Using BY Clause to Lock Aggregation
The BY clause is a flexible tool for creating interesting combinations within your reports. This tutorial briefly explains the BY and provides some useful examples of how to use it to lock the aggregation level in your metric calculations.
Implicit BY clause
Already, you are effectively using a BY clause. Suppose your project contains the # Tickets metric, which counts the number of unique Ticket IDs contained in the project. When this metric is broken down by the Month/Year (Created) attribute, you can see the number of tickets created by month:
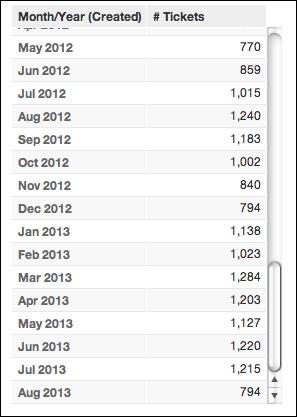
Suppose you now add the Date (Created) metric. The # Tickets metric in the report has been broken down by BY Month/Year (Created) and then further broken down BY Date (Created):
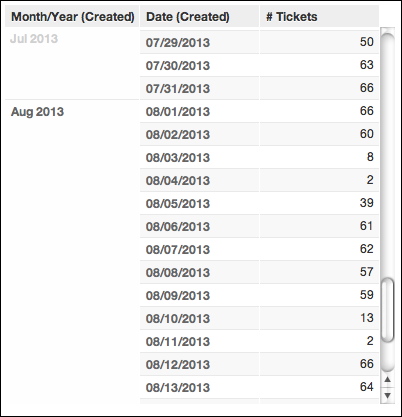
When attributes are added to a report in the How pane, the metrics are being broken down by something.
Locking aggregation levels
The above method of slicing applies the current attribute context to each cell. Any cell in the above defined report contains # Tickets by the specified date. You cannot reference or use in this metric’s computations at, for example, the monthly level.
In some cases, you may want to use a metric value “locked” at a certain aggregation level, so that wherever you reference the expression, a value with context outside the current cell is displayed. This locking is accomplished using the BY clause in MAQL.
The BY clause enables locking the level of aggregation for computing a metric.
In the Custom Metric Editor, create the following # Tickets by Month metric:
SELECT # Tickets BY Month/Year (Created)
Save the metric and add it to the report. Notice the difference between the normal # Tickets metric and my new # Tickets By Month metric:
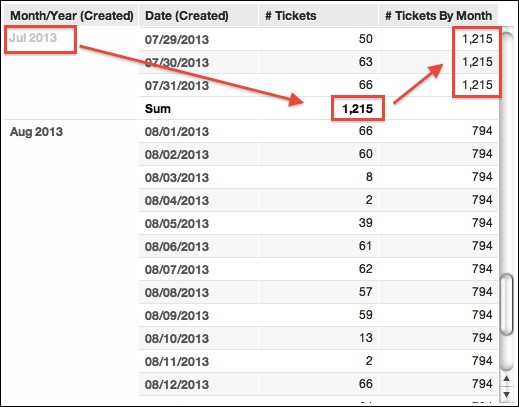
This method locks in the aggregation at the month level, even though the report is sliced by individual date.
Use case: percentages
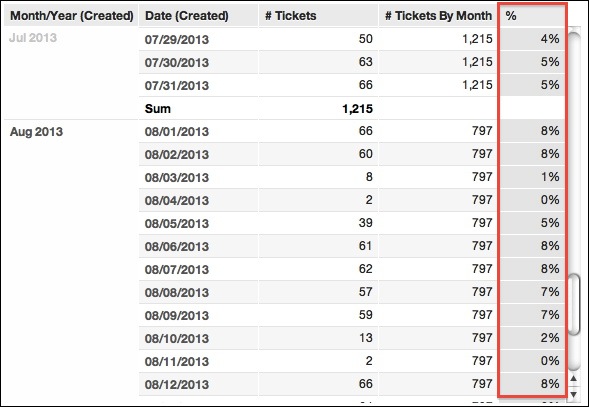
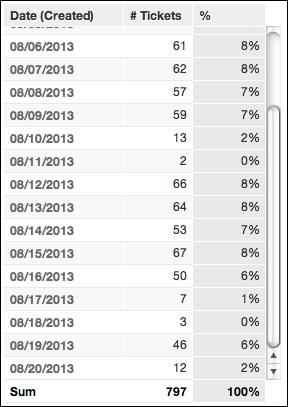
An immediate use for this aggregation locking is calculating percentages of the day against the monthly total. This report can be extended with the following metric, called %:
SELECT # Tickets / # Tickets By Month
When the new metric is added to the report, you can see the new column containing valuable information on ticket creation throughout the month, showing areas of peak activity, which can be correlated with other enterprise activities:
Locking in looser hierarchies
The preceding example works very well because Date (Created) and Month/Year (Created) are in a strict, logical hierarchy; a single date can fall in one and only one month. Other hierarchies are not so clean.
Suppose you need to extend the report to measure tickets by individual within a group. However, each value in the Assignee attribute may belong to one or more Group attribute values, which means that the structure is not a strict hierarchy. To address this issue, an additional clause is introduced into the % metric.
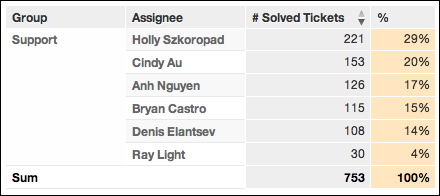
Suppose you create a new report to measure # Solved Tickets, which is sliced by individual assignee (Assignee attribute) and by group (Group attribute). Within the Support group, the report should look similar to the following, with a SUM added to the bottom to indicate the total number of tickets solved by the Support group:
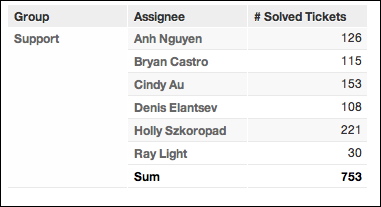
From the sum at the bottom of this report, all Agents solved 753 tickets. To compute the percentage solved by each agent, you must divide the solved ticket number for each agent by the total for the whole group. Based on the previous example, you might create a metric in which the number of tickets is sliced simply by Group, such as: SELECT # Solved Tickets BY Group.
However, this metric won’t work. Since Assignee and Group are not in a strict hierarchy, where one Assignee can belong to only one Group, you create double-counting across groups. Suppose Ray Light also belongs to the Services group. His 30 solved tickets would be reported in both the Support and the Services group, resulting in inaccurate totals.
The BY Group portion of the metric is being sliced by Assignee. Since Assignee is not part of a strict hierarchy in the project’s data model, the application attempts to slice by both attributes.
To keep aggregation only at the Group level, you must amend this BY clause to look at Group only, ignoring the Assignee attribute. The resulting metric looks like the following:
SELECT # Solved Tickets BY Group, ALL OTHER
BY ALL OTHER Clause
The BY ALL OTHER clause tells the metric to compute a total number, regardless of how the metric is sliced within the report.
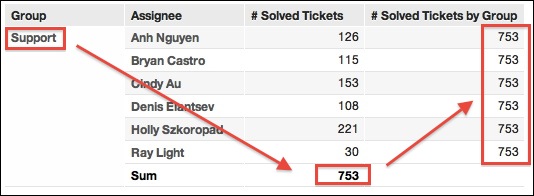
The preceding metric slices by Group, ignoring all other references in the metric (that is Assignee). Since there is no definitive 1:1 relationship between Assignee and Group, there is no true hierarchy like Date and Month. Adding the ALL OTHER term forces aggregation to just the specified attribute. Our resulting report should look like the following:
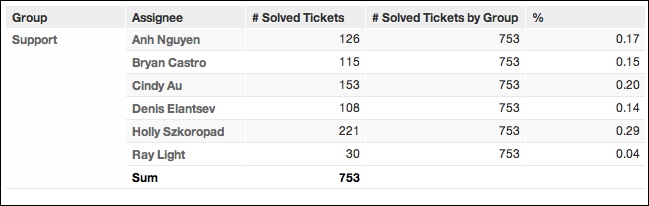
This new metric enables calculation of a true percentage of solved tickets for each individual (the % metric):
SELECT # Solved Tickets / # Solved Tickets by Group
The resulting report looks like the following:
After applying sorting and custom number formatting, you may end with a dashboard-ready report like the following:
Summary - BY Clause
To summarize, we learned two important techniques:
BY <attribute>- Lock the level of aggregation to a specified attribute within a hierarchyBY <attribute>, ALL OTHER- Lock the level of aggregation to a single attribute, regardless of any other attributes displayed in the report. This technique is useful when there is no strict hierarchy (like Dates and Months) but there is still a hierarchical structure (like Assignees and Groups).