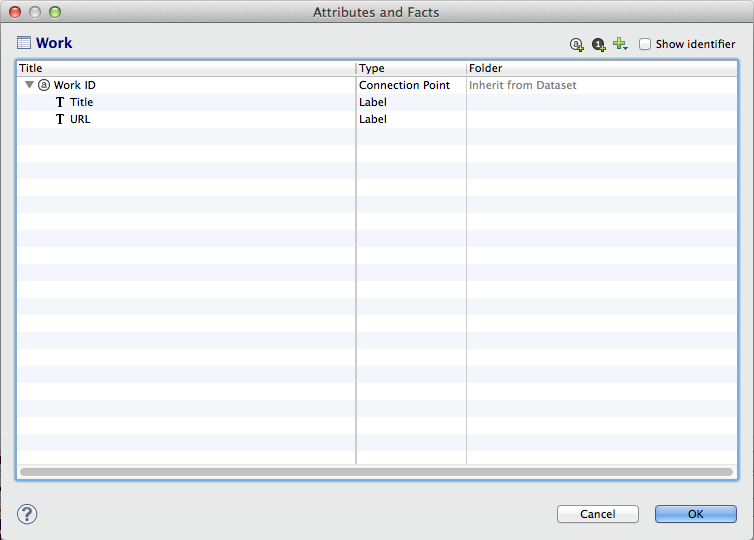
Field mapping for Work dataset
CSV files
Example data for each dataset is listed below.
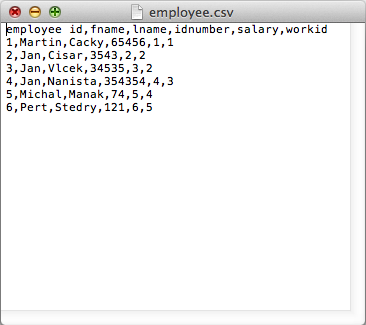
employee.csv
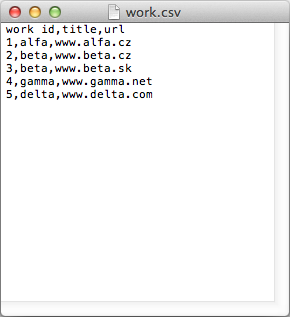
work.csv
ETL Designer - mapping fields in GD Dataset Writer
When you are mapping fields in the GD Dataset Writer, the following Employee Dataset Writer dialog window appears for each dataset.
Employee Dataset Writer
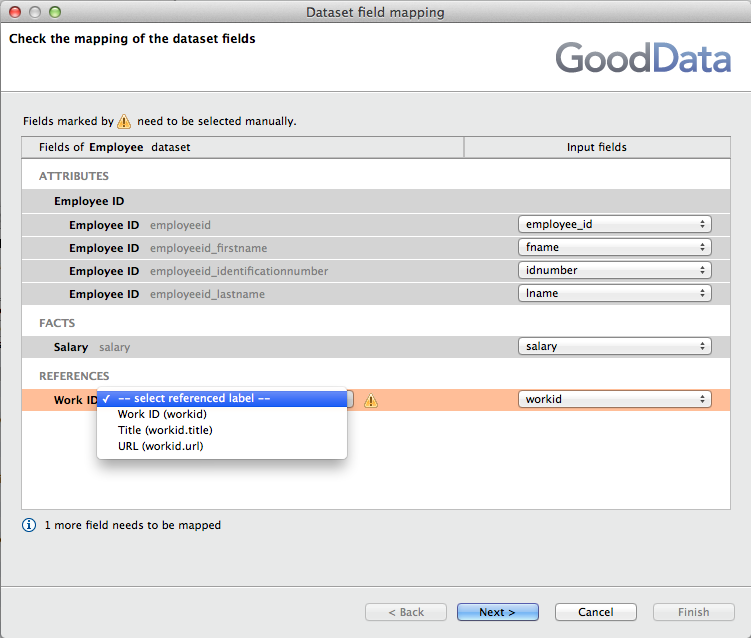
Field mapping dialog - Select the foreign key (the primary key is the Work ID connection point in the Work dataset)
For the Employee dataset, the Work ID functions like the foreign key for the dataset, since it is the connection point for the Work dataset.
Select the referenced label (foreign key) and the primary identifier of the Employee ID attribute:
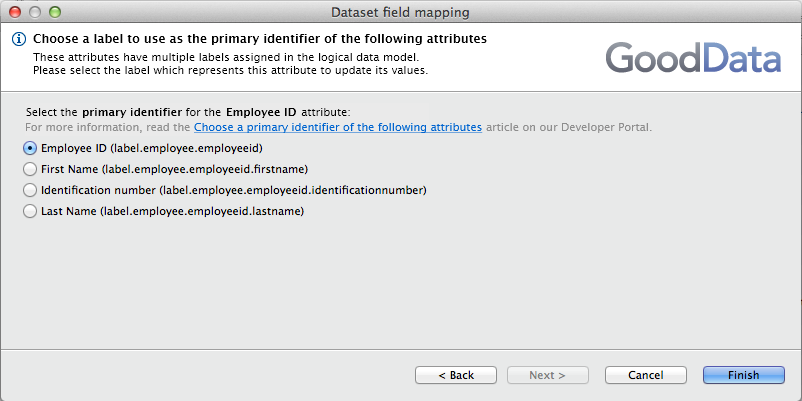
Selecting the referenced label and the primary key
Then, you must select the label that identifies the attribute.
Work Dataset Writer
For the Work dataset, you must identify the primary attribute label.
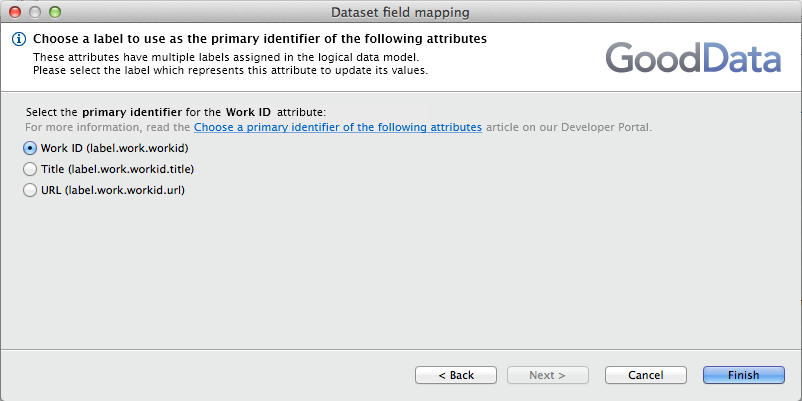
Field mapping - primary attribute label
You must select the label that identifies the attribute.
Behavior variations
Depending on the field you select, the behavior varies when data is uploaded to the GoodData platform.
1. Select Employee ID (label.employee.employeeid) as the primary identifier in Employee dataset
Behaviors are the same as in the first case. See above.
2. Select First name (label.employee.employeeid.firstname) as the primary identifier in Employee dataset
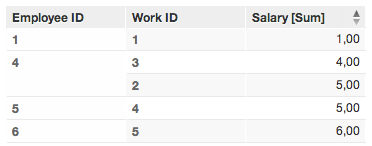
Work dataset with Employee ID
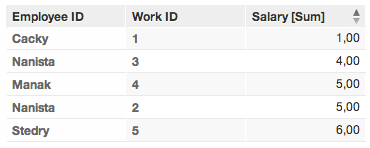
Work dataset with First Name
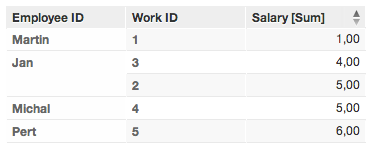
Work dataset with Last Name
Here again, values are summed based on unique values for the label identifying the first name. So, due to the multiple instances of “Jan,” the reported value is the sum of all salaries for all instances of Jan.
3. Select First name (label.employee.employeeid.firstname) as the primary identifier in Employee dataset and Title (label.work.workid.title) as the primary identifier in Work Dataset (and also in Employee dataset writer as a reference)
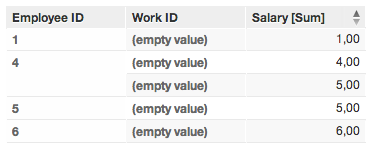
(empty value) generated by using Work ID as primary key and foreign key
The (empty value) for the Work ID is generated because the field Work ID is used as the connection point (primary key and reference key).
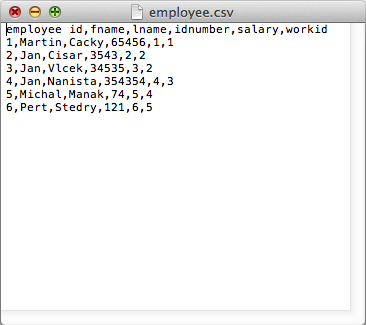
employee.csv
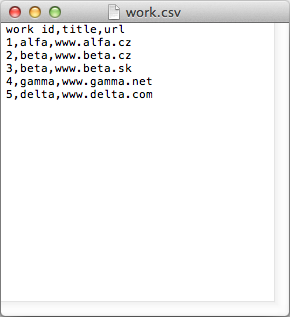
work.csv
To correct this use case, you must change the employee.csv. The worktitle column has been added, as a reference to the person’s job Title.
employee.csv with worktitle column
When the above CSVs are reloaded, the following values are displayed in your reports:
Employee dataset with Work ID = worktitle
Employee dataset with Work ID = First Name

Employee dataset with Work ID = Last Name
What It Means
Example 1
Work and employee are now connected through the primary key, Work ID. In this example, the work ID is represented directly by the work id attribute.
Employee.csv
employee id,fname,lname,idnumber,salary,workid 1,Martin,Cacky,65456,1,1 2,Jan,Cisar,3543,2,2 3,Jan,Vlcek,34535,3,2 4,Jan,Nanista,354354,4,3 5,Michal,Manak,74,5,4 6,Pert,Stedry,121,6,5
Work.csv
work id,title,url 1,alfa,www.alfa.cz 2,beta,www.beta.cz 3,beta,www.beta.sk 4,gamma,www.gamma.net 5,delta,www.delta.com
When performing the mapping in the GD Dataset Writer component, you must choose “Work ID” as the primary identifier:
Field mapping Work ID in Work dataset
Select the same name in the field mapping dialog for the Employee dataset:
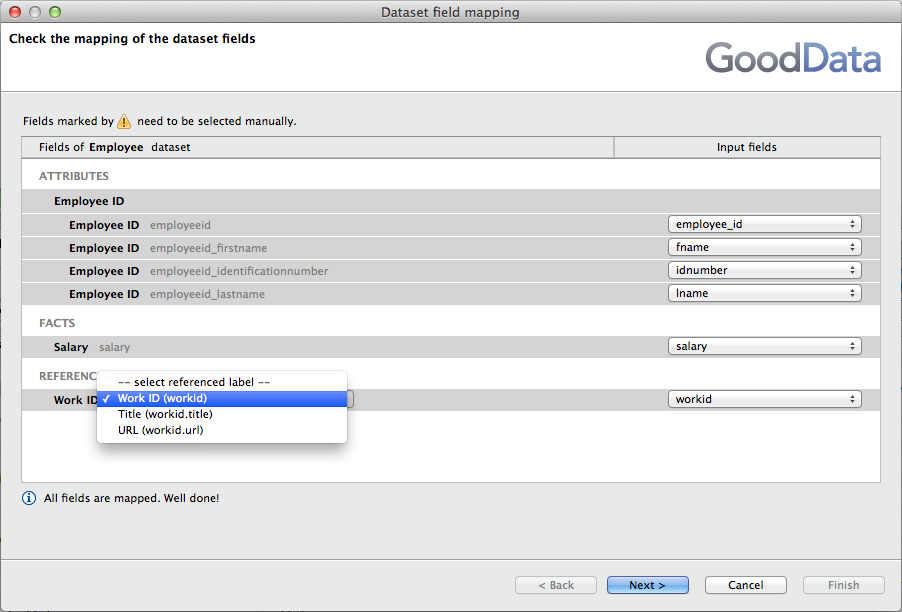
Mapping Work ID in Employee dataset
Example 2
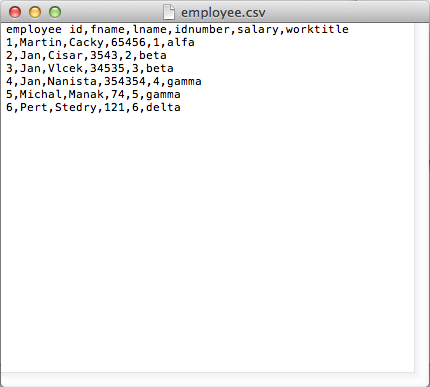
Work.csv and Employee.csv are connected through primary key workid. In this example, this primary key is identified as the title of the work.
Employee.csv
employee id,fname,lname,idnumber,salary,workid 1,Martin,Cacky,65456,1,alfa 2,Jan,Cisar,3543,2,beta 3,Jan,Vlcek,34535,3,beta 4,Jan,Nanista,354354,4,beta 5,Michal,Manak,74,5,gamma 6,Pert,Stedry,121,6,delta
Work.csv
work id,title,url 1,alfa,www.alfa.cz 2,beta,www.beta.cz 3,beta,www.beta.sk 4,gamma,www.gamma.net 5,delta,www.delta.com
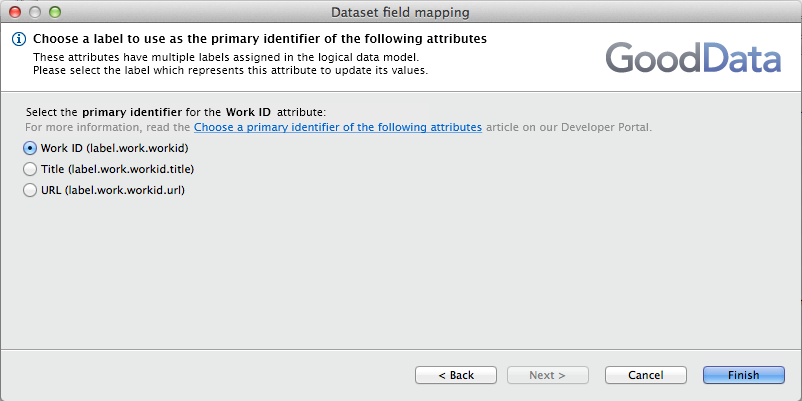
Choose “Title” as the primary identifier:
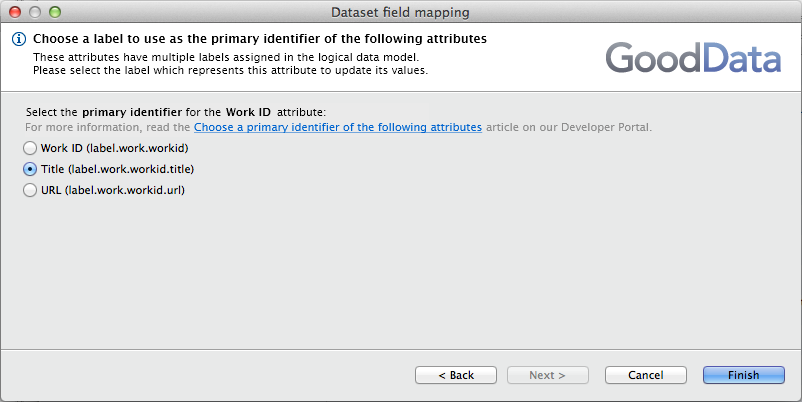
Choose primary identifier for Work ID in Work dataset
Also, select the same name in the field mapping dialog for the Employee dataset:
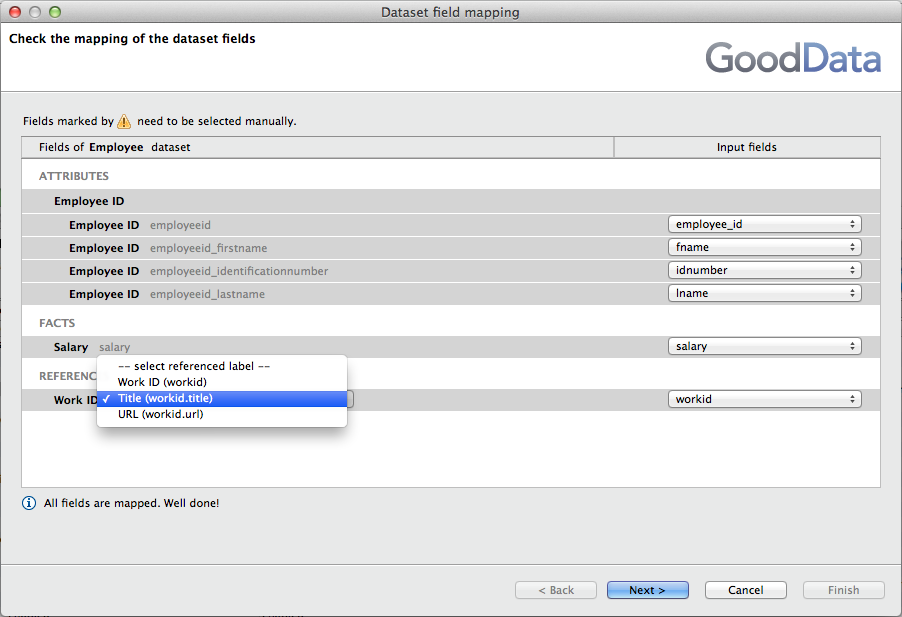
Select field mapping for Work ID reference in Employee dataset
This reference in the Employee dataset must be the same as in the Work dataset. Otherwise, your data will not be connected together and (empty values) are displayed.
Conclusion
- Be careful while mapping fields in GD Dataset Writer.
- Remember to have some attributes with at least one attached label.
- Before selecting the primary identifier, check your source data to verify the values for primary and foreign keys.
In some future release, this feature will be included in the LDM Modeler.